| 编辑推荐: |
本文主要给大家分享了LSTM,从感知器开始,把这个流程中的主要知识点展示出来,希望能给大家带来一些帮助。
本文来自于搜狐网,由火龙果软件Alice编辑、推荐。
|
|
目的是将LSTM用在分词和词性标注任务,这一篇的目的是LSTM,但从感知器开始写起,希望能把这个流程中的主要知识点展示出来。由于水平有限,所以涉及大量公式的地方都会是从我看过的资料中截图过来,我会在文末放出文章的链接,供参考。
感知器——基础的全连接网络——线性单元到线性模型——梯度下降——神经网络和反向传播算法——循环神经网络——LSTM——LSTM-CRF
1.感知器(Perception)
“感知器”一词出自于20世纪50年代中期到60年代中期人们对一种分类学习机模型的称呼,它是属于有关动物和机器学习的仿生学领域中的问题。当时的一些研究者认为感知器是一种学习机的强有力模型,后来发现估计过高了,但发展感知器的一些相关概念仍然沿用下来。
感知器算法实质上是一种赏罚过程:
–对正确分类的模式则“赏”,实际上是“不罚”,即权向量不变。
–对错误分类的模式则“罚”,使w(k)加上一个正比于xk的分量。
–当用全部模式样本训练过一轮以后,只要有一个模式是判别错误的,则需要进行下一轮迭代,即用全部模式样本再训练一次。
–如此不断反复直到全部模式样本进行训练都能得到正确的分类结果为止。

可以用感知器实现and、or这些简单的布尔运算,感知器还可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。布尔运算可以看作是二分类问题,即给定一个输入,输出0(属于分类0)或1(属于分类1)。但是感知器不能实现异或运算,异或运算不是线性的,你无法用一条直线把分类0和分类1分开。
感知器的训练
总的来说是先随机给个权值,然后利用训练集反复训练权值,最后得到能够正确分类所有样例的权向量。
具体算法过程如下:
w是权重,b是偏置项,t是实际值,y是预测值
1.初始化权向量w=(w0,w1,…,wn),将权向量的每个值赋一个随机值或者都赋值为0
2.对于每个训练样例,首先计算其预测值,实际值减去预测值与学习率相乘,再根据上方公式来调整权重,没处理一个样本就调整一次权重值,经过多轮迭代后(即全部的训练数据被反复处理多轮),就可以训练出感知器的权重,使之实现目标函数。

2.线性单元到线性模型和梯度下降
上文介绍的感知器算法它的阶跃函数输出是0或1,他只能处理分类问题,不能处理线性不可分的数据,也就是不能在线性不可分的数据上收敛,为了解决这个问题,我们使用一个可导的线性函数来替代感知器的阶跃函数,这种感知器就叫做线性单元。线性单元在面对线性不可分的数据集时,会收敛到一个最佳的近似上。
这样使用线性单元替代感知器的阶跃函数后,线性单元将会返回一个实数值而不是0或1,因此说线性单元用来解决回归问题而不是分类问题。
线性模型
f(x)=ω1x1+ω2x2+...+ωdxd+b;(b为偏置单元)这就是一个线性模型基本的表达式,每个属性x都有一个自己的权重w,我们用向量形式表示:
f(x)=ωTx+b;其中ω=(ω1;ω2;...;ωd),ω和b是学习得到的,确定后模型就确定了。
接下来我们要知道这个模型该怎么训练,也就是参数w都该去什么值,这里引入监督学习和无监督学习,无监督学习是只有x没有y,全靠模型总结出x的规律。
而监督学习是说我们既有x又有y,我们先提供大量的训练样本(既有x又有y),我们用这样的数据去训练模型,让他从已知的数据中学习到其中x与y的关系,就是确定w的值,最后确定整体模型。
接下来我们考虑监督学习的训练算法——梯度下降。
当前的线性模型中在已知数据中由x求得y1,这里的y1是模型给出的预测值,我们还有x的实际值y,这里y和y1我们希望越接近越好,我们用y1和y的差的平方的1/2来表示他们的接近程度:








小结
一个机器学习算法往往只需要两部分:
1.模型从输入特征x预测输入y的那个函数H(x)
2.目标函数去最小(最大)值时所对应的参数值,就是模型的参数的最优值,很多时候我们只能获得目标函数的局部最小(最大)值,因此也只能得到模型参数的局部最优值
接下来,用优化算法去求取目标函数的最小(最大)值,梯度下降算法就是一个优化算法,针对同一个目标函数,不同的优化算法会推导出不同的训练规则。
在机器学习中,往往算法并不是关键,真正的关键之处在于选特征,选特征需要我们人类对问题的深刻理解、经验和思考,而神经网络算法的一个优势,就在于它能够自动学习到应该提取什么特征,从而使算法不再那么依赖人类。
神经网络和反向传播算法神经元
神经元和感知器本质上是一样的,只不过我们说感知器的时候,它的激活函数是阶跃函数;而当我们说神经元时,激活函数往往选择为sigmoid函数或tanh函数。如下图所示:



圆圈表示神经元,+1节点表示偏置节点,也就是截距项,最左边的一层是输入层,最右的一层叫做输出层,中间所有的节点叫做隐藏层,同一层的神经元没有链接,第N层的每个神经元和第N-1层的所有神经元相连(这就是full
connected的含义),第N-1层神经元的输出就是第N层神经元的输入,每个连接都有一个权值。
上面这些规则定义了全连接神经网络的结构。事实上还存在很多其它结构的神经网络,比如卷积神经网络(CNN)、循环神经网络(RNN),他们都具有不同的连接规则。
神经网络的输出
神经网络实际上就是一个输入向量x到输出向量y的函数,即:



反向传播算法
现在,我们需要知道一个神经网络的每个连接上的权值是如何得到的。我们可以说神经网络是一个模型,那么这些权值就是模型的参数,也就是模型要学习的东西。然而,一个神经网络的连接方式、网络的层数、每层的节点数这些参数,则不是学习出来的,而是人为事先设置的。对于这些人为设置的参数,我们称之为超参数(Hyper-Parameters)。
按照机器学习的通用套路,我们先确定神经网络的目标函数,然后用随机梯度下降优化算法去求目标函数最小值时的参数值。
我们取网络所有输出层节点的误差平方和作为目标函数:

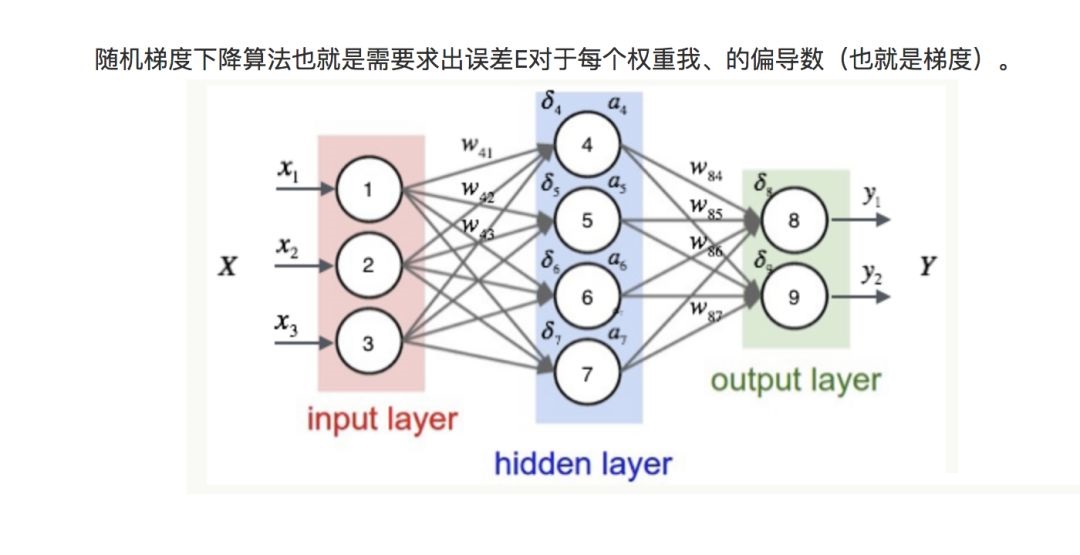



至此,我们已经推导出了反向传播算法。需要注意的是,我们刚刚推导出的训练规则是根据激活函数是sigmoid函数、平方和误差、全连接网络、随机梯度下降优化算法。如果激活函数不同、误差计算方式不同、网络连接结构不同、优化算法不同,则具体的训练规则也会不一样。但是无论怎样,训练规则的推导方式都是一样的,应用链式求导法则进行推导即可。
循环神经网络
下图是一个简单的循环神经网络如,它由输入层、一个隐藏层和一个输出层组成:

循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
如果我们把上面的图展开,循环神经网络也可以画成下面这个样子:


环神经网络的隐藏层不仅取决于当前的输入x,还取决于上一个时刻隐藏层的输出,这个处理目的是为了解决时间序列问题,比如分词、词性标注这些语言模型,一句话不仅取决于当前的输入,还与前后的数据有关系,但循环神经网络只与前一刻的输入建立了联系,下一刻的数据没有建立联系,所以我们还需要双向的循环神经网络,充分考虑序列的前后时刻,
双向循环神经网络


循环神经网络的训练是很复杂的,但它的基础还是反向传播,因为我不做技术开发,所以这篇文章不涉及双向循环神经网络的训练算法。
LSTM
双向的循环神经网络训练的具体技术不涉及,它的缺点是很难处理长距离的依赖,隐藏层太深后,网络就会损失长距离的信息,训练过程中容易出现梯度消失和梯度爆炸问题,所以引入了LSTM。
长短时记忆网络的思路比较简单。原始RNN的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。那么,假如我们再增加一个状态,即c,让它来保存长期的状态,那么问题不就解决了么?如下图所示:

上图仅仅是一个示意图,我们可以看出,在t时刻,LSTM的输入有三个:当前时刻网络的输入值x、上一时刻LSTM的输出值H、以及上一时刻的单元状态;LSTM的输出有两个:当前时刻LSTM输出值h、和当前时刻的单元状态c。
LSTM的关键,就是怎样控制长期状态c。在这里,LSTM的思路是使用三个控制开关。第一个开关,负责控制继续保存长期状态c;第二个开关,负责控制把即时状态输入到长期状态c;第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。三个开关的作用如下图所示:








以上就是LSTM的前向计算。
反向传播同样不会涉及。
|








