| 编辑推荐: |
本文将从卷积神经网络的角度讨论深度学习,使用Keras和Theano,重点关注深度学习的基本原理。本文将展示两个例子——其中一个例子使用Keras进行基本的预测分析,另外一个使用VGG进行图像分析。
本文来自于雷锋网,由火龙果软件Anna编辑、推荐。 |
|
在接下来的文章中,我们将会讨论医学影像中DICOM和NIFTI格式之间的不同,并且研究如何使用深度学习进行2D肺分割分析。除此之外,我们还将讨论在没有深度学习时,医学图像分析是如何进行的;以及我们现在如何使用深度学习进行医学图像分析。在这里,我非常欢迎和感谢我的新伙伴Flavio
Trolese——4Quant的联合创始人和ETH Zurich的讲师——他将协助我整合所有讨论的内容。
何为Keras?
根据Keras官网的介绍,Keras是Theanos和Tensor Flow的一个深度学习库。
运行于Theano和TensorFlow之上的Keras api
Keras是一个高级Python神经网络API,它能够运行于TensorFlow和Theano之上。Keras的开发重点在于支持快速实验。
何为Theano和Tensor Flow?
James Bergstra教授等人在2010年的Scipy曾说,Theano是一个CPU和GPU的数学表达式编译器。换句话来说,Theano是一个能够让你高效地对数学表达式进行定义、优化和评估的Python学习库。Theano是由一些高级研究人员,如Yoshua
Bengio,和“蒙特罗学习算法研究所”(MILA)共同研发的。下图是发布于2010年Scipy上的Theano教程,图中对比了Theano下的GPU和CPU与当年其他的工具。这张图片发表于原创论文——《Theano——CPU和GPU的Python数学编译器》。
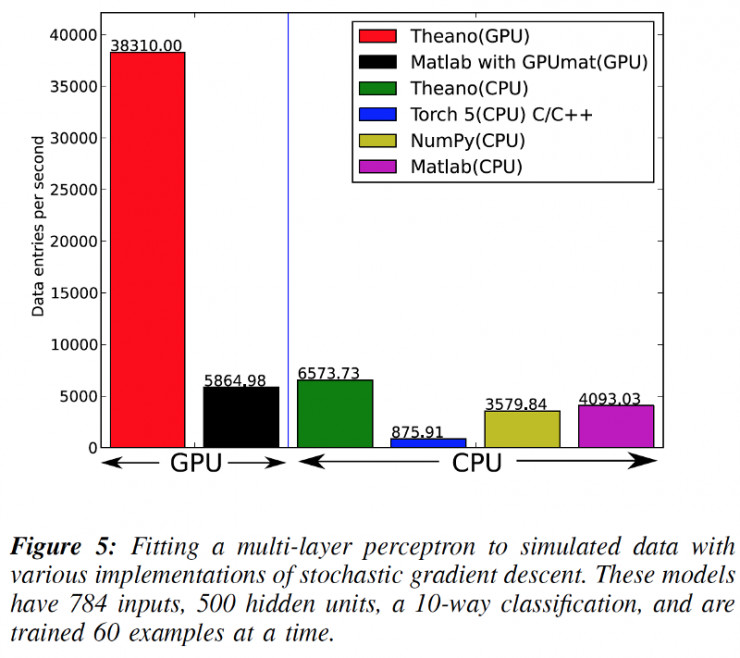
《Theano——CPU和GPU的Python数学编译器》作者:James Bergstra, Olivier
Breuleux, Frédéric Bastien, Pascal Lamblin, Razvan
Pascanu, Guillaume Desjardins,Joseph Turian, David
Warde-Farley, Yoshua Bengio
建立在Theano之上的还有一些其他的深度学习库,包括Pylearn2、GroundHog(同样是由MILA开发的)、Lasagne和Blocks
and Fuel等。
《使用Theano计算的透明GPU》——James Bergstra
TensorFlow是由“谷歌机器智能研究所”组织下的“谷歌大脑”团队研发完成的。TensorFlow的开发是为了进行机器学习和深度神经网络的研究,除此之外,它还广泛适用于其他的领域。根据TensorFlow官网介绍,TensorFlow是一个使用数据流图表进行数值计算的开源软件库。图表中的节点代表数学运算,而表格边缘则代表沟通节点的多维数据数组(tensors)。其中的代码视觉上正如下图所展示的:

图片来源:《TensorFlow:异构分布系统上的大规模机器学习》
使用Keras进行预测性分析的示例
在本文中,我们将使用来自UCI网站的Sonar数据集来完成一个简单的预测模型示例。在下面的代码中,我们直接从UCI网站获取数据,并将这些数据按照60::40的比例分为训练数据和测试数据。我们使用Keras进行预测建模,使用sklearn对标签进行编码。
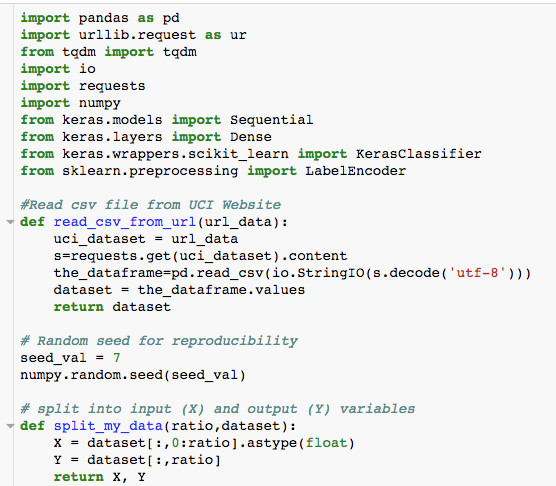
在下一个代码片段中,我们使用之前定义好的函数来读取数据集中的数据。打印数据集之后,我们会发现我们的独立变量是需要进行编码的。
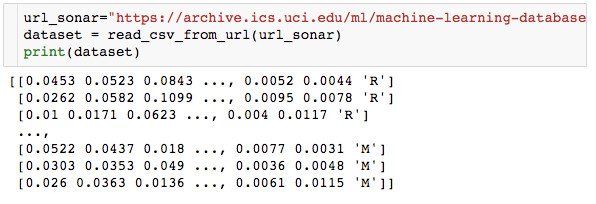
我们使用来自Scikit-learn的LabelEncoder(标签编码器)对标签进行编码,将字母R和M分贝转换为数字0和1。一种热编码还将分类特征转换成为了一种与算法更合适的格式。在这个示例中,我们的Y变量与R和M一样是分类对象,使用标签编码器,我们将这些字母变量转换为了1或0。
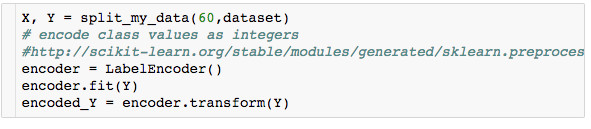
Scikit-learn的标签编码器
之后,我们创建了一个使用Keras的模型:
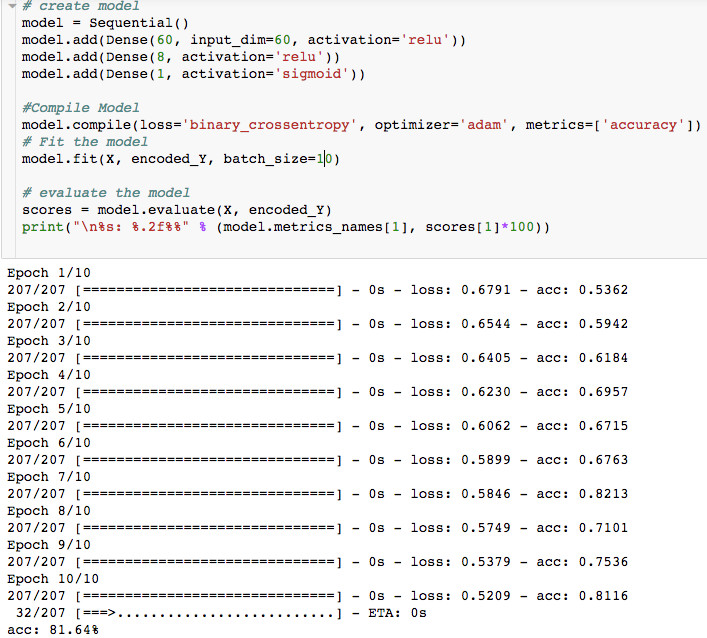
在没有任何预处理操作的情况下,使用简单模型的准确度为81.64%
使用Keras进行图像分析的示例
为了更好地用Keras解释图像处理过程,我们将使用来自“Kaggle猫狗竞赛”的数据。这个竞赛的目的是开发一个能够用来区分图像中包含的是一只狗还是一只猫的算法。对于人类来说,区分猫狗是很简单的,但对于计算机来说可就复杂的多了。在这项“区分猫狗”的挑战中,有25000张标记了猫狗的训练图片,测试数据库中还有12500张等着我们去标记。根据Kaggle官网,当这个竞赛开始时(2013年年底):
“目前的文献表明,机器分类器在这个任务上的准确度能达到80%以上。”因此,如果我们能成功突破80%的准确度,我们就能跃居2013年的技术发展最前沿。
想要了解更多细节、进行下一步的学习或对深度学习进行尖端研究,我强烈推荐Fast.ai的网络公开课程。我在下面的代码中引用了fast.ai,它为我们的学习提供了一个很好的起点。

第一步:完成设置
从Kaggle网站上下载猫、狗的图片数据,将其保存在你的电脑上。在本文提到的示例中,我会在我的iMac电脑上运行代码。

基本的设置
Jeremy Howard提供了一个Python实用文件,帮助我们获取已封装的基础函数。我们要做的第一步就是使用这个实用文件。下图就是这个实用文件。随着细节的深入,我们将一步步打开这个文件,看看隐藏在文件背后的信息。

第二步:使用VGG
我们在第一步中简单地使用了一个完全为我们建立的模型,这个模型能够识别各种各样的图像。第二步,我们将使用VGG。VGG是一个非常容易创建和理解的模型,它赢得了2014年的“ImageNet挑战赛”。VGG
imagenet团队创建了两个模型——VGG 19和VGG 16。VGG 19是一个大型的、操作性能慢的、准确度稍佳的模型;而VGG
16是一个小型的、操作性能快的模型。我们将会使用VGG 16,因为VGG 19的操作性能比较慢,通常不值得在精确度上再做改进。
我们建立了一个Python类——Vgg16。Vgg16能让VGG 16模型的使用更加简单。在fast.ai的github上同样能找到Vgg16,具体细节如下图:

第三步:实例化VGG
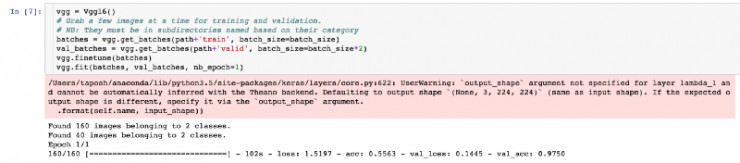
Vgg16建立于Keras(我们将在稍后讨论更多关于Keras的内容)之上。Keras是一个灵活的、易于使用的、建立在Theano和TensorFlow上的深度学习库。Keras使用一个固定的目录结构来分批查看大量的图像和标签,在这个目录结构下,每一类训练图像都必须放置在单独的文件夹里。
下面是我们从文件夹中随意抓取的数据:


第四步:预测猫、狗

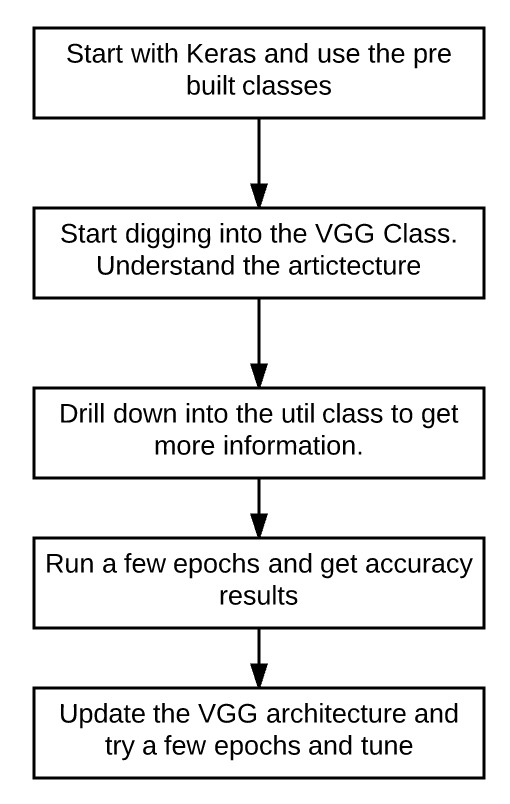
第五步:将图像和代码文件汇总
为了汇总这些图像和文件,我推荐的方法如下图:
总结:
阅读到这里,就证明你就已经采纳了我们在上一篇文章中讨论的理论,并做了一些实际的编程。如果你按照上面的指示和说明完成了两个示例,那么你就已经成功建立了你的第一个预测模型,并完成了图像分析。 |








