| БрМЭЦМі: |
БОЮФжївЊНщЩмжЊЪЖЭМЦзЕФбаОПБГОАМАЦфвтвхЃЌжЊЪЖЭМЦзЕФЗЂеЙЁЂЖЈвх
ДѓЙцФЃжЊЪЖПт ЙиМќММЪѕЁЂ ЕфаЭгІгУвдМАжЊЪЖЭМЦзЕФЮЪЬтгыЬєеНЁЃ
БОЮФРДздгкВЉПЭдАЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
жЊЪЖЭМЦзММЪѕЪЧШЫЙЄжЧФмММЪѕЕФживЊзщГЩВПЗжЃЌвдНсЙЙЛЏЕФЗНЪНУшЪіПЭЙлЪРНчжаЕФИХФюЁЂЪЕЬхМАЦфМќЕФЙиЯЕЁЃжЊЪЖЭМЦзЬсММЪѕЬсЙЉСЫвЛжжИќКУЕФзщжЏЁЂЙмРэКЭРэНтЛЅСЊЭјКЃСПаХЯЂЕФФмСІЃЌНЋЛЅСЊЭјЕФаХЯЂБэДяГЩИќНгНќгкШЫРрШЯжЊЪРНчЕФаЮЪНЁЃвђДЫЃЌНЈСЂвЛИіОпгагявхДІРэФмСІгыПЊЗХЛЅСЊФмСІЕФжЊЪЖПтЃЌПЩвддкжЧФмЫбЫїЁЂжЧФмЮЪД№ЁЂИіадЛЏЭЦМіЕШжЧФмаХЯЂЗўЮёжиВњЩњгІгУМлжЕЁЃ
жЊЪЖЭМЦзЕФбаОПБГОАМАЦфвтвх
ЕЅЕЅДгзжУцЩЯРэНтЃЌжЊЪЖЭМЦзгІИУЪЧвЛжжИќМгНсЙЙЛЏЃЈжївЊЪЧЛљгкЭМЃЉЕФжЊЪЖПтЃЌНЋЩЂТвЕФжЊЪЖгааЇЕФзщжЏЦ№РДЃЌЗНБуШЫУЧЕФВщдФЃЌЖјВЛЪЧжЎЧАФЧбљвЛЖбЮФдкАкдкблЧАЃЌУЛгавЛФПСЫШЛЕФИЯНХ,ЙўЙўЙўЁЃЫљвдЃЌКмШнвзЯыЕНЃЌжЊЪЖЭМЦзЕФВњЩњБГОАОЭЪЧЃЌЕквЛЗНУцЛЅСЊЭјаХЯЂЕФБЉдіЃЌвдМАаХЯЂЕФдгТвЮоеТЃЌЕквЛИівтвхОЭЪЧЮЊСЫШЫУЧИќМгПьЫйгааЇЕФМьЫїФГвЛаХЯЂЁЃЃЌЕкЖўЗНУцЃЌЫцзХЯждкПЦбЇММЪѕЕФНјВНгыЗЂеЙЃЌКмЖрЯШНјММЪѕЖМгІдЫЖјЩњЃЈБШШчЩюЖШбЇЯАЃЉЃЌШЫУЧЦкЭћЛњЦїЯёШЫвЛбљПЩвдШЅРэНтКЃСПЕФЭјТчаХЯЂЃЌЦкЭћПЩвдИќПьЁЂзМШЗЁЂжЧФмЕФЛёШЁЕНздМКашвЊЕФаХЯЂЃЌЮЊСЫТњзуетжжашЧѓЃЌжЧФмЛЏЕФжЊЪЖЭМЦзгІдЫЖјЩњЃЌЦфбаОПвтвхЛЙЪЧдкгкЗНБуШЫРрЃЁ(гаФОгаЗЂЯжЃЌМИКѕЫљгаЕФбаОПвтвхЖМЪЧетЫФИізжФХ)ЃЈдкетРяЮвжЛЪЧгУвЛжжМђЕЅРэНтЕФЗНЪНРДБэДяЃЌЕБШЛЛЙгаИќЖрЕФбаОПвтвхЃЌжЛВЛЙ§жЊЪЖЭМЦзИеИеПЊЪМЛ№ШШЦ№РДЕФЪБКђЃЌОЭЪЧгІгУдкаХЯЂМьЫїЗНУцЁЃЮЊСЫШнвзРэНтвдМАЗНБуМЧвфЃЌМЧзЁетИіОЭokСЫ)
вЛАуЧщПіЯТбаОПБГОАОЭЬхЯжСЫбаОПвтвхЁЃвдЯТЪЧЙйЭјгябдУшЪіЃЌЗЧЭъУРжївхепПЩвдЬјЙ§етаЉЗБЫіЕФЮФзжБэДяЃЌЙўЙўЙўЁЃ
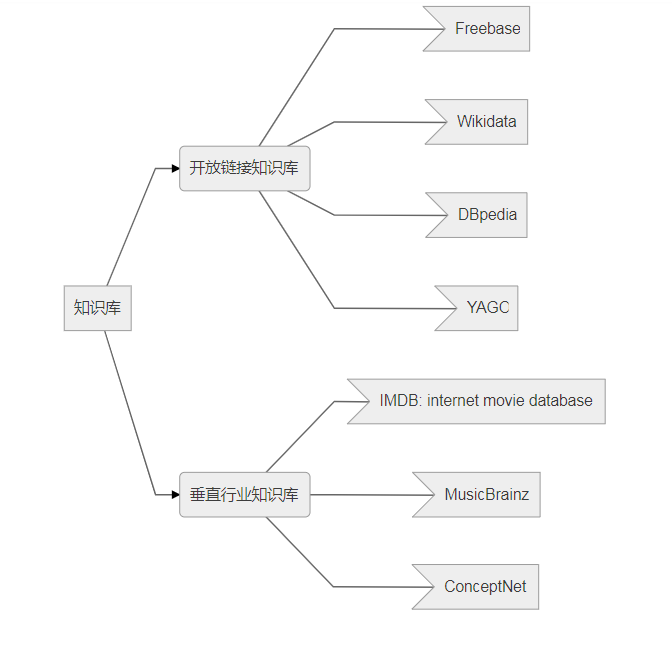
АщЫцзХwebММЪѕЕФВЛЖЯбнНјгыЗЂеЙЃЌШЫРрЯШКѓОРњСЫвдЮФЕЕЛЅСЊЮЊжївЊЬиеїЕФЁАweb
1.0ЁБЪБДњЃЌвдЪ§ОнЛЅСЊЮЊЬиеїЕФЁАweb 2.0ЁБЪБДњЃЌе§дкТѕЯђЛљгкжЊЪЖЛЅСЊЕФеИаТЁАWeb 3.0ЁБЪБДњЁЃ
жЊЪЖЛЅСЊЭјЕФФПБъЪЧЙЙНЈвЛИіШЫгыЛњЦїЖМПЩвдРэНтЕФЭђЮЌЭј,ЪЙЕУШЫУЧЕФЭјТчИќМгжЧФмЛЏЁЃШЛЖјЃЌгЩгкЭђЮЌЭјЩЯЕФФкШнЖрдДвЛжБЃЌзщжЏНсЙЙЫЩЩЂЃЌИјДѓЪ§ОнЛЗОГЯТЕФжЊЪЖЛЅСЊДјРДСЫМЋДѓЕФЬєеНЁЃвђДЫЃЌШЫУЧашвЊИљОнДѓЪ§ОнЛЗОГЯТЕФжЊЪЖзщжЏддђЃЌДгаТЕФЪгНЧШЅЬНЫїМШЗћКЯЭјТчаХЯЂзЪдДЗЂеЙБфЛЏгжФмЪЪгІгУЛЇШЫжЎашЧѓЕФжЊЪЖЛЅСЊЗНЗЈЃЌДгИќЩюВуДЮЩЯНвЪОШЫРрШЯжЊЕФећЬхадЙиСЊадЁЃжЊЪЖЭМЦзвдЦфЧПДѓЕФгявхДІРэФмСІгыПЊЗХЛЅСЊФмСІ,ЪЙweb
3.0ЬсГіЕФЁАжЊЪЖжЎЭјЁБдЖОАГЩЮЊСЫПЩФмЁЃ
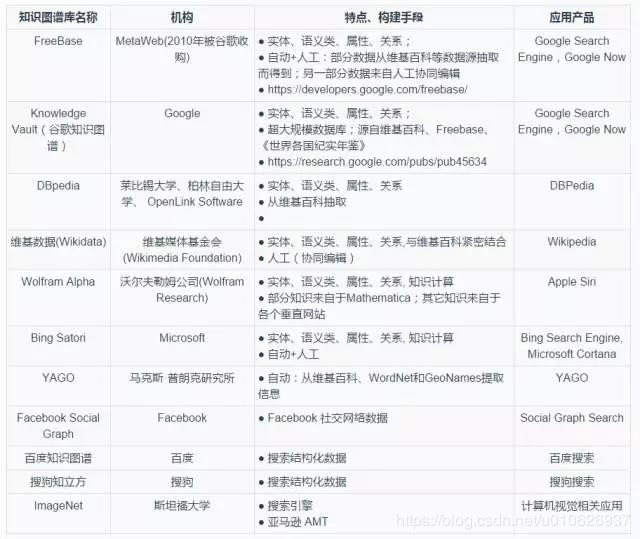
НјШы21ЪРМЭЃЌЫцзХЛЅСЊЭјЕФХюВЊЗЂеЙвдМАжЊЪЖЕФБЌеЈЪНдіГЄЃЌЫбЫїв§ЧцБЛЙуЗКЪЙгУЁЃДЋЭГЕФЫбЫїв§ЧцММЪѕФмЙЛИљОнгУЛЇВщбЏПьЫйХХађЭјвГЃЌЬсИпаХЯЂМьЫїЕФаЇТЪЁЃШЛЖјЃЌетжжЭјвГМьЫїаЇТЪВЂВЛвтЮЖетгУЛЇФмЙЛПьЫйзМШЗЕФЛёШЁаХЯЂКЭжЊЪЖЃЌЖдгкЫбЫїв§ЧцЗЕЛиЕФДѓСПНсЙћЛЙашвЊНјааШЫЙЄХХВщКЭЩИбЁЁЃУцЖдЛЅСЊЭјЩЯВЛЖЯдіМгЕФКЃСПаХЯЂЃЌЭјвГМьЫїЗНЪНЃЈНіАќКЌЭјвГКЭЭјвГжЎМфСДНгЕФДЋЭГЮФЕЕЃЉвбОВЛФмТњзуШЫУЧбИЫйЛёШЁЫљашаХЯЂКЭШЋУцеЦЮеаХЯЂзЪдДЕФашЧѓЁЃЮЊСЫТњзуетжжашЧѓЃЌжЊЪЖЭМЦзММЪѕгІдЫЖјЩњЁЃЫќУЧСІЧѓЭЈЙ§НЋжЊЪЖНјааИќМггаађЁЂгаЛњЕФзщжЏЦ№РДЃЌЪЙгУЛЇПЩвдИќМгПьЫйЁЂзМШЗЕиЗУЮЪздМКашвЊЕФжЊЪЖаХЯЂЃЌВЂНјаавЛЖЈЕФжЊЪЖЭкОжКЭжЧФмОіВпЁЃДгЛњЙЙжЊЪЖПтЕНЛЅСЊЭјЫбЫїв§ЧцЃЌНќФъРДВЛЩйбЇепКЭЛњЙЙЗзЗздкжЊЪЖЭМЦзЩЯЩюШыбаОПЃЌЯЃЭћвдетжжИќМгЧхЮњЁЂЖЏЬЌЕФЗНЪНЃЈзЂЃКжЊЪЖЭМЦзвЛЖЈЪЧЖЏЬЌЕФЃЌВЛЖЯИќаТЕФЃЌВЛЪЧОВжЙЕФЃЌВЛШЛЃЌОЭЪЧШЅСЫЦфеце§ЕФвтвхЃЉеЙЯжИїжжИХФюжЎМфЕФСЊЯЕЃЌЪЕЯжжЊЪЖЕФжЧФмЛёШЁКЭЙмРэЁЃ
жЊЪЖЭМЦзЕФЗЂеЙ
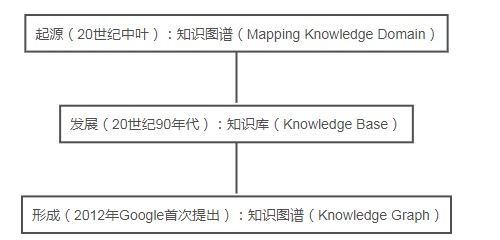
20ЪРМЭжавЖЃЌЦеРГЫЙЕШШЫЬсГіЪЙгУв§ЮФЭјТчРДбаОПЕБДњПЦбЇЗЂеЙЕФТіТчЕФЗНЗЈЃЌЪзДЮЬсГіСЫжЊЪЖЭМЦзЕФИХФюЁЃЃЈзЂвтЃКетРяЕФжЊЪЖЭМЦзКЭБОВЉЮФжївЊНщЩмЕФжЊЪЖЭМЦзВЛЬЋвЛбљЃЌдкДЫЪЧжИMapping
Knowledge DomainЃЌЖјБОВЉЮФжївЊНщЩмЕФжЊЪЖЭМЦзЪЧжИKnowledge GraphЃЉ1977ФъЃЌжЊЪЖЙЄГЬЕФИХФюдкЕкЮхНьЙњМЪШЫЙЄжЧФмДѓЛсЩЯБЛЬсГіЃЌвдзЈМвЯЕЭГЮЊДњБэЕФжЊЪЖПтЯЕЭГПЊЪМБЛЙуЗКбаОПКЭгІгУЃЌжБЕН20ЪРМЭ90ФъДњЃЌЛњЙЙжЊЪЖПтЕФИХФюБЛЬсГіЃЌздДЫЙигкжЊЪЖБэЪОЁЂжЊЪЖзщжЏЕФбаОПЙЄзїПЊЪМЩюШыПЊеЙЦ№РДЁЃЛњЙЙжЊЪЖПтЯЕЭГБЛЙуЗКгІгУгкИїПЦбаЛњЙЙКЭЕЅЮЛФкВПЕФзЪСЯећКЯвдМАЖдЭтаћДЋЙЄзїЁЃ2012Фъ11дТGoogleЙЋЫОТЪЯШЬсГіжЊЪЖЭМЦзЃЈKnowledge
GraphЃЌKGЃЉЕФИХФюЃЌБэЪОНЋдкЦфЫбЫїНсЙћжаМгШыжЊЪЖЭМЦзЕФЙІФмЁЃЦфГѕждЪЧЮЊСЫЬсИпЫбЫїв§ЧцЕФФмСІЃЌдіЧПгУЛЇЕФЫбЫїжЪСПвдМАЫбЫїЬхбщЁЃОн2015Фъ1дТЭГМЦЕФЪ§ОнЃЌGoogle
ЙЙНЈЕФKGвбОгЕга5вкИіЪЕЬхЃЌдМ35вкЬѕЪЕЬхЙиЯЕаХЯЂЃЌвбОБЛЙуЗКгІгУгкЬсИпЫбЫїв§ЧцЕФЫбЫїжЪСПЁЃЫфШЛжЊЪЖЭМЦзЃЈKnowledge
GraphЃЉЕФИХФюНЯаТЃЌЕЋЫќВЂЗЧЪЧвЛИіШЋаТЕФбаОПСьгђЃЌдчдк2006ФъЃЌBerners LeeОЭЬсГіСЫЪ§ОнСДНгЃЈlinked
dataЃЉЕФЫМЯыЃЌКєгѕЭЦЙуКЭЭъЩЦЯрЙиЕФММЪѕБъзМШчURI(Uniform resource identifier)ЃЌRDF(resource
discription framework),OWLЃЈWeb ontology languageЃЉЃЌЮЊгНггявхЭјТчЕФЕНРДзіКУзМБИЁЃЫцКѓЯЦЦ№СЫвЛГЁгявхЭјТчбаОПЕФШШГБЃЌжЊЪЖЭМЦзММЪѕе§ЪЧНЈСЂдкЯрЙиЕФбаОПГЩЙћжЎЩЯЕФЃЌЪЧЖдЯжгагявхЭјТчММЪѕЕФвЛДЮбяЦњКЭЩ§ЛЊЁЃ
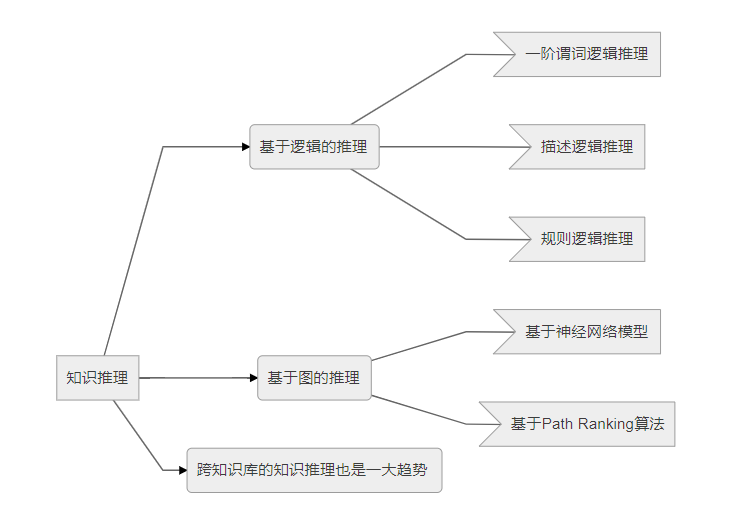
жЊЪЖЭМЦзЕФЖЈвх
дкЮЌЛљАйПЦЕФЙйЗНДЪЬѕжаЃКжЊЪЖЭМЦзЪЧGoogleгУгкдіЧПЦфЫбЫїв§ЧцЙІФмЕФжЊЪЖПтЁЃБОжЪЩЯЃЌжЊЪЖЭМЦзЪЧвЛжжНвЪОЪЕЬхжЎМфЙиЯЕЕФгявхЭјТчЃЌПЩвдЖдЯжЪЕЪРНчЕФЪТЮяМАЦфЯрЛЅЙиЯЕНјаааЮЪНЛЏЕиУшЪіЁЃЯждкЕФжЊЪЖЭМЦзвбБЛгУРДЗКжИИїжжДѓЙцФЃЕФжЊЪЖПтЁЃПЩзїШчЯТЖЈвхЃК
жЊЪЖЭМЦз ЃКЪЧНсЙЙЛЏЕФгявхжЊЪЖПтЃЌгУгквдЗћКХаЮЪНУшЪіЮяРэЪРНчжаЕФИХФюМАЦфЯрЛЅЙиЯЕЁЃЦфЛљБОзщГЩЕЅЮЛЪЧЁАЪЕЬх
ЙиЯЕ ЪЕЬхЁБШ§дЊзщЃЌвдМАЪЕЬхМАЦфЯрЙиЪєаджЕЖдЃЌЪЕЬхМфЭЈЙ§ЙиЯЕЯрЛЅСЊНсЃЌЙЙГЩЭјзДЕФжЊЪЖНсЙЙЁЃ
Ш§дЊзщЪЧжЊЪЖЭМЦзЕФвЛжжЭЈгУБэЪОЗНЪНЃЌМДGЁЪ(E,R,S)G \in
(E,R, S)GЁЪ(E,R,S)ЃЌЦфжаE={e1,e2,...,eЈOEЈO}E= \{e_1 ,e_2
,...,e_{|E|} \}E={e 1,e 2 ,...,e ЈOEЈO }ЪЧжЊЪЖПтжаЕФЪЕЬхМЏКЯЃЌЙВАќКЌ|
E |жжВЛЭЌЪЕЬхЃЛ R={r1,r2,...,rЈORЈO}R= \{r_1 ,r_2 ,...,r_{|R|}
\}R={r 1 ,r 2 ,...,r ЈORЈO}ЪЧжЊЪЖПтжаЕФЙиЯЕМЏКЯЃЌЙВАќКЌ| R |жжВЛЭЌЙиЯЕЃЛS?EЁСRЁСES
\subseteq E \times R\times ES?EЁСRЁСE ДњБэжЊЪЖПтжаЕФШ§дЊзщМЏКЯЁЃШ§дЊзщЕФЛљБОаЮЪНжївЊАќРЈЪЕЬх1ЁЂЙиЯЕЁЂЪЕЬх2КЭИХФюЁЂЪєадЁЂЪєаджЕЕШЃЌЪЕЬхЪЧжЊЪЖЭМЦзжаЕФзюЛљБОдЊЫиЃЌВЛЭЌЕФЪЕЬхМфДцдкВЛЭЌЕФЙиЯЕЁЃИХФюжївЊжИМЏКЯЁЂРрБ№ЁЂЖдЯѓРраЭЁЂЪТЮяЕФжжРрЃЌР§ШчШЫЮяЁЂЕиРэЕШЃЛЪєаджївЊжИЖдЯѓПЩФмОпгаЕФЪєадЁЂЬиеїЁЂЬиадЁЂЬиЕувдМАВЮЪ§ЃЌР§ШчЙњМЎЁЂЩњШеЕШЃЛЪєаджЕжївЊжИЖдЯѓжИЖЈЪєадЕФжЕЃЌР§ШчжаЙњЁЂ1988-09-08ЕШЁЃУПИіЪЕЬх(ИХФюЕФЭтбг)ПЩгУвЛИіШЋОжЮЈвЛШЗЖЈЕФIDРДБъЪЖЃЌУПИіЪєад-ЪєаджЕЖд(attribute-value
pairЃЌAVP)ПЩгУРДПЬЛЪЕЬхЕФФкдкЬиадЃЌЖјЙиЯЕПЩгУРДСЌНгСНИіЪЕЬхЃЌПЬЛЫќУЧжЎМфЕФЙиСЊЁЃ
дкДЫЃЌжЊЪЖЭМЦзАќКЌШ§ВуКЌвхЃК
жЊЪЖЭМЦзБОЩэЪЧвЛИіОпгаЪєадЕФЪЕЬхЭЈЙ§ЙиЯЕСДНгЖјГЩЕФЭјзДжЊЪЖПтЃЎДгЭМЕФНЧЖШРДПДЃЌжЊЪЖЭМЦздкБОжЪЩЯЪЧвЛжжИХФюЭјТчЃЌЦфжаЕФНкЕуБэЪОЮяРэЪРНчЕФЪЕЬхЃЈЛђИХФюЃЉЃЌЖјЪЕЬхМфЕФИїжжгявхЙиЯЕдђЙЙГЩЭјТчжаЕФБпЃЎгЩДЫЃЌжЊЪЖЭМЦзЪЧЖдЮяРэЪРНчЕФвЛжжЗћКХБэДя
.
жЊЪЖЭМЦзЕФбаОПМлжЕдкгкЃЌЫќЪЧЙЙНЈдкЕБЧАЃзebЛљДЁжЎЩЯЕФвЛВуИВИЧЭјТчЃЈoverlay networkЃЉЃЌНшжњжЊЪЖЭМЦзЃЌФмЙЛдкЃзЃхЃтЭјвГжЎЩЯНЈСЂИХФюМфЕФСДНгЙиЯЕЃЌДгЖјвдзюаЁЕФДњМлНЋЛЅСЊЭјжаЛ§РлЕФаХЯЂзщжЏЦ№РДЃЌГЩЮЊПЩвдБЛРћгУЕФжЊЪЖЁЃ
жЊЪЖЭМЦзЕФгІгУМлжЕдкгкЃЌЫќФмЙЛИФБфЯжгаЕФаХЯЂМьЫїЗНЪНЃЌвЛЗНУцЭЈЙ§ЭЦРэЪЕЯжИХФюМьЫїЃЈЯрЖдгкЯжгаЕФзжЗћДЎФЃК§ЦЅХфЗНЪНЖјбдЃЉЃЛСэвЛЗНУцвдЭМаЮЛЏЗНЪНЯђгУЛЇеЙЪООЙ§ЗжРрећРэЕФНсЙЙЛЏжЊЪЖЃЌДгЖјЪЙШЫУЧДгШЫЙЄЙ§ТЫЭјвГбАевД№АИЕФФЃЪНжаНтЭбГіРДЁЃ
#жЊЪЖЭМЦзЕФМмЙЙ
дкДЫжївЊИјГіМИИіГЃМћЕФжЊЪЖЭМЦзМмЙЙЭМЃЌетМИИіЭМДѓЭЌаЁвьЃЌЭЈЙ§ПДЭМПЩвдвЛФПСЫШЛЕФРэНтЃЌУтШЅСЫЮФзжЕФЗБЫіНщЩмЁЃ
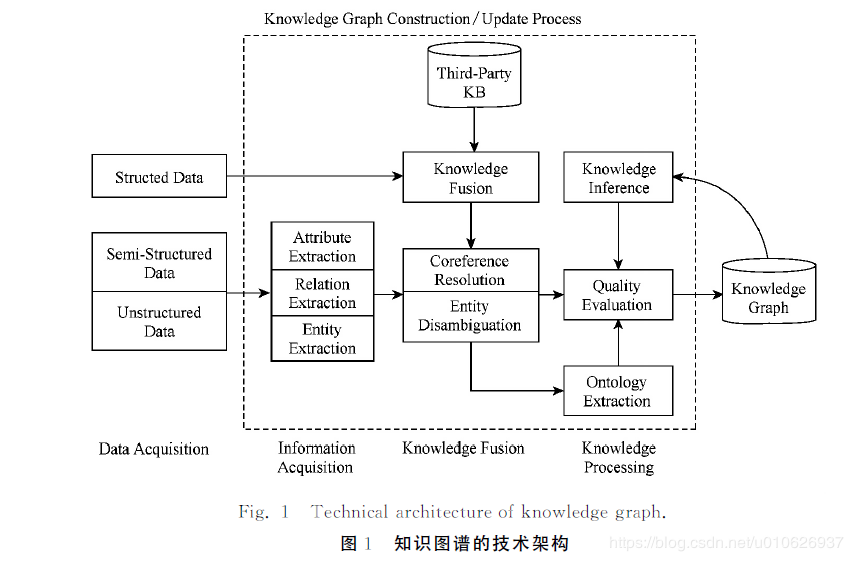
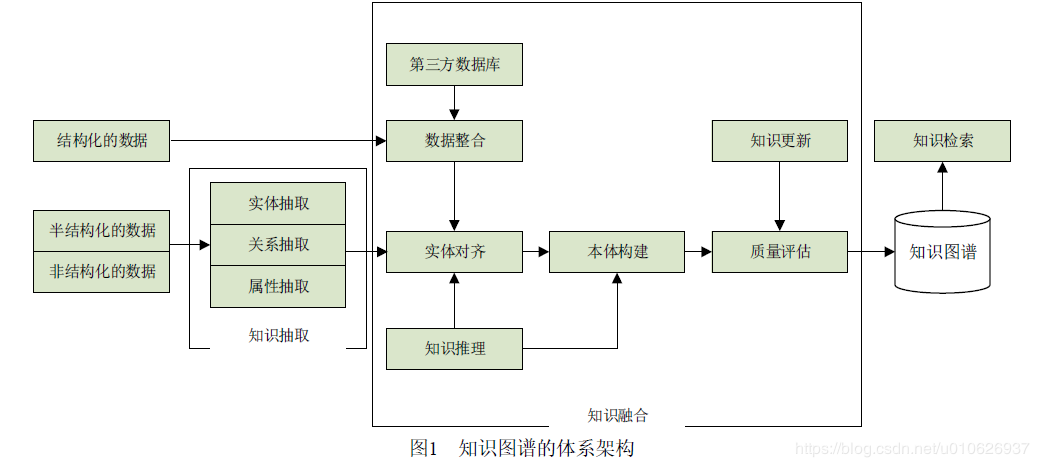
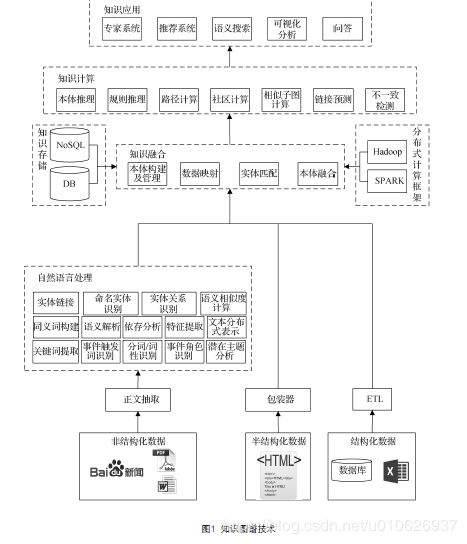
жЊЪЖЭМЦзМмЙЙжївЊВПЗжЃК
- жЊЪЖГщШЁЃЈАќРЈЪЕЬхГщШЁЁЂЙиЯЕГщШЁвдМАЪєадГщШЁЕШЃЉ
- жЊЪЖШкКЯЃЈАќРЈЪЕЬхЯћсЊЕШЃЉ
- жЊЪЖМгЙЄЃЈАќРЈБОЬхЙЙМмЁЂжЊЪЖЭЦРэЕШЃЉ
- жЊЪЖИќаТ
ДѓЙцФЃжЊЪЖПт
ОпЬхЕФПЩвдВЮМгЯТЭМЃК
жЊЪЖЭМЦзЙиМќММЪѕ
етвЛВПЗжЪЧБОЮФЕФжиЕуЃЌЧАУцЖМЪЧашвЊЛљБОСЫНтЕФжЊЪЖЭМЦзЛљДЁжЊЪЖЃЌетвЛВПЗжЪЧКЫаФвВЪЧжївЊЕФбаОПЮЪЬтЁЃЦфЪЕжЊЪЖЭМЦзЕФЙиМќММЪѕжївЊЪЧЮЇШЦзХНЈСЂвЛИіИпжЪСПЕФжЊЪЖЭМЦзЫљеЙПЊЬжТлЕФЁЃдкДЫжївЊЪЧвЛИіМђЕЅЕФзмНсЃЌБугкДѓМвЕФРэНтгыМЧвфЁЃ
жЊЪЖГщШЁЃЈЛђепаХЯЂГщШЁЃЉ
ЪЕЬхГщШЁ
ЙиЯЕГщШЁ
ЪєадГщШЁЃЈЪЕжЪЩЯЪєадГщШЁвВПЩвдПДзїЪЧЙиЯЕГщШЅЃЉ
жЊЪЖШкКЯ
ЪЕЬхСЌНг
ЪЕЬхЯћсЊЈCзЈУХгУгкНтОіЭЌУћЪЕЬхВњЩњЦчвхЮЪЬтЕФММЪѕЁЃЪЕЬхЯћсЊжївЊВЩгУОлРрЕФЗНЗЈЃЌОлРрЗЈЯћЦчЕФЙиМќЮЪЬтЪЧШчКЮЖЈвхЪЕЬхЖдЯѓгыжИГЦЯюжЎМфЕФЯрЫЦЖШЃЌГЃгУЕФЗНЗЈгаЃКЁЖ1ЁЗПеМфЯђСПФЃаЭЃЈДЪДќФЃаЭЃЉЁЖ2ЁЗгявхФЃаЭЃЈгыПеМфЯђСПФЃаЭЯрЫЦЃЌВЛЭЌЕФЕиЗНдкгкгявхФЃаЭВЛНіАќКЌДЪДќЯђСПЃЌЖјЧвАќКЌвЛВПЗжгявхЬиеїЃЉЁЖ3ЁЗЩчЛсЭјТчФЃаЭЃЈИУФЃаЭЕФЛљБОМйЩшЪЧЮявдРрОлШЫвдШКЗжЃЌдкЩчЛсЛЏЛЗОГжаЃЌЪЕЬхжИГЦЯюЕФвтвхдкКмДѓГЬЖШЩЯЪЧгЩгыЦфЯрЙиСЊЕФЪЕЬхЫљОіЖЈЕФЃЉЁЖ4ЁЗАйПЦжЊЪЖФЃаЭЃЈАйПЦРрЭјеОЭЈГЃЛсЮЊУПИіЪЕЬхЗжХфвЛИіЕЅЖРвГУцЃЌЦфжаАќРЈжИЯђЦфЫћЪЕЬхвГУцЕФСЌНгЃЌАйПЦжЊЪЖФЃаЭе§ЪЧРћгУетжжСДНгЙиЯЕРДМЦЫуЪЕЬхжИГЦЯюжЎМфЕФЯрЫЦЖШЃЉ
ЪЕЬхЖдЦыЈCжївЊгУгкЯћГ§вьЙЙЪ§ОнжаЪЕЬхГхЭЛЁЂжИЯђВЛУїЕШВЛвЛжТадЮЪЬтЃЌПЩвдДгЖЅВуДДНЈвЛИіДѓЙцФЃЕФЭГвЛжЊЪЖПтЃЌДгЖјАяжњЛњЦїРэНтЖрдДвьжЪЕФЪ§ОнЃЌаЮГЩИпжЪСПЕФжЊЪЖПтЁЃЖдЦыЫуЗЈПЩвдЗжЮЊГЩЖдЪЕЬхЖдЦыКЭМЏЬхЪЕЬхЖдЦыЃЌЖјМЏЬхЪЕЬхЖдЦыгжПЩвдЗжЮЊОжВПМЏЬхЪЕЬхЖдЦыКЭШЋОжМЏЬхЪЕЬхЖдЦыЁЃГЩЖдЪЕЬхЖдЦыЃКЁЖ1ЁЗЛљгкДЋЭГИХТЪФЃаЭЕФЪЕЬхЖдЦыЗНЗЈЁЃЁЖ2ЁЗЛљгкЛњЦїбЇЯАЕФЪЕЬхЖдЦыЗНЗЈЁЃОжВПЪЕЬхЖдЦыЗНЗЈЃКОжВПЪЕЬхЖдЦыЗНЗЈЮЊЪЕЬхБОЩэЕФЪєадвдМАгыЫќгаЙиСЊЕФЪЕЬхЕФЪєадЗжБ№ЩшжУВЛЭЌЕФШЈжиЃЌВЂЭЈЙ§МгШЈЧѓКЭМЦЫузмЬхЕФЯрЫЦЖШЃЌЛЙПЩвдЪЙгУЯђСППеМфФЃаЭвдМАгрЯвЯрЫЦадРДХаБ№ДѓЙцФЃжЊЪЖПтжаЕФЪЕЬхЕФЯрЫЦГЬЖШЃЌЫуЗЈЮЊУПИіЪЕЬхНЈСЂСЫУћГЦЯђСПгыащФтЮФЕЕЯђСПЃЌУћГЦЯђСПгУгкБъЪЖЪЕЬхЕФЪєадЃЌащФтЮФЕЕЯђСПдђгУгкБэЪОЪЕЬхЕФЪєаджЕвдМАЦфСкОгНкЕуЕФЪєаджЕЕФМгШЈКЭжЕЁЃШЋОжМЏЬхЪЕЬхЖдЦыЗНЗЈЃКЁЖ1ЁЗЛљгкЯрЫЦадДЋВЅЕФМЏЬхЪЕЬхЖдЦыЗНЗЈЁЃЁЖ2ЁЗЛљгкИХТЪФЃаЭЕФМЏЬхЪЕЬхЖдЦыЗНЗЈ
ЪЕЬхСДНгММЪѕвВПЩвдДгећЬхВуУцЗжРрШчЯТЃК
жЊЪЖКЯВЂ
КЯВЂЭтВПжЊЪЖПтЁЊНЋЭтВПжЊЪЖПтШкКЯЕНБОЕижЊЪЖПташвЊДІРэ2ИіВуУцЕФЮЪЬтЁЃЁЖ1ЁЗЪ§ОнВуЕФШкКЯЃЌАќРЈЪЕЬхЕФжИГЦЁЂЪєадЁЂЙиЯЕвдМАЫљЪєРрБ№ЕШЃЌжївЊЕФЮЪЬтЪЧШчКЮБмУтЪЕР§вдМАЙиЯЕЕФГхЭЛЮЪЬтЃЌдьГЩВЛБивЊЕФШпгрЁЃЁЖ2ЁЗЭЈЙ§ФЃЪНВуЕФШкКЯЃЌНЋаТЕУЕНЕФБОЬхШкШывбгаЕФБОЬхПтжаЁЃ
КЯВЂЙиЯЕЪ§ОнПтЁЊдкжЊЪЖЭМЦзЕФЙЙНЈЙ§ГЬжаЃЌвЛИіживЊЕФИпжЪСПжЊЪЖРДдДЪЧЦѓвЕЛђепЛњЙЙздМКЕФЙиЯЕЪ§ОнПтЁЃЮЊСЫНЋетаЉНсЙЙЛЏЕФРњЪЗЪ§ОнШкШыЕНжЊЪЖЭМЦзжаЃЌПЩвдВЩгУзЪдДУшЪіПђМмЃЈRDFЃЉзїЮЊЪ§ОнФЃаЭЁЃвЕНчКЭбЇЪѕНчНЋетвЛЪ§ОнзЊЛЛЙ§ГЬаЮЯѓЕФГЦЮЊRDB2RDFЃЌЦфЪЕжЪОЭЪЧНЋЙиЯЕЪ§ОнПтЕФЪ§ОнзЊЛЛГЩRDFЕФШ§дЊзщЪ§ОнЁЃ
жЊЪЖМгЙЄ
БОЬхЙЙНЈЁЊБОЬхЕФзюДѓЬиЕудкгкЫќЪЧЙВЯэЕФЃЌБОЬхжаЗДгГЕФжЊЪЖЪЧвЛжжУїШЗЖЈвхЕФЙВЪЖЁЃБОЬхЪЧЭЌвЛСьгђФкВЛЭЌжїЬхжЎМфНјааНЛСїЕФгявхЛљДЁЃЌБОЬхЪЧЪїзДНсЙЙЃЌЯрСкВуДЮЕФНкЕуЃЈИХФюЃЉжЎМфОпгабЯИёЕФЁАIsAЁБЙиЯЕЃЌетжжЕЅДПЕФЙиЯЕгаРћгкжЊЪЖЭЦРэШДВЛРћгкБэДяИХФюЕФЖрбљадЁЃБОЬхЕФЙЙНЈПЩвдВЩгУШЫЙЄБрМЕФЗНЪНЪжЖЏЙЙНЈЃЈНшжњгкБОЬхБрМШэМўЃЉЃЌвВПЩвдВЩгУМЦЫуЛњИЈжњЃЌвдЪ§ОнЧ§ЖЏЕФЗНЪНздЖЏЙЙНЈЃЌШЛКѓВЩгУЫуЗЈЦРЙРКЭШЫЙЄЩѓКЫЯрНсКЯЕФЗНЪНМгвдаое§КЭШЗШЯЁЃГ§СЫЪ§ОнЧ§ЖЏЕФЗНЗЈЃЌЛЙПЩвдВЩгУПчгябджЊЪЖСДНгЕФЗНЗЈРДЙЙНЈБОЬхПтЁЃЖдЕБЧАБОЬхЩњГЩЗНЗЈЕФжївЊбаОПЙЄзїжївЊМЏжадкЪЕЬхОлРрЗНЗЈЃЌжївЊЬєеНдкгкОЙ§аХЯЂГщШЁЕУЕНЕФЪЕЬхУшЪіЗЧГЃМђЖЬЃЌШБЗІБивЊЕФЩЯЯТЮФаХЯЂЃЌЕМжТЖрЪ§ЭГМЦФЃаЭВЛПЩгУЁЃЃЈПЩвдРћгУжїЬтНјааВуДЮОлРрЃЉЁЃ
жЊЪЖЭЦРэЁЊжЊЪЖЭЦРэЪЧжИДгжЊЪЖПтжавбгаЕФЪЕЬхЙиЯЕЪ§ОнГіЗЂЃЌОЙ§МЦЫуЛњЭЦРэЃЌНЈСЂЪЕЬхМфЕФаТЙиСЊЃЌДгЖјЭиеЙКЭЗсИЛжЊЪЖЭјТчЃЌжЊЪЖЭЦРэЪЧжЊЪЖЭМЦзЙЙНЈЕФживЊЪжЖЮКЭЙиМќЛЗНкЃЌЭЈЙ§жЊЪЖЭЦРэЃЌФмЙЛДгЯжгажЊЪЖжаЗЂЯжаТЕФжЊЪЖЁЃжЊЪЖЭЦРэЕФЗНЗЈШчЯТЭМЃК
жЪСПЦРЙРЁЊЖджЊЪЖПтЕФжЪСПЦРЙРШЮЮёЭЈГЃЪЧгыЪЕЬхЖдЦыШЮЮёвЛЦ№НјааЕФЃЌЦфвтвхдкгкЃЌПЩвдЖджЊЪЖЕФПЩаХЖШНјааСПЛЏЃЌБЃСєжУаХЖШНЯИпЕФЃЌЩсЦњжУаХЖШНЯЕЭЕФЃЌгааЇБЃжЄжЊЪЖЕФжЪСПЁЃ
жЊЪЖИќаТ
ШЫРрЫљгЕгааХЯЂКЭжЊЪЖСПЖМЪЧЪБМфЕФЕЅЕїЕндіЕФКЏЪ§ЃЌвђДЫжЊЪЖЭМЦзЕФФкШнвВашвЊгыЪБОуНјЃЌЦфЙЙНЈЙ§ГЬЪЧвЛИіВЛЖЯЕќДњИќаТЕФЙ§ГЬЁЃДгТпМЩЯПДЃЌжЛЪЧПоЕФИќаТАќРЈИХФюВуИќаТКЭЪ§ОнВуИќаТЁЃжЊЪЖЭМЦзФкШнЕФИќаТгаСНжжЗНЪНЃКЪ§ОнЧ§ЖЏЯТЕФШЋУцИќаТКЭдіСПИќаТЁЃ
жЊЪЖБэЪО
ЫфШЛШ§дЊзщЕФжЊЪЖБэЪОаЮЪНЪмЕНСЫШЫУЧЕФЙуЗКШЯПЩЃЌЕЋЪЧЦфдкМЦЫуаЇТЪЁЂЪ§ОнЯЁЪшадЕШЗНУцШДУцСйзХжюЖрЮЪЬтЁЃНќФъРДЃЌвдЩюЖШбЇЯАЮЊДњБэЕФбЇЯАММЪѕШЁЕУСЫживЊЕФНјеЙЃЌПЩвдНЋЪЕЬхЕФгявхаХЯЂБэЪОЮЊГэУмЕЭЮЌЕФЪЕжЕЯђСПЃЌНјЖјдкЕЭЮЌПеМфжаИпаЇМЦЫуЪЕЬхЁЂЙиЯЕМАЦфжЎМфЕФИДдггявхЙиСЊЃЌЖджЊЪЖПтЕФЙЙНЈЁЂЭЦРэЁЂШкКЯвдМАгІгУОљОпгаживЊЕФвтвхЁЃЗжВМЪНБэЪОжМдкгУвЛИізлКЯЕФЯђСПРДБэЪОЪЕЬхЖдЯѓЕФгявхаХЯЂЃЌЪЧвЛжжФЃЗТШЫФдЙЄзїЕФБэЪОЛњжЦЃЌЭЈЙ§жЊЪЖБэЪОЖјЕУЕНЕФЗжВМЪНБэЪОаЮЪНдкжЊЪЖЭМЦзЕФМЦЫуЁЂВЙШЋЁЂЭЦРэЕШЗНУцЦ№ЕНживЊЕФзїгУЃКгявхЯрЫЦЖШМЦЫуЁЂСДНгдЄВтЃЈгжБЛГЦЮЊжЊЪЖЭМЦзВЙШЋЃЉЕШДњБэФЃаЭШчЯТЫљЪОЃК
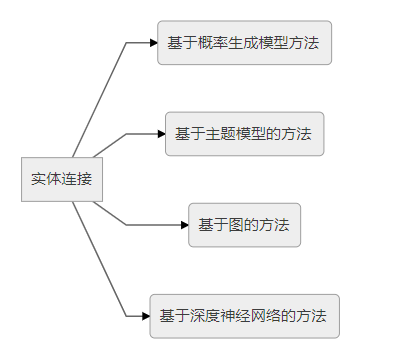
ОрРыФЃаЭ
ЪзЯШНЋЪЕЬхгУЯђСПНјааБэЪОЃЌШЛКѓЭЈЙ§ЙиЯЕОиеѓНЋЪЕЬхЭЖгАЕНгыЪЕЬхЯђСПЭЌвЛЮГЖШЕФЯђСППеМфжаЃЌзюКѓЭЈЙ§МЦЫуЭЖгАЯђСПжЎМфЕФОрРыРДХаЖЯЪЕЬхМфвбОДцдкЕФЙиЯЕЕФжУаХЖШЁЃгЩгкОрРыФЃаЭжаЕФЙиЯЕОиеѓЪЧСНИіВЛЭЌЕФОиеѓЃЌЙЪЪЕЬхМфЕФаЭЌадНЯВюЃЌетвВЪЧИУФЃаЭБОЩэЕФжївЊШБЯнЁЃ
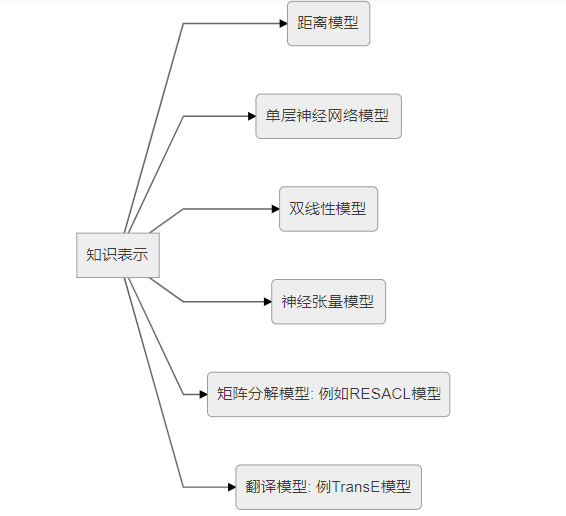
ЕЅВуЩёОЭјТч
еыЖдОрРыФЃаЭЕФШБЯнЃЌЬсГіСЫВЩгУЕЅВуЩёОЭјТчЕФЗЧЯпадФЃаЭЃЈsingle layer modelЃЌSLMЃЉЁЃЕЅВуЩёОЭјТчФЃаЭЕФЗЧЯпадВйзїЫфШЛФмЙЛНјвЛВНПЬЛЪЕЬхдкЙиЯЕЯТЕФгявхЯрЙиадЃЌЕЋЪЧдкМЦЫуПЊЯњЩЯШДДѓДѓдіМгЁЃ
ЫЋЯпадФЃаЭ
ЫЋЯпадФЃаЭгжНавўБфСПФЃаЭЃЈlatent factor modelЃЌLFMЃЉЁЃЫЋЯпадФЃаЭжївЊЪЧЭЈЙ§ЛљгкЪЕЬхМфЙиЯЕЕФЫЋЯпадБфЛЛРДПЬЛЪЕЬхдкЙиЯЕЯТЕФгявхЯрЙиадЃЌФЃаЭВЛНіаЮЪНМђЕЅЁЂвзгкМЦЫуЃЌЖјЧвФмЙЛгааЇПЬЛЪЕЬхМфЕФаЭЌадЁЃ
ЩёОеХСПФЃаЭ
ЦфЛљБОЫМЯыЪЧЃЌдкВЛЭЌЮЌЖШЯТЃЌНЋЪЕЬхСЊЯЕЦ№РДЃЌБэЪОЪЕЬхМфИДдгЕФгявхСЊЯЕЁЃЩёОеХСПФЃаЭдкЙЙНЈЪЕЬхЕФЯђСПБэЪОЪБЃЌЪЧНЋИУЪЕЬхжаЕФЫљгаЕЅДЪЕФЯђСПШЁЦНОљжЕЃЌетбљвЛЗНУцПЩвджиИДЪЙгУЕЅДЪЯђСПЙЙНЈЪЕЬхЃЌСэвЛЗНУцНЋгаРћгкдіЧПЕЭЮЌЯђСПЕФГэУмГЬЖШвдМАЪЕЬхгыЙиЯЕЕФгявхМЦЫуЁЃ
ОиеѓЗжНтФЃаЭ
ЭЈЙ§ОиеѓЗжНтЕФЗНЪНПЩвдЕУЕНЕЭЮЌЕФЯђСПБэЪОЃЌЙЪВЛЩйбаОПепЬсГіПЩвдВЩгУИУЗНЪННјаажЊЪЖБэЪОбЇЯАЃЌЦфжаЕфаЭЕФДњБэЪЧRESACLФЃаЭЁЃ
ЗвыФЃаЭ
ЪмЕНЦНвЦБфЯжЯѓЕФЦєЗЂЃЌЬсГіСЫTransEФЃаЭЃЌМДНЋжЊЪЖПтжаЪЕЬхжЎМфЕФЙиЯЕПДГЩЪЧДгЪЕЬхМфЕФФГжжЦНвЦЃЌВЂгУЯђСПБэЪОЁЃЙиЯЕlrl_rl
rПЩвдПДзїЪЧДгЭЗЪЕЬхЯђСПlhl_hl hЕНЮВЪЕЬхЯђСПltl_tl tЕФЗвыЁЃИУФЃаЭЕФВЮЪ§НЯЩйЃЌМЦЫуЕФИДдгЖШЯджјНЕЕЭЃЌЭЌЪБЃЌTransEФЃаЭдкДѓЙцФЃЯЁЪшЪ§ОнПтЩЯвВЭЌбљОпгаНЯКУЕФадФмгыПЩРЉеЙадЁЃ
ИДдгЙиЯЕФЃаЭ
жЊЪЖПтжаЕФЪЕЬхЙиЯЕРраЭПЩЗжЮЊЃК1-to-1ЁЂ1-to-NЁЂN-to-1ЁЂN-to-N 4жжРраЭЁЃДњБэадФЃаЭгаЃКTransHФЃаЭЁЂTransRФЃаЭЁЂTransDФЃаЭЁЂTransGФЃаЭЁЂKG2EФЃаЭЁЃ
жЊЪЖЭМЦзЕФЕфаЭгІгУ
жЊЪЖЭМЦзЮЊЛЅСЊЭјЩЯКЃСПЁЂвьЙЙЁЂЖЏЬЌЕФДѓЪ§ОнБэДяЁЂзщжЏЁЂЙмРэвдМАРћгУЬсЙЉСЫвЛжжИќЮЊгааЇЕФЗНЪНЃЌЪЙЕУЭјТчЕФжЧФмЛЏЫЎЦНИќИпЃЌИќМгНгНќгкШЫРрЕФШЯжЊЫМЮЌЁЃ
жЧФмЫбЫї
ЩюЖШЮЪД№
ЩчНЛЭјТч
ИіадЛЏЭЦМі
ДЙжБаавЕгІгУЃЌР§Шч Н№ШкаавЕЁЂвНСЦаавЕЁЂЕчЩЬаавЕвдМАНЬг§аавЕЕШЕШЁЃ
жЊЪЖЭМЦзЕФЮЪЬтгыЬєеН
жЊЪЖГщШЁ
жЊЪЖГщШЁЪЧжЊЪЖЭМЦззщжЏЙЙНЈЁЂНјааЮЪД№МьЫїЕФжївЊШЮЮёЃЌЖдгкЩюВугявхЕФРэНтвдМАДІРэОпгаживЊЕФвтвхЁЃвЛаЉДЋЭГЕФжЊЪЖдЊЫи(ЪЕЬхЁЂЙиЯЕЁЂЪєад)ГщШЁММЪѕгыЗНЗЈЃЌЫќУЧдкЯоЖЈСьгђЁЂжїЬтЕФЪ§ОнМЏЩЯЛёЕУСЫНЯКУЕФаЇЙћЃЌЕЋгЩгкжЦдМЬѕМўНЯЖрЃЌЫуЗЈзМШЗадКЭейЛиТЪЕЭЃЌЗНЗЈЕФПЩРЉеЙФмСІВЛЙЛЧПЃЌЮДФмКмКУЕиЪЪгІДѓЙцФЃЁЂСьгђЖРСЂЁЂИпаЇЕФПЊЗХЪНаХЯЂГщШЁвЊЧѓЁЃ
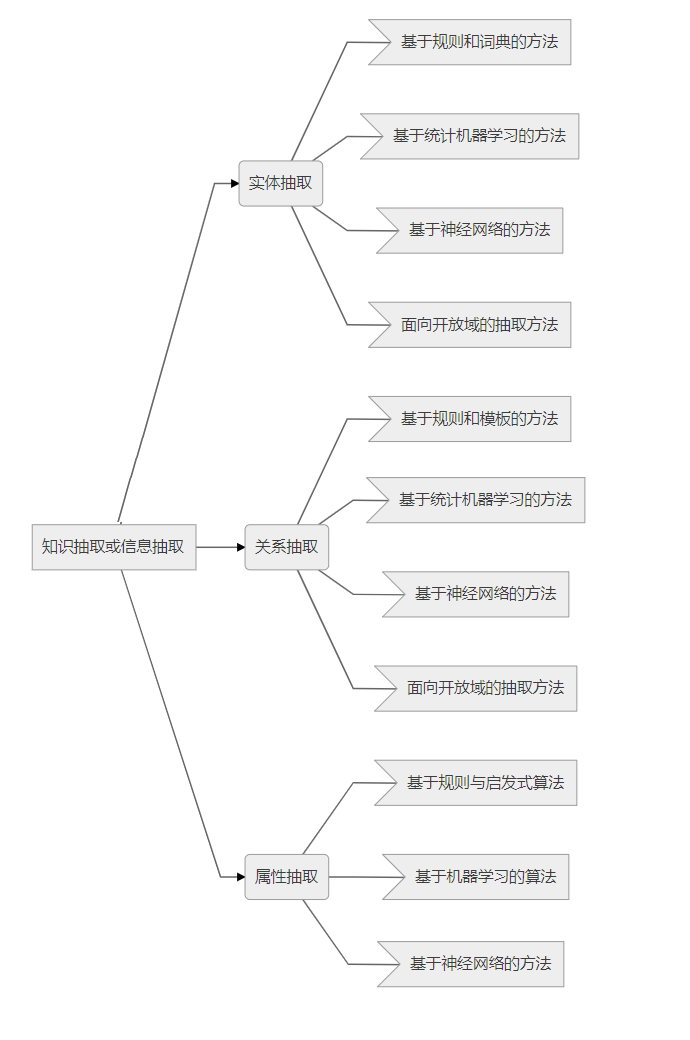
ФПЧАЃЌЛљгкДѓЙцПЊЗХгђЕФжЊЪЖГщШЁбаОПШдДІгкЦ№ВННзЖЮЃЌЩаашбаОПепХЌСІШЅЙЅЙиПЊПбЁЃжївЊЮЪЬтАќРЈЪЕЬхГщШЁЁЂЙиЯЕГщШЁвдМАЪєадГщШЁЁЃЦфжаЃЌЖргяжжЁЂПЊЗХСьгђЕФДПЮФБОаХЯЂГщШЁЮЪЬтЪЧЕБЧАУцСйЕФживЊЬєеНЁЃ
KnowItAllЁЂTextRunnerЁЂWOEЁЂReVerbЁЂR2A2ЁЂKPAKENетаЉЯЕЭГвбЮЊПЊЗХгђЛЗОГЯТЃЌЪЕЬхЙиЯЕГщШЁжаЕФЖўдЊЙиЯЕГщШЁЁЂnдЊЙиЯЕГщШЁЗЂеЙПЊДДСЫЯШКгЃЌОпгаЙуРЋЕФбаОПЧАОАЁЃдйепЃЌЖдгквўКЌЙиЯЕЕФГщШЁЃЌФПЧАжїСїЕФПЊЗХЪНаХЯЂГщШЁЗНЗЈадФмЕЭЯТЛђЩаЮоЗЈЪЕЯжЁЃвђДЫЃЌвдТэЖћПЩЗђТпМЭјЁЂБОЬхЭЦРэЕФСЊКЯЭЦРэЗНЗЈНЋГЩЮЊбЇЪѕНчЕФбаОПШШЕуЁЃ
СЊКЯЭЦРэЗНЗЈВЛНіФмЙЛЭЦЖЯЮФБОгяСЯЫљВЛФмЯдЪОЕФЩюВувўКЌаХЯЂЃЌЛЙФмЙЛзлКЯаХЯЂГщШЁИїНзЖЮЕФзгШЮЮёЃЌЯёИмИЫвЛбљдкИїЗНУцжЎМфбАЧѓЦНКтЃЌвдЧїЯђећЬхЯђЩЯЕФРэЯыаЇЙћЃЌЮЊДѓЙцФЃПЊЗХгђЯТЕФжЊЪЖГщШЁЬсЙЉСЫвЛжжаТЕФЫМТЗЁЃГ§ЩЯЪіЭтЃЌПчгябдЕФжЊЪЖГщШЁЗНЗЈвВГЩЮЊСЫЕБЧАЕФбаОПШШЕуЃЌЖдгкЮвЙњЕФбаОПепЖјбдЃЌИќгІЗЂЛгздЩэдкжаЮФаХЯЂДІРэЗНУцЕФЬьШЛгХЪЦЃЌУцЖдЬєеНгыЛњгіЃЌзіГігІгаЕФЙБЯзЁЃ
жЊЪЖБэЪО
ФПЧАДцдкЕФБэЪОЗНЪНШдЪЧЛљгкШ§дЊзщаЮЪНЭъГЩЕФгявхгГЩфЃЌдкУцЖдИДдгЕФжЊЪЖРраЭЁЂЖрдДШкКЯЕФаХЯЂЪБЃЌЦфБэДяФмСІШдШЛгаЯоЁЃвђДЫгабаОПепЬсГіЃЌгІеыЖдВЛЭЌЕФгІгУГЁОАЩшМЦВЛЭЌЕФжЊЪЖБэЪОЗНЗЈЁЃ
ИДдгЙиЯЕжаЕФжЊЪЖБэЪО
вбгаЕФЙЄзїНЋжЊЪЖПтжаЕФЪЕЬхЙиЯЕРраЭЗжЮЊ1-to-1ЁЂ1-to-NЁЂN-to-1ЁЂN-to-Nет4жжЃЌетжжЛЎЗжЗНЗЈЮоЗЈжБЙлЕиНтЪЭжЊЪЖЕФБОжЪРраЭЬиЕуЃЌвВЮоЗЈИќгаеыЖдадЕиБэЪОИДдгЙиЯЕжаЕФжЊЪЖЁЃ
ЕЋЗЂЯжЗжВМЪНЕФжЊЪЖБэЪОЗНЗЈРДдДгкШЯжЊПЦбЇЃЌОпгаСщЛюЕФПЩРЉеЙФмСІЁЃЛљгкЩЯЪіЃЌЖдШЯжЊПЦбЇСьгђШЫРржЊЪЖРраЭЕФЬНЫїНЋгажњгкжЊЪЖРраЭЕФЛЎЗжЁЂБэЪОвдМАДІРэЃЌЪЧЮДРДжЊЪЖБэЪОбаОПЕФживЊЗЂеЙЗНЯђЁЃ
ЖрдДаХЯЂШкКЯжаЕФжЊЪЖБэЪО
**ЖдгкЖрдДаХЯЂШкКЯжаЕФжЊЪЖБэЪОбаОПЩаДІгкЦ№ВННзЖЮЃЌЩцМАЕФаХЯЂРДдДвВМЋЮЊгаЯоЃЌвбгаЕФЩйЪ§ЙЄзїЖМЪЧЮЇШЦЮФБОгыжЊЪЖПтЕФШкКЯЖјеЙПЊЕФЁЃ**СэЭтЃЌвбгаЮФЯзНЋзЂвтСІзЊЯђУцЯђЙиЯЕБэЪОЕФЖрдДаХЯЂШкКЯСьгђЃЌВЂвбдкCNNЩЯНјааСЫвЛЖЈЕФЪЕЯжЁЃдкжЊЪЖШкКЯБэЪОжаЃЌШкКЯЪЧзюЙиМќЕФЧАЦкВНжшЃЌШчФмгаЛњЕФШкКЯЖрдДвьжЪЕФЪЕЬхЁЂЙиЯЕЕШаХЯЂЃЌНЋгаРћгкНјвЛВНЬсЩ§жЊЪЖБэЪОФЃаЭЕФЧјЗжФмСІвдМАадФмЁЃЛљгкЪЕЬхЕФЁЂЙиЯЕЕФЁЂWebЮФБОЕФЁЂЖржЊЪЖПтЕФШкКЯОљОпгаНЯЮЊЙуРЋЕФбаОПЧАОАЁЃ
жЊЪЖШкКЯ
жЊЪЖШкКЯЖдгкжЊЪЖЭМЦзЕФЙЙНЈЁЂБэЪООљОпгаживЊЕФвтвхЁЃЪЕЬхЖдЦы ЪЧжЊЪЖШкКЯжаЕФЙиМќВНжшЃЌЫфШЛЯрЙибаОПвбШЁЕУСЫЗсЫЖЕФГЩЙћЃЌЕЋШдгаЙуРЋЕФЗЂеЙПеМфЃЌШчЯТЃК
ВЂаагыЗжВМЪНЫуЗЈ
ДѓЙцФЃЕФжЊЪЖПтВЛНідЬКЌСЫКЃСПЕФжЊЪЖЃЌЦфНсЙЙЁЂЪ§ОнЬиеївВМЋЦфИДдгЃЌетаЉЖджЊЪЖПтЪЕЬхЖдЦыЫуЗЈЕФзМШЗТЪЁЂжДаааЇТЪЬсГіСЫвЛЖЈЕФЬєеНЁЃФПЧАЃЌВЛЩйбаОПепе§зХСІбаОПЖдЦыЫуЗЈЕФВЂааЛЏЛђЗжВМЪНАцБОЃЌдкМцЙЫЫуЗЈзМШЗТЪгыейЛиТЪЕФЭЌЪБЃЌНЋНјвЛВНРћгУВЂааБрГЬЛЗОГMPIЃЌЗжВМЪНМЦЫуПђМмHadoopЁЂSparkЕШЦНЬЈЃЌЬсЩ§жЊЪЖПтЖдЦыЕФећЬхаЇЙћЁЃ
жкАќЫуЗЈ
ШЫЛњНсКЯЕФжкАќЫуЗЈПЩвдгааЇЕиЬсИпжЊЪЖШкКЯЕФжЪСПЁЃжкАќЫуЗЈЕФЩшМЦНВЧѓЪ§ОнСПЁЂжЊЪЖПтЖдЦыжЪСПвдМАШЫЙЄБъзЂШ§епЕФШЈКтЁЃНЋжкАќЦНЬЈгыжЊЪЖПтЖдЦыФЃаЭгаЛњНсКЯЦ№РДЃЌВЂЧвФмЙЛгааЇХаБ№ШЫЙЄБъзЂЕФжЪСПЃЌетаЉОљОпгаНЯЮЊЙуРЋЕФбаОПЧАОАЁЃ
ПчгябджЊЪЖПтЖдЦы
ЖргябдЕФжЊЪЖПтдНРДдНЖрЃЌЖргябджЊЪЖПтЕФЛЅВЙФмСІНЋЮЊжЊЪЖЭМЦздкЖргябдЫбЫїЁЂЮЪД№ЁЂЗвыЕШСьгђЕФЪЕМЪгІгУЬсЙЉИќЖрЕФПЩФмЁЃ
ЮФЯзвбдкетЗНУцШЁЕУСЫвЛЖЈЕФНјеЙЃЌЕЋжЊЪЖПтЖдЦыЕФжЪСПВЛИпЃЌетЗНУцШдгаЙуРЋЕФбаОППеМфЁЃ
злжЎЃЌжївЊЕФбаОПЮЪЬтАќРЈПЊЗХгђЬѕМўЯТЕФЪЕЬхЯћЦчЁЂЙВжИЯћНтЁЂЭтВПжЊЪЖПтШкКЯКЭЙиЯЕЪ§ОнПтжЊЪЖШкКЯЕШЮЪЬтЃЎЕБЧАЪмЕНбЇЪѕНчЦеБщЙизЂЕФЮЪЬтЪЧШчКЮдкЩЯЯТЮФаХЯЂЪмЯоЃЈЖЬЮФБОЁЂПчгяОГЁЂПчСьгђЕШЃЉЬѕМўЯТЃЌзМШЗЕиНЋДгЮФБОжаГщШЁЕУЕНЕФЪЕЬхе§ШЗСДНгЕНжЊЪЖПтжаЖдгІЕФЪЕЬхЃЎ
жЊЪЖМгЙЄ
жЊЪЖМгЙЄЪЧзюОпЬиЩЋЕФжЊЪЖЭМЦзММЪѕЃЌЭЌЪБвВЪЧИУСьгђзюДѓЕФЬєеНжЎЫљдкЃЎжївЊЕФбаОПЮЪЬтАќРЈЃКБОЬхЕФздЖЏЙЙНЈЁЂжЊЪЖЭЦРэММЪѕЁЂжЊЪЖжЪСПЦРЙРЪжЖЮвдМАЭЦРэММЪѕЕФгІгУЃЎФПЧАЃЌБОЬхЙЙНЈЮЪЬтЕФбаОПНЙЕуЪЧОлРрЮЪЬтЃЌЖджЊЪЖжЪСПЦРЙРЮЪЬтЕФбаОПдђжївЊЙизЂНЈСЂЭъЩЦЕФжЪСПЦРЙРММЪѕБъзМКЭжИБъЬхЯЕЃЎжЊЪЖЭЦРэЕФЗНЗЈКЭгІгУбаОПЪЧЕБЧАИУСьгђзюЮЊРЇФбЃЌЭЌЪБвВЪЧзюЮЊЮќв§ШЫЕФЮЪЬтЃЌашвЊЭЛЦЦЯжгаММЪѕКЭЫМЮЌЗНЪНЕФЯожЦЃЌжЊЪЖЭЦРэММЪѕЕФДДаТвВНЋЖджЊЪЖЭМЦзЕФгІгУВњЩњЩюдЖгАЯьЃЎ
жЊЪЖИќаТ
дкжЊЪЖИќаТЛЗНк, діСПИќаТММЪѕЪЧЮДРДЕФЗЂеЙЗНЯђЃЌШЛЖјЯжгаЕФжЊЪЖИќаТММЪѕбЯживРРЕШЫЙЄИЩдЄЃЎПЩвддЄМћЫцзХжЊЪЖЭМЦзЕФВЛЖЯЛ§РлЃЌвРППШЫЙЄжЦЖЈИќаТЙцдђКЭж№ЬѕМьЪгЕФОЩФЃЪННЋЛсж№ВННЕЕЭБШжиЃЌздЖЏЛЏГЬЖШНЋВЛЖЯЬсИпЃЌШчКЮШЗБЃздЖЏЛЏИќаТЕФгааЇадЃЌЪЧИУСьгђУцСйЕФгжвЛжиДѓЬєеН
жЊЪЖгІгУ
ФПЧАЃЌДѓЙцФЃжЊЪЖЭМЦзЕФгІгУГЁОАКЭЗНЪНЛЙБШНЯгаЯоЃЌЦфдкжЧФмЫбЫїЁЂЩюЖШЮЪД№ЁЂЩчНЛЭјТчвдМАЦфЫћаавЕжаЕФЪЙгУвВ**жЛЪЧДІгкГѕМЖНзЖЮЃЌ**ШдОпгаЙуРЋЕФПЩРЉеЙПеМфЁЃШЫУЧдкЭкОђашЧѓЁЂЬНЫїжЊЪЖЭМЦзЕФгІгУГЁОАЪБЃЌгІГфЗжПМТЧжЊЪЖЭМЦзЕФвдЯТгХЪЦЃК1)
ЖдКЃСПЁЂвьЙЙЁЂЖЏЬЌЕФАыНсЙЙЛЏЁЂЗЧНсЙЙЛЏЪ§ОнЕФгааЇзщжЏгыБэДяФмСІЃЛ2) вРЭагкЧПДѓжЊЪЖПтЕФЩюЖШжЊЪЖЭЦРэФмСІЃЛ3)
гыЩюЖШбЇЯАЁЂРрФдПЦбЇЕШСьгђЯрНсКЯЃЌж№ВНРЉеЙЕФШЯжЊФмСІЁЃ дкЖджЊЪЖЭМЦзММЪѕгаЗсИЛЛ§РлЕФЛљДЁЩЯЃЌУєШёЕФИажЊШЫУЧЕФашЧѓЃЌПЩЮЊДѓЙцФЃжЊЪЖЭМЦзЕФгІгУевЕНИќПэЙуЁЂИќКЯЪЪЕФгІгУжЎЕРЁЃ
ЦфЫћ
зюОпЛљДЁбаОПМлжЕЕФЬєеНЪЧШчКЮНтОіжЊЪЖЕФБэДяЁЂДцДЂгыВщбЏЮЪЬтЃЌетИіЮЪЬтНЋАщЫцжЊЪЖЭМЦзММЪѕЗЂеЙЕФЪМжеЃЌЖдИУЮЪЬтЕФНтОіНЋЗДЙ§РДгАЯьЧАУцЬсГіЕФЬєеНКЭЙиМќЮЪЬтЃЎЕБЧАЕФжЊЪЖЭМЦзжївЊВЩгУЭМЪ§ОнПтНјааДцДЂЃЌдкЪмвцгкЭМЪ§ОнПтДјРДЕФВщбЏаЇТЪЕФЭЌЪБЃЌвВЪЇШЅСЫЙиЯЕаЭЪ§ОнПтЕФгХЕуЃЌШчЃгЃбЃЬгябджЇГжКЭМЏКЯВщбЏаЇТЪЕШЃЎдкВщбЏЗНУцЃЌШчКЮДІРэздШЛгябдВщбЏЃЌЖдЦфНјааЗжЮіЭЦРэЃЌЗвыГЩжЊЪЖЭМЦзПЩРэНтЕФВщбЏБэДяЪНвдМАЕШМлБэДяЪНЕШвВЖМЪЧжЊЪЖЭМЦзгІгУашНтОіЕФЙиМќЮЪЬтЃЎ
змНс
жЊЪЖЭМЦзЕФживЊадВЛНідкгкЫќЪЧвЛИіШЋОжжЊЪЖПтЃЌЪЧжЇГХжЧФмЫбЫїКЭЩюЖШЮЪД№ЕШжЧФмгІгУЕФЛљДЁЃЌЖјЧвдкгкЫќЪЧвЛАбдПГзЃЌФмЙЛДђПЊШЫРрЕФжЊЪЖБІПтЃЌЮЊаэЖрЯрЙибЇПЦСьгђПЊЦєаТЕФЗЂеЙЛњЛсЁЃ
ДгетИівтвхЩЯПДРДЃЌжЊЪЖЭМЦзВЛНіЪЧвЛЯюММЪѕЃЌИќЪЧвЛЯюеНТдзЪВњЁЃБОЮФЕФжївЊФПЕФОЭЪЧНщЩмКЭаћДЋетЯюММЪѕЃЌЯЃЭћЮќв§ИќЖрЕФШЫжиЪгКЭЭЖШыетЯюбаОПЙЄзїЁЃ
|








