| 编辑推荐: |
在本文中,我们提出了一个通用的集群计算框架ray,它可以为rl应用程序提供模拟、训练和服务。
本文来自于csdn,由火龙果软件Alice编辑、推荐。 |
|
摘要
下一代人工智能应用程序将不断与环境交互,并从这些交互中学习。这些应用程序在性能和灵活性方面都对系统提出了新的和苛刻的要求。在本文中,我们考虑了这些需求,并提出了一个分布式系统来解决这些需求。ray实现了一个统一的接口,该接口可以表示任务并行计算和基于actor的计算,并由单个动态执行引擎支持。为了满足性能要求,Ray采用分布式调度程序和分布式容错存储来管理系统的控制状态。在我们的实验中,我们展示了超越每秒180万个任务的扩展能力,并且在一些具有挑战性的强化学习应用程序中比现有的专业系统具有更好的性能。
简介
在过去的二十年里,许多组织一直在收集并致力于利用不断增长的数据量。这导致了大量分布式数据分析框架的开发,包括批处理[20、64、28]、流式处理[15、39、31]和图形处理系统[34、35、24]。这些框架的成功使组织能够将分析大数据集作为其业务或科学战略的核心部分,并迎来了“大数据”时代。
最近,以数据为中心的应用程序的范围已经扩展到更复杂的人工智能(AI)或机器学习(ML)技术[30]。典型的例子是有监督的学习,其中数据点伴随着标签,并且用于将数据点映射到标签的主力技术是由深层神经网络提供的。这些深层网络的复杂性导致了另一系列的框架工作,这些框架工作的重点是深层神经网络的训练及其在预测中的应用。这些框架通常使用专用硬件(如GPU和TPU),目的是在批量设置中减少培训时间。示例包括tensorflow[7]、mxnet[18]和pytorch[46]。
然而,人工智能的前景远比传统的监督学习更为广阔。新兴的人工智能应用程序必须越来越多地在动态环境中运行,对环境的变化做出反应,并采取一系列行动来实现长期目标[8,43]。他们的目标不仅是利用收集到的数据,而且还要扩大可能采取行动的空间。这些更广泛的要求自然地被框架在强化学习(RL)的范式中。rl研究基于延迟和有限反馈的在不确定环境中连续操作的学习[56]。基于rl的系统已经取得了显著的成果,比如谷歌的alphago击败了人类世界冠军[54],并开始进入对话系统、无人机[42]和机器人操作[25,60]。
rl应用程序的中心目标是学习一种策略,即从环境状态到随时间产生有效性能的操作选择的映射,例如赢得游戏或驾驶无人驾驶飞机。在大型应用程序中查找有效策略需要三个主要功能。首先,rl方法通常依赖于模拟来评估策略。通过模拟,可以探索许多不同的动作序列选择,并了解这些选择的长期后果。其次,与有监督的学习算法一样,rl算法需要进行分布式训练,以改进基于仿真或与物理环境交互生成的数据的策略。第三,策略旨在为控制问题提供解决方案,因此有必要在交互式闭环和开环控制场景中为策略提供服务。
这些特性驱动了新的系统需求:用于rl的系统必须支持细粒度计算(例如,在与真实世界交互时以毫秒为单位呈现操作,并执行大量模拟),必须在时间上支持异构性(例如,模拟可能需要毫秒或数小时)和在重新源代码使用中支持异构性。(例如,用于训练的GPU和用于模拟的CPU),并且必须支持动态执行,因为模拟结果或与环境的交互可以改变未来的计算。因此,我们需要一个动态计算框架,以毫秒级的延迟每秒处理数百万个异构任务。
针对大数据工作负载或监督学习工作负载开发的现有框架无法满足这些对RL的新要求。map reduce[20]、apache
spark[64]和dryad[28]等大容量同步并行系统不支持细粒度模拟或策略服务。ciel[40]和dask[48]等任务并行系统对分布式训练和服务的支持很少。对于naiad[39]和storm[31]等流媒体系统也是如此。像tensorflow[7]和mxnet[18]这样的分布式深度学习框架自然不支持模拟和服务。最后,tensorflow
service[6]和clipper[19]等模型服务系统既不支持训练也不支持模拟。
虽然原则上可以通过将几个现有系统(例如,用于分布式训练的horovod[53]、用于服务的clipper[19]和用于模拟的ciel[40])缝合在一起来开发端到端解决方案,但实际上,由于这些组件在应用程序中的紧密耦合,这种方法是站不住脚的。因此,今天的研究人员和实践者为专门的rl应用构建一次性系统[58、41、54、44、49、5]。这种方法给分布式应用程序的开发带来了巨大的系统工程负担,其实质是将调度、容错和数据移动等标准系统挑战推到每个应用程序上。
在本文中,我们提出了一个通用的集群计算框架ray,它可以为rl应用程序提供模拟、训练和服务。这些工作负载的需求范围从轻量级和无状态计算(如用于模拟)到长时间运行和有状态计算(如用于培训)。为了满足这些需求,Ray实现了一个统一的接口,可以同时表示任务并行计算和基于Actor的计算。任务使Ray能够高效、动态地进行负载平衡模拟,处理大的输入和状态空间(如图像、视频),并从故障中恢复。相反,actors使ray能够有效地支持有状态计算,例如模型训练,并向客户机(例如,参数服务器)公开共享的可变状态。ray在一个高度可伸缩和容错的动态执行引擎上实现actor和任务抽象。
为了满足性能要求,ray分发了两个组件,这两个组件通常集中在现有框架中[64、28、40]:(1)任务调度器和(2)维护计算沿袭的元数据存储和数据对象的目录。这允许Ray以毫秒级的延迟每秒调度数百万个任务。此外,ray为任务和参与者提供了基于沿袭的容错,并为元数据存储提供了基于复制的容错。
虽然ray支持在rl应用程序的上下文中服务、培训和模拟,但这并不意味着它应该被视为在其他上下文中为这些工作负载提供解决方案的系统的替代品。特别是,Ray并不打算替代Clipper[19]和TensorFlow
Serving[6]等服务系统,因为这些系统解决了部署模型(包括模型管理、测试和模型组合)时的一系列更广泛的挑战。类似地,尽管Ray具有灵活性,但它不能替代Spark[64]等通用数据并行框架,因为它目前缺乏这些框架提供的丰富功能和API(例如,分散缓解、查询优化)。
我们做出以下贡献:
我们设计并构建了第一个分布式框架,将培训、模拟和服务新兴RL应用程序的必要组件统一起来。
为了支持这些工作负载,我们将参与者和任务并行抽象统一在动态任务执行引擎之上。
为了实现可扩展性和容错性,我们提出了一个系统设计原则,其中控制状态存储在分片元数据存储中,而所有其他系统组件都是无状态的。
为了实现可扩展性,我们提出了一种自下而上的分布式调度策略。
动机和需求
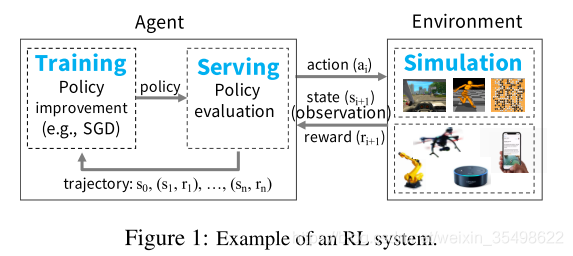
我们首先考虑rl系统的基本组成部分,并充实了对ray的关键要求。如图1所示,在RL设置中,代理与环境重复交互。代理人的目标是学习一种使报酬最大化的策略。策略是从环境状态到操作选择的映射。环境、代理、状态、操作和奖励的精确定义是特定于应用程序的。
为了学习策略,代理通常采用两步流程:(1)策略评估和(2)策略改进。为了评估策略,代理与环境交互(例如,与环境的模拟)以生成轨迹,其中轨迹由当前策略生成的(状态、奖励)元组序列组成。然后,代理使用这些轨迹来改进策略;即,在使回报最大化的梯度方向上更新策略。图2显示了代理用来学习策略的伪代码示例。此伪代码通过调用rollout(environment,policy)生成轨迹来评估策略。然后使用这些轨迹通过policy.update(轨迹)改进当前策略。此过程重复,直到策略聚合。
因此,rl应用程序的框架必须为培训、服务和模拟提供有效的支持(图1)。接下来,我们简要描述这些工作负载。
训练通常包括运行随机梯度下降(sgd),通常在分布式环境中,以更新策略。分布式sgd通常依赖于allreduce聚合步骤或参数服务器[32]。
服务使用经过培训的策略根据环境的当前状态执行操作。服务系统的目标是最小化延迟,并使每秒的决策数最大化。为了扩展,负载通常在为策略服务的多个节点之间平衡。
与监督学习(其中培训和服务可以由不同的系统分别处理)不同,在rl中,这三种工作负载紧密耦合在一个应用程序中,它们之间有严格的延迟要求。目前,没有框架支持这种工作负载耦合。理论上,可以将多个专用框架组合在一起以提供总体功能,但实际上,在rl的上下文中,在系统之间产生的数据移动和延迟是禁止的。因此,研究人员和从业人员一直在建立自己的一次性系统。

这种现状要求为rl开发新的分布式框架,以有效地支持培训、服务和仿真。特别是,这种框架应满足以下要求:
细粒度、异构计算。计算的持续时间可以从毫秒(例如,执行操作)到小时(例如,培训复杂的策略)。此外,培训通常需要异构硬件(如CPU、GPU或TPU)。
灵活的计算模型。 rl应用程序需要无状态和有状态计算。无状态计算可以在系统中的任何节点上执行,这使得在需要时可以轻松实现负载平衡和计算到数据的移动。因此,无状态计算非常适合于细粒度仿真和数据处理,例如从图像或视频中提取特征。相反,有状态计算非常适合于实现参数服务器、对gpu支持的数据执行重复计算或运行不公开其状态的第三方模拟器。
动态执行。 rl应用程序的几个组件需要动态执行,因为计算完成的顺序并不总是预先知道(例如,模拟完成的顺序),并且计算的结果可以确定未来的计算(例如,模拟的结果将确定我们是否需要执行更多的模拟)。
我们作了最后两点评论。首先,要在大型集群中实现高利用率,这样的框架必须每秒处理数百万个任务。第二,这样的框架不打算从头开始实现深层神经网络或复杂的模拟器。相反,它应该能够与现有模拟器[13、11、59]和深度学习框架[7、18、46、29]无缝集成。 |








