| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫSiamNet ЭјТчНсЙЙЁЂЭјТчЕФбЕСЗдРэЁЂШчКЮНЋВЛЭЌФПБъГпДчНјааЙцЗЖЛЏЕШЯрЙиФкШнЁЃ
БОЮФРДздгкcsdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ВЮПМТлЮФЃКFully-Convolutional Siamese
Networks for Object Tracking
ЫуЗЈжївГ
code
1. ЭјТчНсЙЙМАеЊвЊ
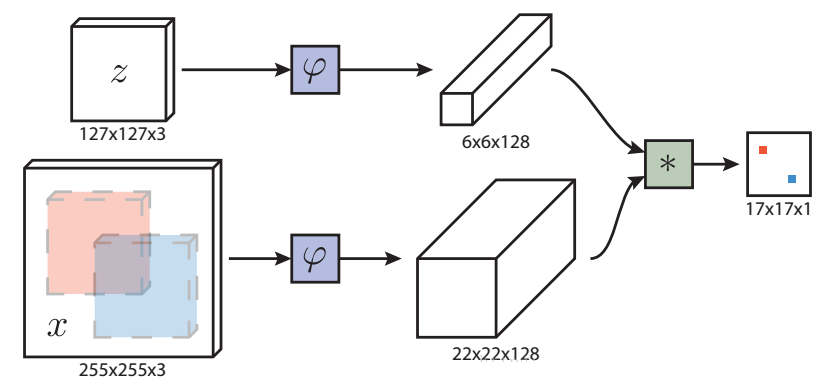
ЭМвЛ SiamNet ЭјТчНсЙЙЁЃ ЫбЫїЧјгђx, ЪфГіЕФЪЧвЛИіЕУЗжЭМЃЌ
ЫљЮНЕФЕУЗжОЭЪЧЯрЫЦЖШЖШСПЃЌЕУЗжЭМЕФЮЌЖШЪЧгЩЫбЫїЭМЯёПщОіЖЈЃЈбљБОФЃАхКЭЫбЫїЧјгђНјааУмМЏНЛВцЯрЙиЃЉЁЃДњБэЕФЪЧвЛжжЬиеїгГЩфВйзїЃЌНЋдЪМЭМЯёгГЩфЕНЬиЖЈЕФЬиеїПеМф
ДЋЭГвтвхЩЯЃЌ ШЮвтФПБъИњзйЮЪЬтВЩгУдкЯпбЇЯАФПБъЕФаЮУВЬиеїЭъГЩЁЃ ОЁЙметаЉдкЯпЕФЗНЗЈвбОШЁЕУСЫЗЧГЃКУЕФНсЙћЃЌЕЋЪЧАЁНіНідкЯпЕФЗНЗЈБОЩэОпЯожЦСЫФЃаЭбЇЯАЕФЗсИЛадЁЃзюНќЃЌвЛаЉбЇепПЊЪМРћгУЩюЖШОэЛ§ЭјТчЕФЧПДѓЬиеїБэДяФмСІЁЃШЛЖјЃЌЕБИњзйЕФФПБъЪТЧАВЂВЛжЊЕРЧщПіЯТЃЌЮвУЧгаБивЊВЩгУSGDдкЯпЕїећЭјТчЕФШЈжиЃЌетбЯжиЕФНЕЕЭСЫЯЕЭГЕФЫйЖШЁЃБОЮФжазїепНЋвЛИіШЋаТЕФШЋОэЛ§ТЯЩњЭјТчfully-convolutional
Siamese networkШкКЯЕНвЛИізюЛљБОЕФФПБъИњзйЫуЗЈжаЁЃSiamese network ВЩгУILSVRC15Ъ§ОнМЏНјааend-to-endЕФбЕСЗЁЃБОЮФЕФИњзйЦїОЁЙмЗЧГЃЕФМђЕЅЃЌЕЋЪЧИњзйзМШЗТЪКмКУЃЌПЩвдзіЕНЪЕЪБИњзйЁЃ
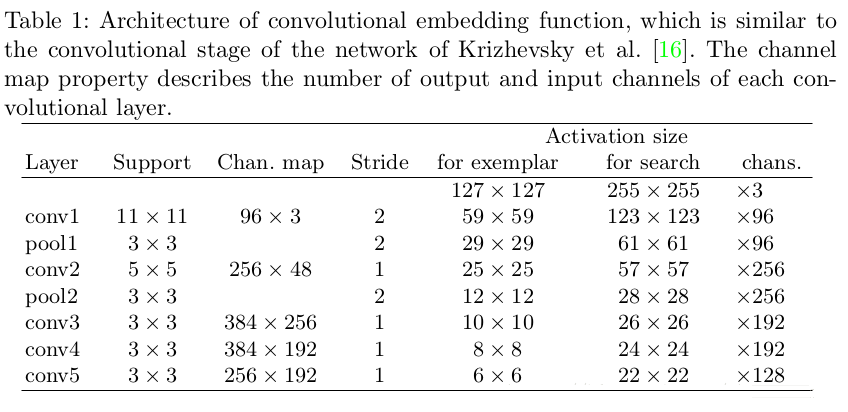
2. ЭјТчЕФбЕСЗдРэ
ЭМ2 SiamNetФЃаЭбЕСЗдРэ
2.1 ФЃаЭбЕСЗ-Ъ§ОнзМБИ
зїепВЩгУХаБ№ЪНЕФЗНЗЈЖдЭјТчНјаабЕСЗЃЌИќОпЬхЪЧВЩгУе§бљБОЁЂИКбљБОЗжБ№ЙЙГЩЕФexemplar-candidateЖдРДНјаабЕСЗЁЃ
ШчЭМ2ЫљЪОЃЌЩЯвЛжЁЕФФПБъФЃАхгыЯТвЛжЁЕФЫбЫїЧјгђПЩвдЙЙГЩКмЖрpairЕФexemplar-candidate
pairЃЌ ЕЋЪЧИљОнХаБ№ЪНИњзйдРэЃЌНіНіЯТвЛжЁЕФФПБъгыЩЯвЛеѓЕФФПБъЧјгђ(МД exemplarof T
frame-exemplarof T+1 frameЃЉЪєгкФЃаЭЕФе§бљБОЃЌЦфгрДѓСПЕФexemplar-candidate
pairЖМЪЧИКбљБОЁЃетбљОЭЭъГЩСЫЭјТчНсЙЙЕФЖЫЕНЖЫЕФбЕСЗЁЃ
етРяашвЊЖюЭтЫЕУївЛЕуОЭЪЧШчКЮШЗЖЈЫбЫїЧјгђX. ЦфЪЕетОЭЪЧИњзйСьгђБШНЯГЃгУЕФЗНЗЈЃЌИљОнЧАвЛжЁФПБъЕФжааФГѕЪМЛЏЯТвЛжЁЫбЫїЧјгђЕФжааФЮЛжУЃЌШЛКѓЩшМЦЫбЫїЧјгђЕФГпДчОЭКУСЫЁЃ
2.2 ФЃаЭбЕСЗ-Ы№ЪЇКЏЪ§ЩшМЦ
ЩшМЦФЃаЭЫ№ЪЇКЏЪ§вЛжБвдРДЖМЪЧФЃаЭзюживЊЕФвЛЛЗЁЃБОЮФзїепВЩгУСЫХаБ№ЪНбкФЄЕФаЮЪНЃЌ МДФПБъКЭЫбЫїЧјгђОЙ§НЛВцЛЅЯрЙиПЩвдЕУЕНЯрЙиГЬЖШЦзЭМЃЌЭМЯёдкбЕСЗЙ§ГЬжаexemplar-candidateЕФзМШЗЙиЯЕЪЧвбжЊЕФЁЃЫљвдЩшМЦЦ№РДВЂВЛРЇФбЁЃЕЋетРябАвЊгаШ§ИіЮЪЬташвЊНтОіЃК
ФЃАхКЭЫбЫїЧјгђОЙ§ОэЛ§ЬиеїЬсШЁжЎКѓЃЌЭМЯёГпДчвбОЗЂЩњИФБфЃЌШчКЮКЭвбжЊЕФХаБ№ЪНбкФЄНјаадЫЫуЃП
зїепВЩгУСЫОјЖдаЮЪНЕФХаБ№ЪНбкФЄЃЌШчЙћШЫЙЄБъМЧХМЖћГіЯжГіЯжЦЋВюЃЌЗЧКкМДАзЕФбкФЄЗНТдЪЧЗёКЯРэЃП
ПЩЗёРћгУframe-frameжЎМфЕФаХЯЂЃЌР§ШчЯрСкСНжЁжЎМфФПБъЕФЮЛжУЦЋвЦгІИУКмаЁЃП ВЩгУЦНОљЫ№ЪЇзїЮЊЫ№ЪЇКЏЪ§ЪЧЗёКЯРэЃП
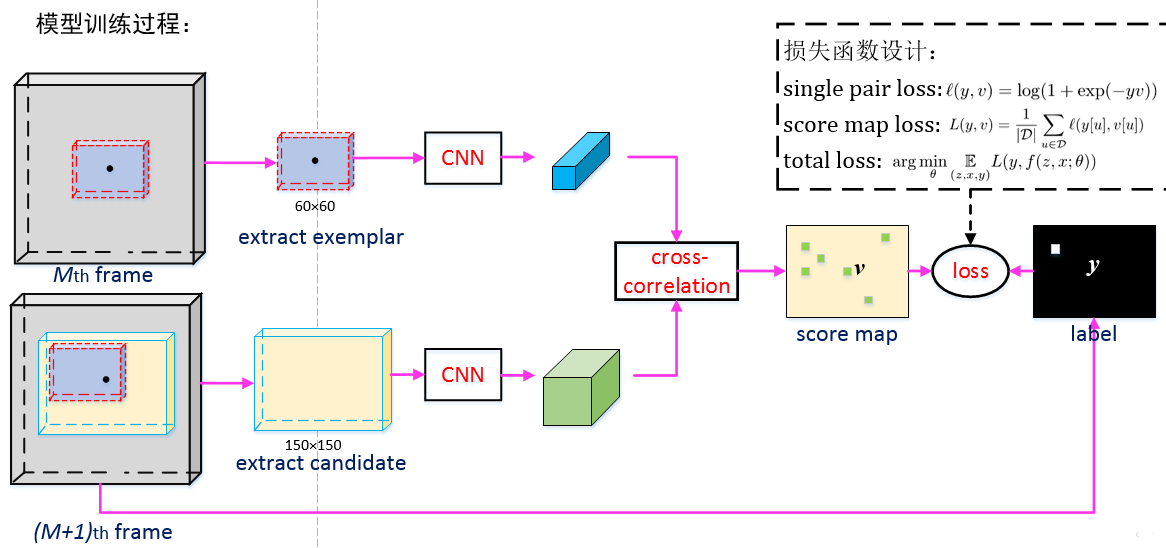
ЛиД№1ЃК
дкЙЬЖЈЬиеїЬсШЁЭјТчЛљДЁжЎЩЯЃЌжївЊгАЯьГпДчЕФЪЧSamplingЙ§ГЬЃЌвВОЭЪЧОэЛ§Й§ГЬжаЕФPoolingЃЌЫљвджЛашвЊМЧзЁPoolingЙ§ГЬжаЕФstrideОЭКУЁЃзїепНЋН№БъзМбкФЄЭЈЙ§strideВЮЪ§БфЛЏЕНScore
MapГпДчДѓаЁЕФЁЃШчЯТЫљЪОЃК
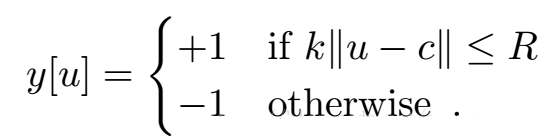
kБэЪОЕФОЭЪЧЭМЯёГпДчЕФНЕВЩбљЙ§ГЬЁЃ
ЛиД№2ЃК
зїепВЩгУЕФЪЧН№БъзМЮЛжУвЛЖЈЗЖЮЇФкЕФЧјгђЖМЪЧе§бљБОЃЌЦфЦфгрВПЗжЮЊИКбљБОЃЌетбљЪЧРЉДѓе§ИКбљБОжЎМфЕФОрРыЃЌЪЧЕФЗжРрИќМгЕФЧхЮњЃЌЕБШЛвВПЩвдЪЙгУИпЫЙШЈжиНјааИГжЕЙЙдьИпЫЙбкФЄЁЃ
ЛиД№3ЃКЃЈдкЯпИњзйЙ§ГЬЃЉ
зїепдкЕУЗжЭМЕФЛљДЁЩЯИГгшСЫгрЯвДАШЈжиЃЌгУРДГЭЗЃДѓЕФВЛКЯРэЕФЦЋвЦЮЛжУЁЃ
ДЫЭтЃЌзїепвВбаОПСЫГпЖШЕФгАЯьЃЌзїепНЋЫбЫїПеМфЭиеЙЕНСЫГпЖШПеМфЃЌНјааИќМгЩюВуДЮЕФЫбЫїЁЃ
ИњзйЪБжБНгЖдscore mapНјааЯпадВхжЕЃЌНЋ17*17ЕФscore mapРЉДѓЮЊ272*272ЃЌетбљдРДscore
mapжаЯьгІжЕзюДѓЕФЕугГЩфЛи272*272ФПБъЮЛжУЁЃ
3. ШчКЮНЋВЛЭЌФПБъГпДчНјааЙцЗЖЛЏ
зїепВЩгУСЫвЛИіЗЧГЃМђЕЅДжБЉЕФЗНЪННЋЫљгаФПБъЙцЗЖЕНСЫ127*127ДѓаЁЃЌОпЬхЮЊдБъзЂПђЕФГпДч+БпдЕЬюГф+ГпДчБфЛЏЁЃ
s(w+2*p) * s(h+2*p) = 127*127 s:ГпЖШвђзг p:БпдЕЬюГф
4. ЖюЭтаХЯЂ
зїепВЩгУШчЯТТлЮФНјааГпЖШБфЛЛЃКHe, K., Zhang, X., Ren, S., Sun, J.:
Delving deep into rectifiers: Surpassing humanlevel
performance on ImageNet classificationЃЌICCVЃЌ2015.
дкЯпЪЕЪБИќаТФЃАхВЂУЛгаЕУЕНБШНЯКУЕФЪевцЁЃЃЈШчВЩгУKCFЕФЯпадВхжЕФЃЪНИќаТФЃАхЃЉ
5. ИаЮђ
етИіЁАЦгЫиЁБЕФЭјТчНсЙЙЃЌЩюЩюЕФгАЯьСЫетСНФъРДtrackingЕФЗЂеЙЗНЯђЁЃ ЫљЮНЕФSiameseЃЈТЯЩњЃЉЭјТчЃЌЪЧжИЭјТчЕФжїЬхНсЙЙЗжЩЯЯТСНжЇЃЌетСНжЇЯёЫЋАћЬЅвЛбљЃЌЙВЯэОэЛ§ВуЕФШЈжЕЁЃЩЯУцвЛжЇЃЈzЃЉГЦЮЊФЃАхЗжжЇЃЈtemplateЃЉЃЌгУРДЬсШЁФЃАхжЁЕФЬиеїЃЌЯТУцвЛжЇЃЈxЃЉГЦЮЊМьВтЗжжЇЃЈsearchЃЉЃЌЪЧИљОнЩЯвЛжЁЕФНсЙћдкЕБЧАжЁЩЯcropГіЕФsearch
regionЁЃОЙ§СЫЯрЭЌЕФЭјТчжЎКѓЃЌФЃАцжЇЕФfeature mapдкЕБЧАжЁЕФМьВтЧјгђЕФfeature
mapЩЯзіЦЅХфЃЈ*ЃЉВйзїЃЌевЕНЯьгІзюДѓЕФЕуОЭЪЧЖдгІетвЛжЁФПБъЕФЮЛжУЁЃ
гХЪЦЃК
АбtrackingШЮЮёзіГЩСЫвЛИіМьВт/ЦЅХфШЮЮёЃЌећИіtrackingЙ§ГЬВЛашвЊИќаТЭјТчЃЌетЪЙЕУЫуЗЈЕФЫйЖШПЩвдКмПьЃЈFPSЃК80+ЃЉЁЃДЫЭтЃЌајзїCFNetНЋЬиеїЬсШЁКЭЬиеїХаБ№етСНИіШЮЮёзіГЩСЫвЛИіЖЫЕНЖЫЕФШЮЮёЃЌЕквЛДЮНЋЩюЖШЭјТчКЭЯрЙиТЫВЈНсКЯдквЛЦ№бЇЯАЁЃ
БзВЁЃК
1. ФЃАхжЇжЛдкЕквЛжЁНјааЃЌетЪЙЕУФЃАцЬиеїЖдФПБъЕФБфЛЏВЛЪЧКмЪЪгІЃЌЕБФПБъЗЂЩњНЯДѓБфЛЏЪБЃЌРДздЕквЛжЁЕФЬиеїПЩФмВЛзувдБэеїФПБъЕФЬиеїЁЃжСгкЮЊЪВУДжЛдкЕквЛжЁЬсШЁФЃАцЬиеїЃЌЮвШЯЮЊПЩФмвђЮЊЃК
1ЃЉЕквЛжЁЕФЬиеїзюПЩППвВзюТГАєЃЌдкtrackingЙ§ГЬжаЮоЗЈШЗЖЈФФвЛжЁЕФНсЙћПЩППЕФЧщПіЯТЃЌжЛгУЕквЛжЁЬиеїзувдЕФЕНВЛДэЕФОЋЖШЁЃ
2ЃЉжЛдкЕквЛжЁЬсФЃАхЬиеїЕФЫуЗЈИќОЋМђЃЌЫйЖШИќПьЁЃ
2. SiameseЕФЗНЗЈжЛФмЕУЕНФПБъЕФжааФЮЛжУЃЌЕЋЪЧЕУВЛЕНФПБъЕФГпДчЃЌЫљвджЛФмВЩШЁМђЕЅЕФЖрГпЖШМгЛиЙщЃЌетМДдіМгСЫМЦЫуСПЃЌЭЌЪБвВВЛЙЛОЋШЗЁЃ |








