| БрМЭЦМі: |
|
ЯТУцЮвУЧЬиБ№ећРэСЫЙигкжЊЪЖЭМЦзЕФММЪѕШЋУцзлЪіЃЌКИЧЛљБОЖЈвхгыМмЙЙЁЂДњБэаджЊЪЖЭМЦзПтЁЂЙЙНЈММЪѕЁЂПЊдДПтКЭЕфаЭгІгУЁЃ
БОЮФРДзХЮЂаХЙЋжкКХЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
в§бд
ЫцзХЛЅСЊЭјЕФЗЂеЙЃЌЭјТчЪ§ОнФкШнГЪЯжБЌеЈЪНдіГЄЕФЬЌЪЦЁЃгЩгкЛЅСЊЭјФкШнЕФДѓЙцФЃЁЂвьжЪЖрдЊЁЂзщжЏНсЙЙЫЩЩЂЕФЬиЕуЃЌИјШЫУЧгааЇЛёШЁаХЯЂКЭжЊЪЖЬсГіСЫЬєеНЁЃжЊЪЖЭМЦзЃЈKnowledge
Graph) вдЦфЧПДѓЕФгявхДІРэФмСІКЭПЊЗХзщжЏФмСІЃЌЮЊЛЅСЊЭјЪБДњЕФжЊЪЖЛЏзщжЏКЭжЧФмгІгУЕьЖЈСЫЛљДЁЁЃзюНќЃЌДѓЙцФЃжЊЪЖЭМЦзПтЕФбаОПКЭгІгУдкбЇЪѕНчКЭЙЄвЕНчв§Ц№СЫзуЙЛЕФзЂвтСІ[1-5]ЁЃвЛИіжЊЪЖЭМЦзжМдкУшЪіЯжЪЕЪРНчжаДцдкЕФЪЕЬхвдМАЪЕЬхжЎМфЕФЙиЯЕЁЃжЊЪЖЭМЦзгк2012Фъ5дТ17ШегЩ[Google]е§ЪНЬсГі[6]ЃЌЦфГѕждЪЧЮЊСЫЬсИпЫбЫїв§ЧцЕФФмСІЃЌИФЩЦгУЛЇЕФЫбЫїжЪСПвдМАЫбЫїЬхбщЁЃЫцзХШЫЙЄжЧФмЕФММЪѕЗЂеЙКЭгІгУЃЌжЊЪЖЭМЦззїЮЊЙиМќММЪѕжЎвЛЃЌвбБЛЙуЗКгІгУгкжЧФмЫбЫїЁЂжЧФмЮЪД№ЁЂИіадЛЏЭЦМіЁЂФкШнЗжЗЂЕШСьгђЁЃ
жЊЪЖЭМЦзЕФЖЈвх
дкЮЌЛљАйПЦЕФЙйЗНДЪЬѕжаЃКжЊЪЖЭМЦзЪЧGoogleгУгкдіЧПЦфЫбЫїв§ЧцЙІФмЕФжЊЪЖПтЁЃБОжЪЩЯ, жЊЪЖЭМЦзжМдкУшЪіецЪЕЪРНчжаДцдкЕФИїжжЪЕЬхЛђИХФюМАЦфЙиЯЕ,ЦфЙЙГЩвЛеХОоДѓЕФгявхЭјТчЭМЃЌНкЕуБэЪОЪЕЬхЛђИХФюЃЌБпдђгЩЪєадЛђЙиЯЕЙЙГЩЁЃЯждкЕФжЊЪЖЭМЦзвбБЛгУРДЗКжИИїжжДѓЙцФЃЕФжЊЪЖПтЁЃ
дкОпЬхНщЩмжЊЪЖЭМЦзЕФЖЈвхЃЌЮвУЧЯШРДПДЯТжЊЪЖРраЭЕФЖЈвхЃК
жЊЪЖЭМЦзжаАќКЌШ§жжНкЕуЃК
ЪЕЬх: жИЕФЪЧОпгаПЩЧјБ№адЧвЖРСЂДцдкЕФФГжжЪТЮяЁЃШчФГвЛИіШЫЁЂФГвЛИіГЧЪаЁЂФГвЛжжжВЮяЕШЁЂФГвЛжжЩЬЦЗЕШЕШЁЃЪРНчЭђЮягаОпЬхЪТЮязщГЩЃЌДЫжИЪЕЬхЁЃШчЭМ1ЕФЁАжаЙњЁБЁЂЁАУРЙњЁБЁЂЁАШеБОЁБЕШЁЃЃЌЪЕЬхЪЧжЊЪЖЭМЦзжаЕФзюЛљБОдЊЫиЃЌВЛЭЌЕФЪЕЬхМфДцдкВЛЭЌЕФЙиЯЕЁЃ
гявхРрЃЈИХФюЃЉЃКОпгаЭЌжжЬиадЕФЪЕЬхЙЙГЩЕФМЏКЯЃЌШчЙњМвЁЂУёзхЁЂЪщМЎЁЂЕчФдЕШЁЃ ИХФюжївЊжИМЏКЯЁЂРрБ№ЁЂЖдЯѓРраЭЁЂЪТЮяЕФжжРрЃЌР§ШчШЫЮяЁЂЕиРэЕШЁЃ
ФкШн: ЭЈГЃзїЮЊЪЕЬхКЭгявхРрЕФУћзжЁЂУшЪіЁЂНтЪЭЕШЃЌПЩвдгЩЮФБОЁЂЭМЯёЁЂвєЪгЦЕЕШРДБэДяЁЃ
Ъєад(жЕ): ДгвЛИіЪЕЬхжИЯђЫќЕФЪєаджЕЁЃВЛЭЌЕФЪєадРраЭЖдгІгкВЛЭЌРраЭЪєадЕФБпЁЃЪєаджЕжївЊжИЖдЯѓжИЖЈЪєадЕФжЕЁЃШчЭМ1ЫљЪОЕФЁАУцЛ§ЁБЁЂЁАШЫПкЁБЁЂЁАЪзЖМЁБЪЧМИжжВЛЭЌЕФЪєадЁЃЪєаджЕжївЊжИЖдЯѓжИЖЈЪєадЕФжЕЃЌР§Шч960ЭђЦНЗНЙЋРяЕШЁЃ
ЙиЯЕ: аЮЪНЛЏЮЊвЛИіКЏЪ§ЃЌЫќАбkkИіЕугГЩфЕНвЛИіВМЖћжЕЁЃдкжЊЪЖЭМЦзЩЯЃЌЙиЯЕдђЪЧвЛИіАбkkИіЭМНкЕу(ЪЕЬхЁЂгявхРрЁЂЪєаджЕ)гГЩфЕНВМЖћжЕЕФКЏЪ§ЁЃ
ЛљгкЩЯЪіЖЈвхЁЃЛљгкШ§дЊзщЪЧжЊЪЖЭМЦзЕФвЛжжЭЈгУБэЪОЗНЪНЃЌМД,ЦфжаЃЌЪЧжЊЪЖПтжаЕФЪЕЬхМЏКЯЃЌЙВАќКЌ|E|жжВЛЭЌЪЕЬхЃЛ
ЪЧжЊЪЖПтжаЕФЙиЯЕМЏКЯЃЌЙВАќКЌ|R|жжВЛЭЌЙиЯЕЃЛДњБэжЊЪЖПтжаЕФШ§дЊзщМЏКЯЁЃШ§дЊзщЕФЛљБОаЮЪНжївЊАќРЈ(ЪЕЬх1-ЙиЯЕ-ЪЕЬх2)КЭ(ЪЕЬх-Ъєад-ЪєаджЕ)ЕШЁЃУПИіЪЕЬх(ИХФюЕФЭтбг)ПЩгУвЛИіШЋОжЮЈвЛШЗЖЈЕФIDРДБъЪЖЃЌУПИіЪєад-ЪєаджЕЖд(attribute-value
pairЃЌAVP)ПЩгУРДПЬЛЪЕЬхЕФФкдкЬиадЃЌЖјЙиЯЕПЩгУРДСЌНгСНИіЪЕЬхЃЌПЬЛЫќУЧжЎМфЕФЙиСЊЁЃШчЯТЭМ1ЕФжЊЪЖЭМЦзР§згЫљЪОЃЌжаЙњЪЧвЛИіЪЕЬхЃЌББОЉЪЧвЛИіЪЕЬхЃЌжаЙњ-ЪзЖМ-ББОЉ
ЪЧвЛИіЃЈЪЕЬх-ЙиЯЕ-ЪЕЬхЃЉЕФШ§дЊзщбљР§ББОЉЪЧвЛИіЪЕЬх ЃЌШЫПкЪЧвЛжжЪєад2069.3ЭђЪЧЪєаджЕЁЃББОЉ-ШЫПк-2069.3ЭђЙЙГЩвЛИіЃЈЪЕЬх-Ъєад-ЪєаджЕЃЉЕФШ§дЊзщбљР§ЁЃ

ЭМ1 жЊЪЖЭМЦзЪОР§
жЊЪЖЭМЦзЕФМмЙЙ
жЊЪЖЭМЦзЕФМмЙЙАќРЈздЩэЕФТпМНсЙЙвдМАЙЙНЈжЊЪЖЭМЦзЫљВЩгУЕФММЪѕЃЈЬхЯЕЃЉМмЙЙЁЃ
1ЃЉ жЊЪЖЭМЦзЕФТпМНсЙЙ
жЊЪЖЭМЦздкТпМЩЯПЩЗжЮЊФЃЪНВугыЪ§ОнВуСНИіВуДЮЃЌЪ§ОнВужївЊЪЧгЩвЛЯЕСаЕФЪТЪЕзщГЩЃЌЖјжЊЪЖНЋвдЪТЪЕЮЊЕЅЮЛНјааДцДЂЁЃШчЙћгУ(ЪЕЬх1ЃЌЙиЯЕЃЌЪЕЬх2)ЁЂ(ЪЕЬхЁЂЪєадЃЌЪєаджЕ)етбљЕФШ§дЊзщРДБэДяЪТЪЕЃЌПЩбЁдёЭМЪ§ОнПтзїЮЊДцДЂНщжЪЃЌР§ШчПЊдДЕФNeo4j[7]ЁЂTwitterЕФFlockDB[8]ЁЂsonesЕФGraphDB[9]ЕШЁЃФЃЪНВуЙЙНЈдкЪ§ОнВужЎЩЯЃЌЪЧжЊЪЖЭМЦзЕФКЫаФЃЌЭЈГЃВЩгУБОЬхПтРДЙмРэжЊЪЖЭМЦзЕФФЃЪНВуЁЃБОЬхЪЧНсЙЙЛЏжЊЪЖПтЕФИХФюФЃАхЃЌЭЈЙ§БОЬхПтЖјаЮГЩЕФжЊЪЖПтВЛНіВуДЮНсЙЙНЯЧПЃЌВЂЧвШпгрГЬЖШНЯаЁЁЃ
2ЃЉ жЊЪЖЭМЦзЕФЬхЯЕМмЙЙ

ЭМ2 жЊЪЖЭМЦзЕФММЪѕМмЙЙ
жЊЪЖЭМЦзЕФЬхЯЕМмЙЙЪЧЦфжИЙЙНЈФЃЪННсЙЙЃЌШчЭМ2ЫљЪОЁЃЦфжаащЯпПђФкЕФВПЗжЮЊжЊЪЖЭМЦзЕФЙЙНЈЙ§ГЬЃЌвВАќКЌжЊЪЖЭМЦзЕФИќаТЙ§ГЬЁЃжЊЪЖЭМЦзЙЙНЈДгзюдЪМЕФЪ§ОнЃЈАќРЈНсЙЙЛЏЁЂАыНсЙЙЛЏЁЂЗЧНсЙЙЛЏЪ§ОнЃЉГіЗЂЃЌВЩгУвЛЯЕСаздЖЏЛђепАыздЖЏЕФММЪѕЪжЖЮЃЌДгдЪМЪ§ОнПтКЭЕкШ§ЗНЪ§ОнПтжаЬсШЁжЊЪЖЪТЪЕЃЌВЂНЋЦфДцШыжЊЪЖПтЕФЪ§ОнВуКЭФЃЪНВуЃЌетвЛЙ§ГЬАќКЌЃКаХЯЂГщШЁЁЂжЊЪЖБэЪОЁЂжЊЪЖШкКЯЁЂжЊЪЖЭЦРэЫФИіЙ§ГЬЃЌУПвЛДЮИќаТЕќДњОљАќКЌетЫФИіНзЖЮЁЃжЊЪЖЭМЦзжївЊгаздЖЅЯђЯТ(top-down)гыздЕзЯђЩЯ(bottom-up)СНжжЙЙНЈЗНЪНЁЃздЖЅЯђЯТжИЕФЪЧЯШЮЊжЊЪЖЭМЦзЖЈвхКУБОЬхгыЪ§ОнФЃЪНЃЌдйНЋЪЕЬхМгШыЕНжЊЪЖПтЁЃИУЙЙНЈЗНЪНашвЊРћгУвЛаЉЯжгаЕФНсЙЙЛЏжЊЪЖПтзїЮЊЦфЛљДЁжЊЪЖПтЃЌР§ШчFreebaseЯюФПОЭЪЧВЩгУетжжЗНЪНЃЌЫќЕФОјДѓВПЗжЪ§ОнЪЧДгЮЌЛљАйПЦжаЕУЕНЕФЁЃздЕзЯђЩЯжИЕФЪЧДгвЛаЉПЊЗХСДНгЪ§ОнжаЬсШЁГіЪЕЬхЃЌбЁдёЦфжажУаХЖШНЯИпЕФМгШыЕНжЊЪЖПтЃЌдйЙЙНЈЖЅВуЕФБОЬхФЃЪН[10]ЁЃФПЧАЃЌДѓЖрЪ§жЊЪЖЭМЦзЖМВЩгУздЕзЯђЩЯЕФЗНЪННјааЙЙНЈЃЌЦфжазюЕфаЭОЭЪЧGoogleЕФKnowledge
Vault[11]КЭЮЂШэЕФSatoriжЊЪЖПтЁЃЯждквВЗћКЯЛЅСЊЭјЪ§ОнФкШнжЊЪЖВњЩњЕФЬиЕуЁЃ
ДњБэаджЊЪЖЭМЦзПт
ИљОнИВИЧЗЖЮЇЖјбдЃЌжЊЪЖЭМЦзвВПЩЗжЮЊПЊЗХгђЭЈгУжЊЪЖЭМЦзКЭДЙжБаавЕжЊЪЖЭМЦз[12]ЁЃПЊЗХЭЈгУжЊЪЖЭМЦззЂжиЙуЖШЃЌЧПЕїШкКЯИќЖрЕФЪЕЬхЃЌНЯДЙжБаавЕжЊЪЖЭМЦзЖјбдЃЌЦфзМШЗЖШВЛЙЛИпЃЌВЂЧвЪмИХФюЗЖЮЇЕФгАЯьЃЌКмФбНшжњБОЬхПтЖдЙЋРэЁЂЙцдђвдМАдМЪјЬѕМўЕФжЇГжФмСІЙцЗЖЦфЪЕЬхЁЂЪєадЁЂЪЕЬхМфЕФЙиЯЕЕШЁЃЭЈгУжЊЪЖЭМЦзжївЊгІгУгкжЧФмЫбЫїЕШСьгђЁЃаавЕжЊЪЖЭМЦзЭЈГЃашвЊвРППЬиЖЈаавЕЕФЪ§ОнРДЙЙНЈЃЌОпгаЬиЖЈЕФаавЕвтвхЁЃаавЕжЊЪЖЭМЦзжаЃЌЪЕЬхЕФЪєадгыЪ§ОнФЃЪНЭљЭљБШНЯЗсИЛЃЌашвЊПМТЧЕНВЛЭЌЕФвЕЮёГЁОАгыЪЙгУШЫдБЁЃЯТЭМеЙЪОСЫЯждкжЊУћЖШНЯИпЕФДѓЙцФЃжЊЪЖПтЁЃ

ЭМ3 ДњБэаджЊЪЖЭМЦзПтИХРР
жЊЪЖЭМЦзЙЙНЈЕФЙиМќММЪѕ
ДѓЙцФЃжЊЪЖПтЕФЙЙНЈгыгІгУашвЊЖржжММЪѕЕФжЇГжЁЃЭЈЙ§жЊЪЖЬсШЁММЪѕЃЌПЩвдДгвЛаЉЙЋПЊЕФАыНсЙЙЛЏЁЂЗЧНсЙЙЛЏКЭЕкШ§ЗННсЙЙЛЏЪ§ОнПтЕФЪ§ОнжаЬсШЁГіЪЕЬхЁЂЙиЯЕЁЂЪєадЕШжЊЪЖвЊЫиЁЃжЊЪЖБэЪОдђЭЈЙ§вЛЖЈгааЇЪжЖЮЖджЊЪЖвЊЫиБэЪОЃЌБугкНјвЛВНДІРэЪЙгУЁЃШЛКѓЭЈЙ§жЊЪЖШкКЯЃЌПЩЯћГ§ЪЕЬхЁЂЙиЯЕЁЂЪєадЕШжИГЦЯюгыЪТЪЕЖдЯѓжЎМфЕФЦчвхЃЌаЮГЩИпжЪСПЕФжЊЪЖПтЁЃжЊЪЖЭЦРэдђЪЧдквбгаЕФжЊЪЖПтЛљДЁЩЯНјвЛВНЭкОђвўКЌЕФжЊЪЖЃЌДгЖјЗсИЛЁЂРЉеЙжЊЪЖПтЁЃЗжВМЪНЕФжЊЪЖБэЪОаЮГЩЕФзлКЯЯђСПЖджЊЪЖПтЕФЙЙНЈЁЂЭЦРэЁЂШкКЯвдМАгІгУОљОпгаживЊЕФвтвхЁЃНгЯТРДЃЌБОЮФНЋвджЊЪЖГщШЁЁЂжЊЪЖБэЪОЁЂжЊЪЖШкКЯвдМАжЊЪЖЭЦРэММЪѕЮЊжиЕуЃЌбЁШЁДњБэадЕФЗНЗЈЃЌЫЕУїЦфжаЕФЯрЙибаОПНјеЙКЭЪЕгУММЪѕЪжЖЮ
ЁЃ
1 жЊЪЖЬсШЁ
жЊЪЖГщШЁжївЊЪЧУцЯђПЊЗХЕФСДНгЪ§ОнЃЌЭЈГЃЕфаЭЕФЪфШыЪЧздШЛгябдЮФБОЛђепЖрУНЬхФкШнЮФЕЕЃЈЭМЯёЛђепЪгЦЕЃЉЕШЁЃШЛКѓЭЈЙ§здЖЏЛЏЛђепАыздЖЏЛЏЕФММЪѕГщШЁГіПЩгУЕФжЊЪЖЕЅдЊЃЌжЊЪЖЕЅдЊжївЊАќРЈЪЕЬх(ИХФюЕФЭтбг)ЁЂЙиЯЕвдМАЪєад3ИіжЊЪЖвЊЫиЃЌВЂвдДЫЮЊЛљДЁЃЌаЮГЩвЛЯЕСаИпжЪСПЕФЪТЪЕБэДяЃЌЮЊЩЯВуФЃЪНВуЕФЙЙНЈЕьЖЈЛљДЁЁЃ
1.1 ЪЕЬхГщШЁ
ЪЕЬхГщШЁвВГЦЮЊУќУћЪЕЬхбЇЯА(named entity learning) ЛђУќУћЪЕЬхЪЖБ№ (named
entity recognition)ЃЌжИЕФЪЧДгдЪМЪ§ОнгяСЯжаздЖЏЪЖБ№ГіУќУћЪЕЬхЁЃгЩгкЪЕЬхЪЧжЊЪЖЭМЦзжаЕФзюЛљБОдЊЫиЃЌЦфГщШЁЕФЭъећадЁЂзМШЗТЪЁЂейЛиТЪЕШНЋжБНггАЯьЕНжЊЪЖЭМЦзЙЙНЈЕФжЪСПЁЃвђДЫЃЌЪЕЬхГщШЁЪЧжЊЪЖГщШЁжазюЮЊЛљДЁгыЙиМќЕФвЛВНЁЃВЮееЮФЯз[13]ЃЌЮвУЧПЩвдНЋЪЕЬхГщШЁЕФЗНЗЈЗжЮЊ4жжЃКЛљгкАйПЦеОЕуЛђДЙжБеОЕуЬсШЁЁЂЛљгкЙцдђгыДЪЕфЕФЗНЗЈЁЂЛљгкЭГМЦЛњЦїбЇЯАЕФЗНЗЈвдМАУцЯђПЊЗХгђЕФГщШЁЗНЗЈЁЃЛљгкАйПЦеОЕуЛђДЙжБеОЕуЬсШЁдђЪЧвЛжжКмГЃЙцЛљБОЕФЬсШЁЗНЗЈЃЛЛљгкЙцдђЕФЗНЗЈЭЈГЃашвЊЮЊФПБъЪЕЬхБраДФЃАхЃЌШЛКѓдкдЪМгяСЯжаНјааЦЅХфЃЛЛљгкЭГМЦЛњЦїбЇЯАЕФЗНЗЈжївЊЪЧЭЈЙ§ЛњЦїбЇЯАЕФЗНЗЈЖддЪМгяСЯНјаабЕСЗЃЌШЛКѓдйРћгУбЕСЗКУЕФФЃаЭШЅЪЖБ№ЪЕЬхЃЛУцЯђПЊЗХгђЕФГщШЁНЋЪЧУцЯђКЃСПЕФWebгяСЯ[14]ЁЃ
1) ЛљгкАйПЦЛђДЙжБеОЕуЬсШЁ
ЛљгкАйПЦеОЕуЛђДЙжБеОЕуЬсШЁетжжЗНЗЈЪЧДгАйПЦРреОЕуЃЈШчЮЌЛљАйПЦЁЂАйЖШАйПЦЁЂЛЅЖЏАйПЦЕШЃЉЕФБъЬтКЭСДНгжаЬсШЁЪЕЬхУћЁЃетжжЗНЗЈЕФгХЕуЪЧПЩвдЕУЕНПЊЗХЛЅСЊЭјжазюГЃМћЕФЪЕЬхУћЃЌЦфШБЕуЪЧЖдгкжаЕЭЦЕЕФИВИЧТЪЕЭЁЃгывЛАуадЭЈгУЕФЭјеОЯрБШЃЌДЙжБРреОЕуЕФЪЕЬхЬсШЁПЩвдЛёШЁЬиЖЈСьгђЕФЪЕЬхЁЃР§ШчДгЖЙАъИїЦЕЕР(вєРжЁЂЖСЪщЁЂЕчгАЕШ)ЛёШЁИїжжЪЕЬхСаБэЁЃетжжЗНЗЈжївЊЪЧЛљгкХРШЁММЪѕРДЪЕЯжКЭЛёШЁЁЃЛљгкАйПЦРреОЕуЛђДЙжБеОЕуЪЧвЛжжзюГЃЙцКЭЛљБОЕФЗНЗЈЁЃ
2) ЛљгкЙцдђгыДЪЕфЕФЪЕЬхЬсШЁЗНЗЈ
дчЦкЕФЪЕЬхГщШЁЪЧдкЯоЖЈЮФБОСьгђЁЂЯоЖЈгявхЕЅдЊРраЭЕФЬѕМўЯТНјааЕФЃЌжївЊВЩгУЕФЪЧЛљгкЙцдђгыДЪЕфЕФЗНЗЈЃЌР§ШчЪЙгУвбЖЈвхЕФЙцдђЃЌГщШЁГіЮФБОжаЕФШЫУћЁЂЕиУћЁЂзщжЏЛњЙЙУћЁЂЬиЖЈЪБМфЕШЪЕЬх[15]ЁЃЮФЯз[16]ЪзДЮЪЕЯжСЫвЛЬзФмЙЛГщШЁЙЋЫОУћГЦЕФЪЕЬхГщШЁЯЕЭГЃЌЦфжажївЊгУЕНСЫЦєЗЂЪНЫуЗЈгыЙцдђФЃАхЯрНсКЯЕФЗНЗЈЁЃШЛЖјЃЌЛљгкЙцдђФЃАхЕФЗНЗЈВЛНіашвЊвРППДѓСПЕФзЈМвРДБраДЙцдђЛђФЃАхЃЌИВИЧЕФСьгђЗЖЮЇгаЯоЃЌЖјЧвКмФбЪЪгІЪ§ОнБфЛЏЕФаТашЧѓЁЃ
3) ЛљгкЭГМЦЛњЦїбЇЯАЕФЪЕЬхГщШЁЗНЗЈ
МјгкЛљгкЙцдђгыДЪЕфЪЕЬхЕФОжЯоадЃЌЮЊОпИќгаПЩРЉеЙадЃЌЯрЙибаОПШЫдБНЋЛњЦїбЇЯАжаЕФМрЖНбЇЯАЫуЗЈгУгкУќУћЪЕЬхЕФГщШЁЮЪЬтЩЯЁЃР§ШчЮФЯз[17]РћгУKNNЫуЗЈгыЬѕМўЫцЛњГЁФЃаЭЃЌЪЕЯжСЫЖдTwitterЮФБОЪ§ОнжаЪЕЬхЕФЪЖБ№ЁЃЕЅДПЕФМрЖНбЇЯАЫуЗЈдкадФмЩЯВЛНіЪмЕНбЕСЗМЏКЯЕФЯожЦЃЌВЂЧвЫуЗЈЕФзМШЗТЪгыейЛиТЪЖМВЛЙЛРэЯыЁЃЯрЙибаОПепШЯЪЖЕНМрЖНбЇЯАЫуЗЈЕФжЦдМадКѓЃЌГЂЪдНЋМрЖНбЇЯАЫуЗЈгыЙцдђЯрЛЅНсКЯЃЌШЁЕУСЫвЛЖЈЕФГЩЙћЁЃР§ШчЮФЯз[18]ЛљгкзжЕфЃЌЪЙгУзюДѓьиЫуЗЈдкMedlineТлЮФеЊвЊЕФGENIAЪ§ОнМЏЩЯНјааСЫЪЕЬхГщШЁЪЕбщЃЌЪЕбщЕФзМШЗТЪгыейЛиТЪЖМдк70%вдЩЯЁЃНќФъРДЫцзХЩюЖШбЇЯАЕФаЫЦ№гІгУЃЌЛљгкЩюЖШбЇЯАЕФУќУћЪЕЬхЪЖБ№ЕУЕНЙуЗКгІгУЁЃдкЮФЯз[19]ЃЌНщЩмСЫвЛжжЛљгкЫЋЯђLSTMЩюЖШЩёОЭјТчКЭЬѕМўЫцЛњГЁЕФЪЖБ№ЗНЗЈЃЌдкВтЪдЪ§ОнЩЯШЁЕУЕФзюКУЕФБэЯжНсЙћЁЃ

ЭМ4 ЛљгкBI-LSTMКЭCRFЕФМмЙЙ
4) УцЯђПЊЗХгђЕФЪЕЬхГщШЁЗНЗЈ
еыЖдШчКЮДгЩйСПЪЕЬхЪЕР§жаздЖЏЗЂЯжОпгаЧјЗжСІЕФФЃЪНЃЌНјЖјРЉеЙЕНКЃСПЮФБОШЅИјЪЕЬхзіЗжРргыОлРрЕФЮЪЬтЃЌЮФЯз[20]ЬсГіСЫвЛжжЭЈЙ§ЕќДњЗНЪНРЉеЙЪЕЬхгяСЯПтЕФНтОіЗНАИЃЌЦфЛљБОЫМЯыЪЧЭЈЙ§ЩйСПЕФЪЕЬхЪЕР§НЈСЂЬиеїФЃаЭЃЌдйЭЈЙ§ИУФЃаЭгІгУгкаТЕФЪ§ОнМЏЕУЕНаТЕФУќУћЪЕЬхЁЃЮФЯз[21]ЬсГіСЫвЛжжЛљгкЮоМрЖНбЇЯАЕФПЊЗХгђОлРрЫуЗЈЃЌЦфЛљБОЫМЯыЪЧЛљгквбжЊЪЕЬхЕФгявхЬиеїШЅЫбЫїШежОжаЪЖБ№ГіУќУћЕФЪЕЬхЃЌШЛКѓНјааОлРрЁЃ
1.2 гявхРрГщШЁ
гявхРрГщШЁЪЧжИДгЮФБОжаздЖЏГщШЁаХЯЂРДЙЙдьгявхРрВЂНЈСЂЪЕЬхКЭгявхРрЕФЙиСЊ, зїЮЊЪЕЬхВуУцЩЯЕФЙцећКЭГщЯѓЁЃвдЯТНщЩмвЛжжаажЎгааЇЕФгявхРрГщШЁЗНЗЈЃЌАќКЌШ§ИіФЃПщЃКВЂСаЖШЯрЫЦМЦЫуЁЂЩЯЯТЮЛЙиЯЕЬсШЁвдМАгявхРрЩњГЩ
[22]ЁЃ
1) ВЂСаЯрЫЦЖШМЦЫу
ВЂСаЯрЫЦЖШМЦЫуЦфНсЙћЪЧДЪКЭДЪжЎМфЕФЯрЫЦадаХЯЂЃЌР§ШчШ§дЊзщЃЈЦЛЙћЃЌРцЃЌs1ЃЉБэЪОЦЛЙћКЭРцЕФЯрЫЦЖШЪЧs1ЁЃСНИіДЪгаНЯИпЕФВЂСаЯрЫЦЖШЕФЬѕМўЪЧЫќУЧОпгаВЂСаЙиЯЕЃЈМДЭЌЪєгквЛИігявхРрЃЉЃЌВЂЧвгаНЯДѓЕФЙиСЊЖШЁЃАДееетбљЕФБъзМЃЌББОЉКЭЩЯКЃОпгаНЯИпЕФВЂСаЯрЫЦЖШЃЌЖјББОЉКЭЦћГЕЕФВЂСаЯрЫЦЖШКмЕЭЃЈвђЮЊЫќУЧВЛЪєгкЭЌвЛИігявхРрЃЉЁЃЖдгкКЃЕэЁЂГЏбєЁЂуЩааШ§ИіЪаЯНЧјРДЫЕЃЌКЃЕэКЭГЏбєЕФВЂСаЯрЫЦЖШДѓгкКЃЕэКЭуЩааЕФВЂСаЯрЫЦЖШЃЈвђЮЊЧАСНепЕФЙиСЊЖШИќИпЃЉЁЃ
ЕБЧАжїСїЕФВЂСаЯрЫЦЖШМЦЫуЗНЗЈгаЗжВМЯрЫЦЖШЗЈЃЈdistributional similarityЃЉ
КЭФЃЪНЦЅХфЗЈЃЈpattern MatchingЃЉЁЃЗжВМЯрЫЦЖШЗНЗЈ[23-24]ЛљгкЙўРяЫЙЃЈHarrisЃЉЕФЗжВММйЩшЃЈdistributional
hypothesisЃЉ[25]ЃЌМДОГЃГіЯждкРрЫЦЕФЩЯЯТЮФЛЗОГжаЕФСНИіДЪОпгагявхЩЯЕФЯрЫЦадЁЃЗжВМЯрЫЦЖШЗНЗЈЕФЪЕЯжЗжШ§ИіВНжшЃКЕквЛВНЃЌЖЈвхЩЯЯТЮФЃЛЕкЖўВНЃЌАбУПИіДЪБэЪОГЩвЛИіЬиеїЯђСПЃЌЯђСПУПвЛЮЌДњБэвЛИіВЛЭЌЕФЩЯЯТЮФЃЌЯђСПЕФжЕБэЪОБОДЪЯрЖдгкЩЯЯТЮФЕФШЈжиЃЛЕкШ§ВНЃЌМЦЫуСНИіЬиеїЯђСПжЎМфЕФЯрЫЦЖШЃЌНЋЦфзїЮЊЫќУЧЫљДњБэЕФДЪжЎМфЕФЯрЫЦЖШЁЃ
ФЃЪНЦЅХфЗЈЕФЛљБОЫМТЗЪЧАбвЛаЉФЃЪНзїгУгкдДЪ§ОнЃЌЕУЕНвЛаЉДЪКЭДЪжЎМфЙВЭЌГіЯжЕФаХЯЂЃЌШЛКѓАбетаЉаХЯЂОлМЏЦ№РДЩњГЩЕЅДЪжЎМфЕФЯрЫЦЖШЁЃФЃЪНПЩвдЪЧЪжЙЄЖЈвхЕФЃЌвВПЩвдЪЧИљОнвЛаЉжжзгЪ§ОнЖјздЖЏЩњГЩЕФЁЃЗжВМЯрЫЦЖШЗЈКЭФЃЪНЦЅХфЗЈЖМПЩвдгУРДдкЪ§вдАйвкМЦЕФОфзгжаЛђепЪ§вдЪЎвкМЦЕФЭјвГжаГщШЁДЪЕФЯрЫЦадаХЯЂЁЃгаЙиЗжВМЯрЫЦЖШЗЈКЭФЃЪНЦЅХфЗЈЫљЩњГЩЕФЯрЫЦЖШаХЯЂЕФжЪСПБШНЯВЮМћЮФЯзЁЃ
2) ЩЯЯТЮЛЙиЯЕЬсШЁ
ИУИУФЃПщДгЮФЕЕжаГщШЁДЪЕФЩЯЯТЮЛЙиЯЕаХЯЂЃЌЩњГЩЃЈЯТвхДЪЃЌЩЯвхДЪЃЉЪ§ОнЖдЃЌР§ШчЃЈЙЗЃЌЖЏЮяЃЉЁЂЃЈЯЄФсЃЌГЧЪаЃЉЁЃЬсШЁЩЯЯТЮЛЙиЯЕзюМђЕЅЕФЗНЗЈЪЧНтЮіАйПЦРреОЕуЕФЗжРраХЯЂЃЈШчЮЌЛљАйПЦЕФЁАЗжРрЁБКЭАйЖШАйПЦЕФЁАПЊЗХЗжРрЁБЃЉЁЃетжжЗНЗЈЕФжївЊШБЕуАќРЈЃКВЂВЛЪЧЫљгаЕФЗжРрДЪЬѕЖМДњБэЩЯЮЛДЪЃЌР§ШчАйЖШАйПЦжаЁАЙЗЁБЕФПЊЗХЗжРрЁАбјжГЁБОЭВЛЪЧЦфЩЯЮЛДЪЃЛЩњГЩЕФЙиЯЕЭМжаУЛгаШЈжиаХЯЂЃЌвђДЫВЛФмЧјЗжЭЌвЛИіЪЕЬхЫљЖдгІЕФВЛЭЌЩЯЮЛДЪЕФживЊадЃЛИВИЧТЪЦЋЕЭЃЌМДКмЖрЩЯЯТЮЛЙиЯЕВЂУЛгаАќКЌдкАйПЦеОЕуЕФЗжРраХЯЂжаЁЃ
дкгЂЮФЪ§ОнЩЯгУHearst ФЃЪНКЭIsA ФЃЪННјааФЃЪНЦЅХфБЛШЯЮЊЪЧБШНЯгааЇЕФЩЯЯТЮЛЙиЯЕГщШЁЗНЗЈЁЃЯТУцЪЧетаЉФЃЪНЕФжаЮФАцБОЃЈЦфжаNPC
БэЪОЩЯЮЛДЪЃЌNP БэЪОЯТЮЛДЪЃЉЃК
NPC { АќРЈ| АќКЌ| га} {NPЁЂ}* [ ЕШ| ЕШЕШ]
NPC { Шч| БШШч| Яё| Яѓ} {NPЁЂ}*
{NPЁЂ}* [{ вдМА| КЭ| гы} NP] ЕШ NPC
{NPЁЂ}* { вдМА| КЭ| гы} { ЦфЫќ| ЦфЫћ} NPC
NP ЪЧ { вЛИі| вЛжж| вЛРр} NPC
ДЫЭтЃЌвЛаЉЭјвГБэИёжаАќКЌгаЩЯЯТЮЛЙиЯЕаХЯЂЃЌР§ШчдкДјгаБэЭЗЕФБэИёжаЃЌБэЭЗааЕФЮФБОЪЧЦфЫќааЕФЩЯЮЛДЪЁЃ
3) гявхРрЩњГЩ
ИУФЃПщАќРЈОлРрКЭгявхРрБъЖЈСНИізгФЃПщЁЃОлРрЕФНсЙћОіЖЈСЫвЊЩњГЩФФаЉгявхРрвдМАУПИігявхРрАќКЌФФаЉЪЕЬхЃЌЖјгявхРрБъЖЈЕФШЮЮёЪЧИјвЛИігявхРрИНМгвЛИіЛђепЖрИіЩЯЮЛДЪзїЮЊЦфГЩдБЕФЙЋЙВЩЯЮЛДЪЁЃДЫФЃПщвРРЕгкВЂСаЯрЫЦадКЭЩЯЯТЮЛЙиЯЕаХЯЂРДНјааОлРрКЭБъЖЈЁЃгааЉбаОПЙЄзїжЛИљОнЩЯЯТЮЛЙиЯЕЭМРДЩњГЩгявхРрЃЌЕЋОбщБэУїВЂСаЯрЫЦадаХЯЂЖдгкЬсИпзюжеЩњГЩЕФгявхРрЕФОЋЖШКЭИВИЧТЪЖМжСЙиживЊЁЃ
1.3 ЪєадКЭЪєаджЕГщШЁ
ЪєадЬсШЁЕФШЮЮёЪЧЮЊУПИіБОЬхгявхРрЙЙдьЪєадСаБэЃЈШчГЧЪаЕФЪєадАќРЈУцЛ§ЁЂШЫПкЁЂЫљдкЙњМвЁЂЕиРэЮЛжУЕШЃЉЃЌЖјЪєаджЕЬсШЁдђЮЊвЛИігявхРрЕФЪЕЬхИНМгЪєаджЕЁЃЪєадКЭЪєаджЕЕФГщШЁФмЙЛаЮГЩЭъећЕФЪЕЬхИХФюЕФжЊЪЖЭМЦзЮЌЖШЁЃГЃМћЕФЪєадКЭЪєаджЕГщШЁЗНЗЈАќРЈДгАйПЦРреОЕужаЬсШЁЃЌДгДЙжБЭјеОжаНјааАќзАЦїЙщФЩЃЌДгЭјвГБэИёжаЬсШЁЃЌвдМАРћгУЪжЙЄЖЈвхЛђздЖЏЩњГЩЕФФЃЪНДгОфзгКЭВщбЏШежОжаЬсШЁЁЃ
ГЃМћЕФгявхРр/ ЪЕЬхЕФГЃМћЪєад/ ЪєаджЕПЩвдЭЈЙ§НтЮіАйПЦРреОЕужаЕФАыНсЙЙЛЏаХЯЂЃЈШчЮЌЛљАйПЦЕФаХЯЂКаКЭАйЖШАйПЦЕФЪєадБэИёЃЉЖјЛёЕУЁЃОЁЙмЭЈЙ§етжжМђЕЅЪжЖЮФмЙЛЕУЕНИпжЪСПЕФЪєадЃЌЕЋЭЌЪБашвЊВЩгУЦфЫќЗНЗЈРДдіМгИВИЧТЪЃЈМДЮЊгявхРрдіМгИќЖрЪєадвдМАЮЊИќЖрЕФЪЕЬхЬэМгЪєаджЕЃЉЁЃ

ЭМ5 АЎвђЫЙЬЙаХЯЂвГ
гЩгкДЙжБЭјеОЃЈШчЕчзгВњЦЗЭјеОЁЂЭМЪщЭјеОЁЂЕчгАЭјеОЁЂвєРжЭјеОЃЉАќКЌгаДѓСПЪЕЬхЕФЪєадаХЯЂЁЃР§ШчЩЯЭМЕФЭјвГжаАќКЌСЫЭМЪщЕФзїепЁЂГіАцЩчЁЂГіАцЪБМфЁЂЦРЗжЕШаХЯЂЁЃЭЈЙ§ЛљгквЛЖЈЙцдђФЃАхНЈСЂЃЌБуПЩвдДгДЙжБеОЕужаЩњГЩАќзАЦїЃЈЛђГЦЮЊФЃАцЃЉЃЌВЂИљОнАќзАЦїРДЬсШЁЪєадаХЯЂЁЃДгАќзАЦїЩњГЩЕФздЖЏЛЏГЬЖШРДПДЃЌетаЉЗНЗЈПЩвдЗжЮЊЪжЙЄЗЈЃЈМДЪжЙЄБраДАќзАЦїЃЉЁЂМрЖНЗНЗЈЁЂАыМрЖНЗЈвдМАЮоМрЖНЗЈЁЃПМТЧЕНашвЊДгДѓСПВЛЭЌЕФЭјеОжаЬсШЁаХЯЂЃЌВЂЧвЭјеОФЃАцПЩФмЛсИќаТЕШвђЫиЃЌЮоМрЖНАќзАЦїЙщФЩЗНЗЈЯдЕУИќМгживЊКЭЯжЪЕЁЃЮоМрЖНАќзАЦїЙщФЩЕФЛљБОЫМТЗЪЧРћгУЖдЭЌвЛИіЭјеОЯТУцЖрИіЭјвГЕФГЌЮФБОБъЧЉЪїЕФЖдБШРДЩњГЩФЃАцЁЃМђЕЅРДПДЃЌВЛЭЌЭјвГЕФЙЋЙВВПЗжЭљЭљЖдгІгкФЃАцЛђепЪєадУћЃЌВЛЭЌЕФВПЗждђПЩФмЪЧЪєаджЕЃЌЖјЭЌвЛИіЭјвГжажиИДЕФБъЧЉПщдђдЄЪОзХжиИДЕФМЧТМЁЃ
ЪєадГщШЁЕФСэвЛИіаХЯЂдДЪЧЭјвГБэИёЁЃБэИёЕФФкШнЖдгкШЫРДЫЕвЛФПСЫШЛЃЌЖјЖдгкЛњЦїЖјбдЃЌЧщПідђвЊИДдгЕУЖрЁЃгЩгкБэИёРраЭЧЇВюЭђБ№ЃЌКмЖрБэИёжЦзїЕУВЛЙцдђЃЌМгЩЯЛњЦїШБЗІШЫЫљОпгаЕФБГОАжЊЪЖЕШдвђЃЌДгЭјвГБэИёжаЬсШЁИпжЪСПЕФЪєадаХЯЂГЩЮЊЬєеНЁЃ
ЩЯЪіШ§жжЗНЗЈЕФЙВЭЌЕуЪЧЭЈЙ§ЭкОђдЪМЪ§ОнжаЕФАыНсЙЙЛЏаХЯЂРДЛёШЁЪєадКЭЪєаджЕЁЃгыЭЈЙ§ЁАдФЖСЁБОфзгРДНјаааХЯЂГщШЁЕФЗНЗЈЯрБШЃЌетаЉЗНЗЈШЦПЊСЫздШЛгябдРэНтетбљвЛИіЁАгВЙЧЭЗЁБЖјЪдЭМДяЕНвдШсПЫИеЕФаЇЙћЁЃдкЯжНзЖЮЃЌМЦЫуЛњжЊЪЖПтжаЕФДѓЖрЪ§ЪєаджЕШЗЪЕЪЧЭЈЙ§ЩЯЪіЗНЗЈЛёЕУЕФЁЃЕЋЯжЪЕЧщПіЪЧжЛгавЛВПЗжЕФШЫРржЊЪЖЪЧвдАыНсЙЙЛЏаЮЪНЬхЯжЕФЃЌЖјИќЖрЕФжЊЪЖдђвўВидкздШЛгябдОфзгжаЃЌвђДЫжБНгДгОфзгжаГщШЁаХЯЂГЩЮЊНјвЛВНЬсИпжЊЪЖПтИВИЧТЪЕФЙиМќЁЃЕБЧАДгОфзгКЭВщбЏШежОжаЬсШЁЪєадКЭЪєаджЕЕФЛљБОЪжЖЮЪЧФЃЪНЦЅХфКЭЖдздШЛгябдЕФЧГВуДІРэЁЃЭМ6
УшЛцСЫЮЊгявхРрГщШЁЪєадУћЕФжїПђМмЃЈЭЌбљЕФЙ§ГЬвВЪЪгУгкЮЊЪЕЬхГщШЁЪєаджЕЃЉЁЃЭМжаащЯпзѓБпЕФВПЗжЪЧЪфШыЃЌЫќАќРЈвЛаЉЪжЙЄЖЈвхЕФФЃЪНКЭвЛИізїЮЊжжзгЕФЃЈДЪЃЌЪєадЃЉСаБэЁЃФЃЪНЕФР§згВЮМћБэ3ЃЌЃЈДЪЃЌЪєадЃЉЕФР§згШчЃЈББОЉЃЌУцЛ§ЃЉЁЃдкжЛгагявхРрЮоЙиЕФФЃЪНзїЮЊЪфШыЕФЧщПіЯТЃЌећИіЗНЗЈЪЧвЛИідкОфзгжаНјааФЃЪНЦЅХфЖјЩњГЩЃЈгявхРрЃЌЪєадЃЉЙиЯЕЭМЕФЮоМрЖНЕФжЊЪЖЬсШЁЙ§ГЬЁЃДЫЙ§ГЬЗжСНИіВНжшЃЌЕквЛИіВНжшЭЈЙ§НЋЪфШыЕФФЃЪНзїгУЕНОфзгЩЯЖјЩњГЩвЛаЉЃЈДЪЃЌЪєадЃЉдЊзщЃЌетаЉЪ§ОндЊзщдкЕкЖўИіВНжшжаИљОнгявхРрНјааКЯВЂЖјЩњГЩЃЈгявхРрЃЌЪєадЃЉЙиЯЕЭМЁЃдкЪфШыжаАќКЌжжзгСаБэЛђепгявхРрЯрЙиФЃЪНЕФЧщПіЯТЃЌећИіЗНЗЈЪЧвЛИіАыМрЖНЕФздОйЙ§ГЬЃЌЗжШ§ИіВНжшЃК
ФЃЪНЩњГЩЃКдкОфзгжаЦЅХфжжзгСаБэжаЕФДЪКЭЪєадДгЖјЩњГЩФЃЪНЁЃФЃЪНЭЈГЃгЩДЪКЭЪєадЕФЛЗОГаХЯЂЖјЩњГЩЁЃ
ФЃЪНЦЅХфЁЃ
ФЃЪНЦРМлгыбЁдёЃКЭЈЙ§ЩњГЩЕФЃЈгявхРрЃЌЪєадЃЉЙиЯЕЭМЖдздЖЏЩњГЩЕФФЃЪНЕФжЪСПНјааздЖЏЦРМлВЂбЁдёИпЗжжЕЕФФЃЪНзїЮЊЯТвЛТжЦЅХфЕФЪфШыЁЃ
1.3 ЙиЯЕГщШЁ
ЙиЯЕГщШЁЕФФПБъЪЧНтОіЪЕЬхгявхСДНгЕФЮЪЬтЁЃЙиЯЕЕФЛљБОаХЯЂАќРЈВЮЪ§РраЭЁЂТњзуДЫЙиЯЕЕФдЊзщФЃЪНЕШЁЃР§ШчЙиЯЕBeCapitalOfЃЈБэЪОвЛИіЙњМвЕФЪзЖМЃЉЕФЛљБОаХЯЂШчЯТЃК
ВЮЪ§РраЭЃКЃЈCapitalЃЌ CountryЃЉ
ФЃЪНЃК

дЊзщЃКЃЈББОЉЃЌжаЙњЃЉЃЛЃЈЛЊЪЂЖйЃЌУРЙњЃЉЃЛCapital КЭ CountryБэЪОЪзЖМКЭЙњМвСНИігявхРрЁЃ
дчЦкЕФЙиЯЕГщШЁжївЊЪЧЭЈЙ§ШЫЙЄЙЙдьгявхЙцдђвдМАФЃАхЕФЗНЗЈЪЖБ№ЪЕЬхЙиЯЕЁЃЫцКѓЃЌЪЕЬхМфЕФЙиЯЕФЃаЭж№НЅЬцДњСЫШЫЙЄдЄЖЈвхЕФгяЗЈгыЙцдђЁЃЕЋЪЧШдашвЊЬсЧАЖЈвхЪЕЬхМфЕФЙиЯЕРраЭЁЃ
ЮФЯз[26]ЬсГіСЫУцЯђПЊЗХгђЕФаХЯЂГщШЁПђМм (open information extraction,OIE)ЃЌетЪЧГщШЁФЃЪНЩЯЕФвЛИіОоДѓНјВНЁЃЕЋOIEЗНЗЈдкЖдЪЕЬхЕФвўКЌЙиЯЕГщШЁЗНУцадФмЕЭЯТЃЌвђДЫВПЗжбаОПепЬсГіСЫЛљгкТэЖћПЩЗђТпМЭјЁЂЛљгкБОЬхЭЦРэЕФЩюВувўКЌЙиЯЕГщШЁЗНЗЈ[27]ЁЃ
ПЊЗХЪНЪЕЬхЙиЯЕГщШЁ
ПЊЗХЪНЪЕЬхЙиЯЕГщШЁПЩЗжЮЊЖўдЊПЊЗХЪНЙиЯЕГщШЁКЭnдЊПЊЗХЪНЙиЯЕГщШЁЁЃдкЖўдЊПЊЗХЪНЙиЯЕГщШЁжаЃЌдчЦкЕФбаОПгаKnowItAll[28]гыTextRunner[27]ЯЕЭГЃЌдкзМШЗТЪгыейЛиТЪЩЯБэЯжвЛАуЁЃЮФЯз[29]ЬсГіСЫвЛжжЛљгкWikipediaЕФOIEЗНЗЈWOEЃЌОздМрЖНбЇЯАЕУЕНГщШЁЦїЃЌзМШЗТЪНЯTextRunnerгаУїЯдЕФЬсИпЁЃеыЖдWOEЕФШБЕуЃЌЮФЯз[30]ЬсГіСЫЕкЖўДњOIE
ReVerbЯЕЭГЃЌвдЖЏДЪЙиЯЕГщШЁЮЊжїЁЃЮФЯз[31]ЬсГіСЫЕкШ§ДњOIEЯЕЭГOLLIE(open language
learning for information extraction)ЃЌГЂЪдУжВЙВЂРЉеЙOIEЕФФЃаЭМАЯргІЕФЯЕЭГЃЌГщШЁНсЙћЕФзМШЗЖШЕУЕНСЫдіЧПЁЃ
ШЛЖјЃЌЛљгкгявхНЧЩЋБъзЂЕФOIEЗжЮіЯдЪОЃКгЂЮФгяОфжа40%ЕФЪЕЬхЙиЯЕЪЧnдЊЕФ[32]ЃЌШчДІРэВЛЕБЃЌПЩФмЛсгАЯьећЬхГщШЁЕФЭъећадЁЃЮФЯз[33]ЬсГіСЫвЛжжПЩГщШЁШЮвтгЂЮФгяОфжаnдЊЪЕЬхЙиЯЕЕФЗНЗЈKPAKENЃЌУжВЙСЫReVerbЕФВЛзуЁЃЕЋЪЧгЩгкЫуЗЈЖдгяОфЩюВугяЗЈЬиеїЕФЬсШЁЕМжТЦфаЇТЪЯджјЯТНЕЃЌВЂВЛЪЪгУгкДѓЙцФЃПЊЗХгђгяСЯЕФЧщПіЁЃ
ЛљгкСЊКЯЭЦРэЕФЪЕЬхЙиЯЕГщШЁ
СЊКЯЭЦРэЕФЙиЯЕГщШЁжаЕФЕфаЭЗНЗЈЪЧТэЖћПЩЗђТпМЭјMLN(Markov logic network)[34]ЃЌЫќЪЧвЛжжНЋТэЖћПЩЗђЭјТчгывЛНзТпМЯрНсКЯЕФЭГМЦЙиЯЕбЇЯАПђМмЃЌЭЌЪБвВЪЧдкOIEжаШкШыЭЦРэЕФвЛжжживЊЪЕЬхЙиЯЕГщШЁФЃаЭЁЃЛљгкИУФЃаЭЃЌЮФЯз[35]ЬсГіСЫвЛжжЮоМрЖНбЇЯАФЃаЭStatSnowballЃЌВЛЭЌгкДЋЭГЕФOIEЃЌИУЗНЗЈПЩздЖЏВњЩњЛђбЁдёФЃАхЩњГЩГщШЁЦїЁЃдкStatSnowballЕФЛљДЁЩЯЃЌЮФЯз[27,36]ЬсГіСЫвЛжжЪЕЬхЪЖБ№гыЙиЯЕГщШЁЯрНсКЯЕФФЃаЭEntSumЃЌжївЊгЩРЉеЙЕФCRFУќУћЪЕЬхЪЖБ№ФЃПщгыЛљгкStatSnowballЕФЙиЯЕГщШЁФЃПщзщГЩЃЌдкБЃжЄзМШЗТЪЕФЭЌЪБвВЬсИпСЫейЛиТЪЁЃЮФЯз[27,37]ЬсГіСЫвЛжжМђвзЕФMarkovТпМTML(tractable
Markov logic)ЃЌTMLНЋСьгђжЊЪЖЗжНтЮЊШєИЩВПЗжЃЌИїВПЗжжївЊРДдДгкЪТЮяРрЕФВуДЮЛЏНсЙЙЃЌВЂвРОнДЫНсЙЙЃЌНЋИїДѓВПЗжНјвЛВНЗжНтЮЊШєИЩИізгВПЗжЃЌвдДЫРрЭЦЁЃTMLОпгаНЯЧПЕФБэЪОФмСІЃЌФмЙЛНЯЮЊМђНрЕиБэЪОИХФювдМАЙиЯЕЕФБОЬхНсЙЙЁЃ
2 жЊЪЖБэЪО
ДЋЭГЕФжЊЪЖБэЪОЗНЗЈжївЊЪЧвдRDF(Resource Description FrameworkзЪдДУшЪіПђМм)ЕФШ§дЊзщSPO(subject,property,object)РДЗћКХадУшЪіЪЕЬхжЎМфЕФЙиЯЕЁЃетжжБэЪОЗНЗЈЭЈгУМђЕЅЃЌЪмЕНЙуЗКШЯПЩЃЌЕЋЪЧЦфдкМЦЫуаЇТЪЁЂЪ§ОнЯЁЪшадЕШЗНУцУцСйжюЖрЮЪЬтЁЃНќФъРДЃЌвдЩюЖШбЇЯАЮЊДњБэЕФвдЩюЖШбЇЯАЮЊДњБэЕФБэЪОбЇЯАММЪѕШЁЕУСЫживЊЕФНјеЙЃЌПЩвдНЋЪЕЬхЕФгявхаХЯЂБэЪОЮЊГэУмЕЭЮЌЪЕжЕЯђСПЃЌНјЖјдкЕЭЮЌПеМфжаИпаЇМЦЫуЪЕЬхЁЂЙиЯЕМАЦфжЎМфЕФИДдггявхЙиСЊЃЌЖджЊЪЖПтЕФЙЙНЈЁЂЭЦРэЁЂШкКЯвдМАгІгУОљОпгаживЊЕФвтвх[38-40]ЁЃ
2.1 ДњБэФЃаЭ
жЊЪЖБэЪОбЇЯАЕФДњБэФЃаЭгаОрРыФЃаЭЁЂЕЅВуЩёОЭјТчФЃаЭЁЂЫЋЯпадФЃаЭЁЂЩёОеХСПФЃаЭЁЂОиеѓЗжНтФЃаЭЁЂЗвыФЃаЭЕШЁЃЯъЯИПЩВЮМћЧхЛЊДѓбЇСѕжЊдЖЕФжЊЪЖБэЪОбЇЯАбаОПНјеЙЁЃЯрЙиЪЕЯжвВПЩВЮМћ
[39]ЁЃ
1ЃЉОрРыФЃаЭ
ОрРыФЃаЭдкЮФЯз[41] ЬсГіСЫжЊЪЖПтжаЪЕЬхвдМАЙиЯЕЕФНсЙЙЛЏБэЪОЗНЗЈ(structured embeddingЃЌSE)ЃЌЦфЛљБОЫМЯыЪЧЃКЪзЯШНЋЪЕЬхгУЯђСПНјааБэЪОЃЌШЛКѓЭЈЙ§ЙиЯЕОиеѓНЋЪЕЬхЭЖгАЕНгыЪЕЬхЙиЯЕЖдЕФЯђСППеМфжаЃЌзюКѓЭЈЙ§МЦЫуЭЖгАЯђСПжЎМфЕФОрРыРДХаЖЯЪЕЬхМфвбДцдкЕФЙиЯЕЕФжУаХЖШЁЃгЩгкОрРыФЃаЭжаЕФЙиЯЕОиеѓЪЧСНИіВЛЭЌЕФОиеѓЃЌЪЙЕУаЭЌадНЯВюЁЃ
2ЃЉЕЅВуЩёОЭјТчФЃаЭ
ЮФЯз[42]еыЖдЩЯЪіЬсЕНЕФОрРыФЃаЭжаЕФШБЯнЃЌЬсГіСЫВЩгУЕЅВуЩёОЭјТчЕФЗЧЯпадФЃаЭ(single layer
modelЃЌSLM)ЃЌФЃаЭЮЊжЊЪЖПтжаУПИіШ§дЊзщЃЈh,r,t) ЖЈвхСЫвдЯТаЮЪНЕФЦРМлКЏЪ§ЃК

ЪНжаЃЌ utЕФTДЮУнЁЪRЕФkДЮУнЮЊЙиЯЕ r ЕФЯђСПЛЏБэЪОЃЛg()ЮЊtanhКЏЪ§ЃЛ Mr,1ЁСMr,2ЁЪRЕФkДЮУнЪЧЭЈЙ§ЙиЯЕrЖЈвхЕФСНИіОиеѓЁЃЕЅВуЩёОЭјТчФЃаЭЕФЗЧЯпадВйзїЫфШЛФмЙЛНјвЛВНПЬЛЪЕЬхдкЙиЯЕЯТЕФгявхЯрЙиадЃЌЕЋдкМЦЫуПЊЯњЩЯШДДѓДѓдіМгЁЃ
3ЃЉЫЋЯпадФЃаЭ
ЫЋ Яп ад ФЃ аЭ гж На вў Бф СП ФЃ аЭ (latent factor modelЃЌLFM)ЃЌгЩЮФЯз[43-44]ЪзЯШЬсГіЁЃФЃаЭЮЊжЊЪЖПтжаУПИіШ§дЊзщ
ЖЈвхЕФЦРМлКЏЪ§ОпгаШчЯТаЮЪНЃК

ЪНжа,MrЁЪRЕФdЁСdДЮУнЪЧЭЈЙ§ЙиЯЕr ЖЈвхЕФЫЋЯпадБфЛЛОиеѓЃЛ
lhЁСltЁЪRЕФdДЮУнЪЧШ§дЊзщжаЭЗЪЕЬхгыЮВЪЕЬхЕФЯђСПЛЏБэЪОЁЃЫЋЯпадФЃаЭжївЊЪЧЭЈЙ§ЛљгкЪЕЬхМфЙиЯЕЕФЫЋЯпадБфЛЛРДПЬЛЪЕЬхдкЙиЯЕЯТЕФгявхЯрЙиадЁЃФЃаЭВЛНіаЮЪНМђЕЅЁЂвзгкМЦЫуЃЌЖјЧвЛЙФмЙЛгааЇПЬЛЪЕЬхМфЕФаЭЌадЁЃЛљгкЩЯЪіЙЄзїЃЌЮФЯз[45]ГЂЪдНЋЫЋЯпадБфЛЛОиеѓr
M БфЛЛЮЊЖдНЧОиеѓЃЌ ЬсГіСЫDISTMULTФЃаЭЃЌВЛНіМђЛЏСЫМЦЫуЕФИДдгЖШЃЌВЂЧвЪЕбщаЇЙћЕУЕНСЫЯджјЬсЩ§ЁЃ
4ЃЉЩёОеХСПФЃаЭ
ЮФЯз[45]ЬсГіЕФЩёОеХСПФЃаЭЃЌЦфЛљБОЫМЯыЪЧЃКдкВЛЭЌЕФЮЌЖШЯТЃЌНЋЪЕЬхСЊЯЕЦ№РДЃЌБэЪОЪЕЬхМфИДдгЕФгявхСЊЯЕЁЃФЃаЭЮЊжЊЪЖПтжаЕФУПИіШ§дЊзщ(h,r,t)ЖЈвхСЫвдЯТаЮЪНЕФЦРМлКЏЪ§ЃК

ЪНжаЃЌ utЕФTДЮУнЁЪRЕФkДЮУнЮЊЙиЯЕ r ЕФЯђСПЛЏБэЪОЃЛg()ЮЊtanhКЏЪ§ЃЛ MrЁЪdЁСkЁСkЪЧвЛИіШ§НзеХСПЃЛMr,1ЁСMr,2ЁЪRЕФkДЮУнЪЧЭЈЙ§ЙиЯЕrЖЈвхЕФСНИіОиеѓЁЃ
ЩёОеХСПФЃаЭдкЙЙНЈЪЕЬхЕФЯђСПБэЪОЪБЃЌЪЧНЋИУЪЕЬхжаЕФЫљгаЕЅДЪЕФЯђСПШЁЦНОљжЕЃЌетбљвЛЗНУцПЩвджиИДЪЙгУЕЅДЪЯђСПЙЙНЈЪЕЬхЃЌСэвЛЗНУцНЋгаРћгкдіЧПЕЭЮЌЯђСПЕФГэУмГЬЖШвдМАЪЕЬхгыЙиЯЕЕФгявхМЦЫуЁЃ
5ЃЉОиеѓЗжНтФЃаЭ
ЭЈЙ§ОиеѓЗжНтЕФЗНЪНПЩЕУЕНЕЭЮЌЕФЯђСПБэЪОЃЌЙЪВЛЩйбаОПепЬсГіПЩВЩгУИУЗНЪННјаажЊЪЖБэЪОбЇЯАЃЌЦфжаЕФЕфаЭДњБэЪЧЮФЯз[46]ЬсГіЕФRESACLФЃаЭЁЃдкRESCALФЃаЭжаЃЌжЊЪЖПтжаЕФШ§дЊзщМЏКЯБЛБэЪОЮЊвЛИіШ§НзеХСПЃЌШчЙћИУШ§дЊзщДцдкЃЌеХСПжаЖдгІЮЛжУЕФдЊЫиБЛжУ1ЃЌЗёдђжУЮЊ0ЁЃЭЈЙ§еХСПЗжНтЫуЗЈЃЌПЩНЋеХСПжаУПИіШ§дЊзщЃЈh,r,t)ЖдгІЕФеХСПжЕНтЮЊЫЋЯпадФЃаЭжаЕФжЊЪЖБэЪОаЮЪНlhЕФTДЮУнЁСMrЁСltВЂЪЙ|Xhrt-lhЕФTДЮУнЁСMrЁСl|ОЁСПаЁЁЃ
6ЃЉЗвыФЃаЭ
ЮФЯз[47]ЪмЕНЦНвЦВЛБфЯжЯѓЕФЦєЗЂЃЌЬсГіСЫTransEФЃаЭЃЌМДНЋжЊЪЖПтжаЪЕЬхжЎМфЕФЙиЯЕПДГЩЪЧДгЪЕЬхМфЕФФГжжЦНвЦЃЌВЂгУЯђСПБэЪОЁЃЙиЯЕlrПЩвдПДзїЪЧДгЭЗЪЕЬхЯђСПЕНЮВЪЕЬхЯђСПltЕФЗвыЁЃЖдгкжЊЪЖПтжаЕФУПИіШ§дЊзщ(h,r,t),TransEЖМЯЃЭћТњзувдЯТЙиЯЕ|lh+ltЁжlt|ЃКЃЌЦфЫ№ЪЇКЏЪ§ЮЊЃКfr(h,t)=|lh+lr-lt|L1/L2,
ИУФЃаЭЕФВЮЪ§НЯЩйЃЌМЦЫуЕФИДдгЖШЯджјНЕЕЭЁЃгыДЫЭЌЪБЃЌTransEФЃаЭдкДѓЙцФЃЯЁЪшжЊЪЖПтЩЯвВЭЌбљОпгаНЯКУЕФадФмКЭПЩРЉеЙадЁЃ
2.2 ИДдгЙиЯЕФЃаЭ
жЊЪЖПтжаЕФЪЕЬхЙиЯЕРраЭвВПЩЗжЮЊ1-to-1ЁЂ1-to-NЁЂN-to-1ЁЂN-to-N4жжРраЭ[47]ЃЌЖјИДдгЙиЯЕжївЊжИЕФЪЧ1-to-NЁЂN-to-1ЁЂN-to-NЕФ3жжЙиЯЕРраЭЁЃгЩгкTransEФЃаЭВЛФмгУдкДІРэИДдгЙиЯЕЩЯ[39]ЃЌвЛЯЕСаЛљгкЫќЕФРЉеЙФЃаЭЗзЗзБЛЬсГіЃЌЯТУцНЋзХжиНщЩмЦфжаЕФМИЯюДњБэадЙЄзїЁЃ
1ЃЉTransHФЃаЭ
ЮФЯз[48]ЬсГіЕФTransHФЃаЭГЂЪдЭЈЙ§ВЛЭЌЕФаЮЪНБэЪОВЛЭЌЙиЯЕжаЕФЪЕЬхНсЙЙЃЌЖдгкЭЌвЛИіЪЕЬхЖјбдЃЌЫќдкВЛЭЌЕФЙиЯЕЯТвВАчбнзХВЛЭЌЕФНЧЩЋЁЃФЃаЭЪзЯШЭЈЙ§ЙиЯЕЯђСПlrгыЦфе§НЛЕФЗЈЯђСПwrбЁШЁФГвЛИіГЌЦНУцFЃЌ
ШЛКѓНЋЭЗЪЕЬхЯђСПlhКЭЮВЪЕЬхЯђСПltЗЈЯђСПwrЕФЗНЯђЭЖгАЕНF, зюКѓМЦЫуЫ№ЪЇКЏЪ§ЁЃTransHЪЙВЛЭЌЕФЪЕЬхдкВЛЭЌЕФЙиЯЕЯТгЕгаСЫВЛЭЌЕФБэЪОаЮЪНЃЌЕЋгЩгкЪЕЬхЯђСПБЛЭЖгАЕНСЫЙиЯЕЕФгявхПеМфжаЃЌЙЪЫќУЧОпгаЯрЭЌЕФЮЌЖШЁЃ
2ЃЉTransRФЃаЭ
гЩгкЪЕЬхЁЂЙиЯЕЪЧВЛЭЌЕФЖдЯѓЃЌВЛЭЌЕФЙиЯЕЫљЙизЂЕФЪЕЬхЕФЪєадвВВЛОЁЯрЭЌЃЌНЋЫќУЧгГЩфЕНЭЌвЛИігявхПеМфЃЌдквЛЖЈГЬЖШЩЯОЭЯожЦСЫФЃаЭЕФБэДяФмСІЁЃЫљвдЃЌЮФЯз[49]ЬсГіСЫTransRФЃаЭЁЃФЃаЭЪзЯШНЋжЊЪЖПтжаЕФУПИіШ§дЊзщ(h,
r,t)ЕФЭЗЪЕЬхгыЮВЪЕЬхЯђЙиЯЕПеМфжаЭЖгАЃЌШЛКѓЯЃЭћТњзу|lh+ltЁжlt|ЕФЙиЯЕЃЌзюКѓМЦЫуЫ№ЪЇКЏЪ§ЁЃ
ЮФЯз[49]ЬсГіЕФCTransRФЃаЭШЯЮЊЙиЯЕЛЙПЩзіИќЯИжТЕФЛЎЗжЃЌетНЋгаРћгкЬсИпЪЕЬхгыЙиЯЕЕФгявхСЊЯЕЁЃдкCTransRФЃаЭжаЃЌЭЈЙ§ЖдЙиЯЕr
ЖдгІЕФЭЗЪЕЬхЁЂЮВЪЕЬхЯђСПЕФВюжЕlh-ltНјааОлРрЃЌПЩНЋrЗжЮЊШєИЩИізгЙиЯЕrc ЁЃ
3ЃЉTransDФЃаЭ
ПМТЧЕНдкжЊЪЖПтЕФШ§дЊзщжаЃЌЭЗЪЕЬхКЭЮВЪЕЬхБэЪОЕФКЌвхЁЂРраЭвдМАЪєадПЩФмгаНЯДѓВювьЃЌжЎЧАЕФTransRФЃаЭЪЙЫќУЧБЛЭЌвЛИіЭЖгАОиеѓНјаагГЩфЃЌдквЛЖЈГЬЖШЩЯОЭЯожЦСЫФЃаЭЕФБэДяФмСІЁЃГ§ДЫжЎЭтЃЌНЋЪЕЬхгГЩфЕНЙиЯЕПеМфЬхЯжЕФЪЧДгЪЕЬхЕНЙиЯЕЕФгя
вхСЊЯЕЃЌЖјTransRФЃаЭжаЬсГіЕФЭЖгАОиеѓНіПМТЧСЫВЛЭЌЕФЙиЯЕРраЭЃЌЖјКіЪгСЫЪЕЬхгыЙиЯЕжЎМфЕФНЛЛЅЁЃвђДЫЃЌЮФЯз[50]ЬсГіСЫTransDФЃаЭЃЌФЃаЭЗжБ№ЖЈвхСЫЭЗЪЕЬхгыЮВЪЕЬхдкЙиЯЕПеМфЩЯЕФЭЖгАОиеѓЁЃ
4ЃЉTransGФЃаЭ
ЮФЯз[51]ЬсГіЕФTransGФЃаЭШЯЮЊвЛжжЙиЯЕПЩФмЛсЖдгІЖржжгявхЃЌЖјУПвЛжжгявхЖМПЩвдгУвЛИіИпЫЙЗжВМБэЪОЁЃTransGФЃаЭПМТЧЕНСЫЙиЯЕr
ЕФВЛЭЌгявхЃЌЪЙгУИпЫЙЛьКЯФЃаЭРДУшЪіжЊЪЖПтжаУПИіШ§дЊзщ(h,r,t)ЭЗЪЕЬхгыЮВЪЕЬхжЎМфЕФЙиЯЕЃЌОпгаНЯИпЕФЪЕЬхЧјЗжЖШЁЃ
5ЃЉKG2EФЃаЭ
ПМТЧЕНжЊЪЖПтжаЕФЪЕЬхвдМАЙиЯЕЕФВЛШЗЖЈадЃЌЮФЯз[52]ЬсГіСЫKG2EФЃаЭЃЌЦфжаЭЌбљЪЧгУИпЫЙЗжВМРДПЬЛЪЕЬхгыЙиЯЕЁЃФЃаЭЪЙгУИпЫЙЗжВМЕФОљжЕБэЪОЪЕЬхЛђЙиЯЕдкгявхПеМфжаЕФжааФЮЛжУЃЌаЗНВюдђБэЪОЪЕЬхЛђЙиЯЕЕФВЛШЗЖЈЖШЁЃ
жЊЪЖПтжаЃЌУПИіШ§дЊзщ(h,r,t)ЕФЭЗЪЕЬхЯђСПгыЮВЪЕЬхЯђСПМфЕФ
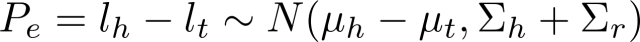
ЙиЯЕrПЩБэЪОЮЊЃК

3 жЊЪЖШкКЯ
ЭЈЙ§жЊЪЖЬсШЁЃЌЪЕЯжСЫДгЗЧНсЙЙЛЏКЭАыНсЙЙЛЏЪ§ОнжаЛёШЁЪЕЬхЁЂЙиЯЕвдМАЪЕЬхЪєадаХЯЂЕФФПБъЁЃЕЋЪЧгЩгкжЊЪЖРДдДЙуЗКЃЌДцдкжЊЪЖжЪСПСМнЌВЛЦыЁЂРДздВЛЭЌЪ§ОндДЕФжЊЪЖжиИДЁЂВуДЮНсЙЙШБЪЇЕШЮЪЬтЃЌЫљвдБиаывЊНјаажЊЪЖЕФШкКЯЁЃжЊЪЖШкКЯЪЧИпВуДЮЕФжЊЪЖзщжЏ[53]ЃЌЪЙРДздВЛЭЌжЊЪЖдДЕФжЊЪЖдкЭЌвЛПђМмЙцЗЖЯТНјаавьЙЙЪ§ОнећКЯЁЂЯћЦчЁЂМгЙЄЁЂЭЦРэбщжЄЁЂИќаТЕШВНжш[54]ЃЌДяЕНЪ§ОнЁЂаХЯЂЁЂЗНЗЈЁЂОбщвдМАШЫЕФЫМЯыЕФШкКЯЃЌаЮГЩИпжЪСПЕФжЊЪЖПтЁЃ
3.1 ЪЕЬхЖдЦы
ЪЕЬхЖдЦы (entity alignment) вВГЦЮЊЪЕЬхЦЅХф (entity matching)ЛђЪЕЬхНтЮі(entity
resolution)ЛђепЪЕЬхСДНгЃЈentity linkingЃЉЃЌжївЊЪЧгУгкЯћГ§вьЙЙЪ§ОнжаЪЕЬхГхЭЛЁЂжИЯђВЛУїЕШВЛвЛжТадЮЪЬтЃЌПЩвдДгЖЅВуДДНЈвЛИіДѓЙцФЃЕФЭГвЛжЊЪЖПтЃЌДгЖјАяжњЛњЦїРэНтЖрдДвьжЪЕФЪ§ОнЃЌаЮГЩИпжЪСПЕФжЊЪЖЁЃ
дкДѓЪ§ОнЕФЛЗОГЯТЃЌЪмжЊЪЖПтЙцФЃЕФгАЯьЃЌдкНјаажЊЪЖПтЪЕЬхЖдЦыЪБЃЌжївЊЛсУцСйвдЯТ3ИіЗНУцЕФЬєеН[55]ЃК1)
МЦЫуИДдгЖШЁЃЦЅХфЫуЗЈЕФМЦЫуИДдгЖШЛсЫцжЊЪЖПтЕФЙцФЃГЪЖўДЮдіГЄЃЌФбвдНгЪмЃЛ2) Ъ§ОнжЪСПЁЃгЩгкВЛЭЌжЊЪЖПтЕФЙЙНЈФПЕФгыЗНЪНгаЫљВЛЭЌЃЌПЩФмДцдкжЊЪЖжЪСПСМнЌВЛЦыЁЂЯрЫЦжиИДЪ§ОнЁЂЙТСЂЪ§ОнЁЂЪ§ОнЪБМфСЃЖШВЛвЛжТЕШЮЪЬт[56]ЃЛ3)
ЯШбщбЕСЗЪ§ОнЁЃдкДѓЙцФЃжЊЪЖПтжаЯывЊЛёЕУетжжЯШбщЪ§ОнШДЗЧГЃРЇФбЁЃЭЈГЃЧщПіЯТЃЌашвЊбаОПепЪжЙЄЙЙдьЯШбщбЕСЗЪ§ОнЁЃ
ЛљгкЩЯЪіЃЌжЊЪЖПтЪЕЬхЖдЦыЕФжївЊСїГЬНЋАќРЈ[55]ЃК1) НЋД§ЖдЦыЪ§ОнНјааЗжЧјЫїв§ЃЌвдНЕЕЭМЦЫуЕФИДдгЖШЃЛ2)
РћгУЯрЫЦЖШКЏЪ§ЛђЯрЫЦадЫуЗЈВщевЦЅХфЪЕР§ЃЛ3) ЪЙгУЪЕЬхЖдЦыЫуЗЈНјааЪЕР§ШкКЯЃЛ4) НЋВНжш2)гыВНжш3)ЕФНсЙћНсКЯЦ№РДЃЌаЮГЩзюжеЕФЖдЦыНсЙћЁЃЖдЦыЫуЗЈПЩЗжЮЊГЩЖдЪЕЬхЖдЦыгыМЏЬхЪЕЬхЖдЦыСНДѓРрЃЌЖјМЏЬхЪЕЬхЖдЦыгжПЩЗжЮЊОжВПМЏЬхЪЕЬхЖдЦыгыШЋОжМЏЬхЪЕЬхЖдЦыЁЃ
1ЃЉГЩЖдЪЕЬхЖдЦыЗНЗЈ
Ђй ЛљгкДЋЭГИХТЪФЃаЭЕФЪЕЬхЖдЦыЗНЗЈ
ЛљгкДЋЭГИХТЪФЃаЭЕФЪЕЬхЖдЦыЗНЗЈжївЊОЭЪЧПМТЧСНИіЪЕЬхИїздЪєадЕФЯрЫЦадЃЌЖјВЂВЛПМТЧЪЕЬхМфЕФЙиЯЕЁЃЮФЯз[57]НЋЛљгкЪєадЯрЫЦЖШЦРЗжРДХаЖЯЪЕЬхЪЧЗёЦЅХфЕФЮЪЬтзЊЛЏЮЊвЛИіЗжРрЮЪЬтЃЌНЈСЂСЫИУЮЪЬтЕФИХТЪФЃаЭЃЌШБЕуЪЧУЛгаЬхЯжживЊЪєадЖдгкЪЕЬхЯрЫЦЖШЕФгАЯьЁЃЮФЯз[58]ЛљгкИХТЪЪЕЬхСДНгФЃаЭЃЌЮЊУПИіЦЅХфЕФЪєадЖдЗжХфСЫВЛЭЌЕФШЈжиЃЌЦЅХфзМШЗЖШгаЫљЬсИпЁЃЮФЯз[59]ЛЙНсКЯБДвЖЫЙЭјТчЖдЪєадЕФЯрЙиадНјааНЈФЃЃЌВЂЪЙгУзюДѓЫЦШЛЙРМЦЗНЗЈЖдФЃаЭжаЕФВЮЪ§НјааЙРМЦЁЃ
Ђк ЛљгкЛњЦїбЇЯАЕФЪЕЬхЖдЦыЗНЗЈ
ЛљгкЛњЦїбЇЯАЕФЪЕЬхЖдЦыЗНЗЈжївЊЪЧНЋЪЕЬхЖдЦыЮЪЬтзЊЛЏЮЊЖўЗжРрЮЪЬтЁЃИљОнЪЧЗёЪЙгУБъзЂЪ§ОнПЩЗжЮЊгаМрЖНбЇЯАгыЮоМрЖНбЇЯАСНРрЃЌЛљгкМрЖНбЇЯАЕФЪЕЬхЖдЦыЗНЗЈжївЊПЩЗжЮЊГЩЖдЪЕЬхЖдЦыЁЂЛљгкОлРрЕФЖдЦыЁЂжїЖЏбЇЯАЁЃ
ЭЈЙ§ЪєадБШНЯЯђСПРДХаЖЯЪЕЬхЖдЦЅХфгыЗёПЩГЦЮЊГЩЖдЪЕЬхЖдЦыЁЃетРрЗНЗЈжаЕФЕфаЭДњБэгаОіВпЪї [60]ЁЂжЇГжЯђСПЛњ[61]ЁЂМЏГЩбЇЯА[62]ЕШЁЃЮФЯз[63]ЪЙгУЗжРрЛиЙщЪїЁЂЯпадЗжЮіХаБ№ЕШЗНЗЈЭъГЩСЫЪЕЬхБцЮіЁЃЮФЯз[64]ЛљгкЖўНзЖЮЪЕЬхСДНгЗжЮіФЃаЭЃЌЬсГіСЫвЛжжаТЕФSVMЗжРрЗНЗЈЃЌЦЅХфзМШЗТЪдЖИпгкTAILORжаЕФЛьКЯЫуЗЈЁЃ
ЛљгкОлРрЕФЪЕЬхЖдЦыЫуЗЈЃЌЦфжївЊЫМЯыЪЧНЋЯрЫЦЕФЪЕЬхОЁСПОлМЏЕНвЛЦ№ЃЌдйНјааЪЕЬхЖдЦыЁЃЮФЯз[65]ЬсГіСЫвЛжжРЉеЙадНЯЧПЕФздЪЪгІЪЕЬхУћГЦЦЅХфгыОлРрЫуЗЈЃЌПЩЭЈЙ§бЕСЗбљБОЩњГЩвЛИіздЪЪгІЕФОрРыКЏЪ§ЁЃЮФЯз[66]ВЩгУРрЫЦЕФЗНЗЈЃЌдкЬѕМўЫцЛњГЁЪЕЬхЖдЦыФЃаЭжаЪЙгУМрЖНбЇЯАЕФЗНЗЈбЕСЗВњЩњОрРыКЏЪ§ЃЌШЛКѓЕїећШЈжиЃЌЪЙЬиеїКЏЪ§гыбЇЯАВЮЪ§ЕФЛ§зюДѓЁЃ
дкжїЖЏбЇЯАжаЃЌПЩЭЈЙ§гыШЫдБЕФВЛЖЯНЛЛЅРДНтОіКмФбЛёЕУзуЙЛЕФбЕСЗЪ§ОнЮЪЬтЃЌЮФЯз[67]ЙЙНЈЕФALIASЯЕЭГПЩЭЈЙ§ШЫЛњНЛЛЅЕФЗНЪНЭъГЩЪЕЬхСДНггыШЅжиЕФШЮЮёЁЃЮФЯз[68]ВЩгУЯрЫЦЕФЗНЗЈЙЙНЈСЫActiveAtlasЯЕЭГЁЃ
2ЃЉОжВПМЏЬхЪЕЬхЖдЦыЗНЗЈ
ОжВПМЏЬхЪЕЬхЖдЦыЗНЗЈЮЊЪЕЬхБОЩэЕФЪєадвдМАгыЫќгаЙиСЊЕФЪЕЬхЕФЪєадЗжБ№ЩшжУВЛЭЌЕФШЈжиЃЌВЂЭЈЙ§МгШЈЧѓКЭМЦЫузмЬхЕФЯрЫЦЖШЃЌЛЙПЩЪЙгУЯђСППеМфФЃаЭвдМАгрЯвЯрЫЦадРДХаБ№ДѓЙцФЃжЊЪЖПтжаЕФЪЕЬхЕФЯрЫЦГЬЖШ[69]ЃЌЫуЗЈЮЊУПИіЪЕЬхНЈСЂСЫУћГЦЯђСПгыащФтЮФЕЕЯђСПЃЌУћГЦЯђСПгУгкБъЪЖЪЕЬхЕФЪєадЃЌащФтЮФЕЕЯђСПдђгУгкБэЪОЪЕЬхЕФЪєаджЕвдМАЦфСкОгНкЕуЕФЪєаджЕЕФМгШЈКЭжЕ[55]ЁЃЮЊСЫЦРМлЯђСПжаУПИіЗжСПЕФживЊадЃЌЫуЗЈжївЊЪЙгУTF-IDFЮЊУПИіЗжСПЩшжУШЈжиЃЌВЂЮЊЗжСПЯђСПНЈСЂЕЙХХЫїв§ЃЌзюКѓбЁдёгрЯвЯрЫЦадКЏЪ§МЦЫуЫќУЧЕФЯрЫЦГЬЖШ[55]ЁЃИУЫуЗЈЕФейЛиТЪНЯИпЃЌжДааЫйЖШПьЃЌЕЋзМШЗТЪВЛзуЁЃЦфИљБОдвђдкгкУЛгаеце§ДггявхЗНУцНјааПМТЧЁЃ
3ЃЉШЋОжМЏЬхЪЕЬхЖдЦыЗНЗЈ
Ђй ЛљгкЯрЫЦадДЋВЅЕФМЏЬхЪЕЬхЖдЦыЗНЗЈ
ЛљгкЯрЫЦадДЋВЅЕФЗНЗЈЪЧвЛжжЕфаЭЕФМЏЬхЪЕЬхЖдЦыЗНЗЈЃЌЦЅХфЕФСНИіЪЕЬхгыЫќУЧВњЩњжБНгЙиСЊЕФЦфЫћЪЕЬхвВЛсОпгаНЯИпЕФЯрЫЦадЃЌЖјетжжЯрЫЦадгжЛсгАЯьЙиСЊЕФЦфЫћЪЕЬх[55]ЁЃ
ЯрЫЦадДЋВЅМЏЬхЪЕЬхЖдЦыЗНЗЈзюдчРДдДгкЮФЯз[70-71]ЬсГіЕФМЏКЯЙиЯЕОлРрЫуЗЈЃЌИУЫуЗЈжївЊЭЈЙ§вЛжжИФНјЕФВуДЮФ§ОлЫуЗЈЕќДњВњЩњЦЅХфЖдЯѓЁЃЮФЯз[72]дквдЩЯЫуЗЈЕФЛљДЁЩЯЬсГіСЫЪЪгУгкДѓЙцФЃжЊЪЖПтЪЕЬхЖдЦыЕФЫуЗЈSiGMaЃЌИУЫуЗЈНЋЪЕЬхЖдЦыЮЪЬтПДГЩЪЧвЛИіШЋОжЦЅХфЦРЗжФПБъКЏЪ§ЕФгХЛЏЮЪЬтНјааНЈФЃЃЌЪєгкЖўДЮЗжХфЮЪЬтЃЌПЩЭЈЙ§ЬАРЗгХЛЏЫуЗЈЧѓЕУЦфНќЫЦНтЁЃSiGMaЗНЗЈ[55]ФмЙЛзлКЯПМТЧЪЕЬхЖдЕФЪєадгыЙиЯЕЃЌЭЈЙ§МЏЬхЪЕЬхЕФСьгђЃЌВЛЖЯЕќДњЗЂЯжЫљгаЕФЦЅХфЖдЁЃ
Ђк ЛљгкИХТЪФЃаЭЕФМЏЬхЪЕЬхЖдЦыЗНЗЈЛљгкИХТЪФЃаЭЕФМЏЬхЪЕЬхЖдЦыЗНЗЈжївЊВЩгУЭГМЦЙиЯЕбЇЯАНјааМЦЫугыЭЦРэЃЌГЃгУЕФЗНЗЈгаLDAФЃаЭ[73]ЁЂCRFФЃаЭ[74]ЁЂMarkovТпМЭј[75]ЕШЁЃ
ЮФЯз[73]НЋLDAФЃаЭгІгУгкЪЕЬхЕФНтЮіЙ§ГЬжаЃЌЭЈЙ§ЦфжаЕФвўКЌБфСПЛёШЁЪЕЬхжЎМфЕФЙиЯЕЁЃЕЋдкДѓЙцФЃЕФЪ§ОнМЏЩЯаЇЙћвЛАуЁЃЮФЯз[74]ЬсГіСЫвЛжжЛљгкЭМЛЎЗжММЪѕЕФCRFЪЕЬхБцЮіФЃаЭЃЌИУФЃаЭвдЙлВьжЕЮЊЬѕМўВњЩњЪЕЬхХаБ№ЕФОіВпЃЌгаРћгкДІРэЪєадМфОпгавРРЕЙиЯЕЕФЪ§ОнЁЃЮФЯз[66]дкCRFЪЕЬхБцЮіФЃаЭЕФЛљДЁЩЯЬсГіСЫвЛжжЛљгкЬѕМўЫцЛњГЁФЃаЭЕФЖрЙиЯЕЕФЪЕЬхСДНгЫуЗЈЃЌв§ШыСЫЛљгкcanopyЕФЫїв§ЃЌЬсИпСЫДѓЙцФЃжЊЪЖПтЛЗОГЯТЕФМЏЬхЪЕЬхЖдЦыаЇТЪЁЃЮФЯз[75]ЬсГіСЫвЛжжЛљгкMarkovТпМЭјЕФЪЕЬхНтЮіЗНЗЈЁЃЭЈЙ§MarkovТпМЭјЃЌПЩЙЙНЈвЛИіMarkovЭјЃЌНЋИХТЪЭМФЃаЭжаЕФзюДѓПЩФмадМЦЫуЮЪЬтзЊЛЏЮЊЕфаЭЕФзюДѓЛЏМгШЈПЩТњзуадЮЪЬтЃЌЕЋЛљгкMarkovЭјНјааЪЕЬхБцЮіЪБЃЌашвЊЖЈвхвЛЯЕСаЕФЕШМлЮНДЪЙЋРэЃЌЭЈЙ§ЫќУЧЭъГЩжЊЪЖПтЕФМЏЬхЪЕЬхЖдЦыЁЃ
3.2 жЊЪЖМгЙЄ
ЭЈЙ§ЪЕЬхЖдЦыЃЌПЩвдЕУЕНвЛЯЕСаЕФЛљБОЪТЪЕБэДяЛђГѕВНЕФБОЬхГћаЮЃЌШЛЖјЪТЪЕВЂВЛЕШгкжЊЪЖЃЌЫќжЛЪЧжЊЪЖЕФЛљБОЕЅЮЛЁЃвЊаЮГЩИпжЪСПЕФжЊЪЖЃЌЛЙашвЊОЙ§жЊЪЖМгЙЄЕФЙ§ГЬЃЌДгВуДЮЩЯаЮГЩвЛИіДѓЙцФЃЕФжЊЪЖЬхЯЕЃЌЭГвЛЖджЊЪЖНјааЙмРэЁЃжЊЪЖМгЙЄжївЊАќРЈБОЬхЙЙНЈгыжЪСПЦРЙРСНЗНУцЕФФкШнЁЃ
1ЃЉБОЬхЙЙНЈ
БОЬхЪЧЭЌвЛСьгђФкВЛЭЌжїЬхжЎМфНјааНЛСїЁЂСЌЭЈЕФгявхЛљДЁЃЌЦфжївЊГЪЯжЪїзДНсЙЙЃЌЯрСкЕФВуДЮНкЕуЛђИХФюжЎМфОпгабЯИёЕФЁАIsAЁБЙиЯЕЃЌгаРћгкНјаадМЪјЁЂЭЦРэЕШЃЌШДВЛРћгкБэДяИХФюЕФЖрбљадЁЃБОЬхдкжЊЪЖЭМЦзжаЕФЕиЮЛЯрЕБгкжЊЪЖПтЕФФЃОпЃЌЭЈЙ§БОЬхПтЖјаЮГЩЕФжЊЪЖПтВЛНіВуДЮНсЙЙНЯЧПЃЌВЂЧвШпгрГЬЖШНЯаЁЁЃ |








