| БрМЭЦМі: |
БОЮФбнЪОШЫСГМьВт,HaarЗжРрЦї,HOGЗНЯђЬнЖШжБЗНЭМ,ФПБъМьВт,ОэЛ§ЩёОЭјТч,ЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздЮЂаХКХAIПЊЗЂепЃЌгЩЛ№СњЙћШэМўDeloresБрМЭЦМі |
|
зюНќЃЌЮввбОдФЖССЫКмЖргыМЦЫуЛњЪгОѕЯрЙиЕФзЪСЯВЂзіСЫДѓСПЪЕбщЃЌетРяНщЩмСЫдкИУСьгђбЇЯАКЭЪЙгУЙ§ГЬжагавтЫМЕФФкШнЁЃ

здЖЏМнЪЛЕФЭМЯёЗжИю
НќФъРДЃЌМЦЫуЛњЪгОѕШЁЕУСЫКмДѓНјеЙЁЃетаЉЪЧЮвНЋдкетРяЬсЕНЕФжїЬтЃК
ММЪѕЃК
ШЫСГМьВтЃКHaarЃЌHOGЃЌMTCNNЃЌMobilenet
ШЫСГЪЖБ№ЃКCNNЃЌFacenet
ФПБъЪЖБ№ЃКalexnetЃЌinceptionnetЃЌresnet
ЧЈвЦбЇЯАЃКдквЛИіаТГЁОАЩЯгУКмЩйЕФзЪдДжиаТбЕСЗДѓаЭЩёОЭјТч
ЭМЯёЗжИюЃКrcnn
ЩњГЩЪНЖдПЙЭјТч
МЦЫуЛњЪгОѕЫљашгВМўЃКбЁдёЪВУДЃЌЙиМќЪЧGPU
МЏГЩЪгОѕЕФUIгІгУГЬађЃКownphotos
гІгУЃК
ИіШЫЭМЦЌећРэ
здЖЏМнЪЛЦћГЕ
здЖЏЮоШЫЛњ
бщжЄТыЪЖБ№/OCR
Й§ТЫЭјеО/гІгУГЬађЩЯЕФЭМЦЌ
здЖЏБъМЧгІгУГЬађЕФЭМЦЌ
ДгЪгЦЕЃЈЕчЪгНкФПЃЌЕчгАЃЉжаЬсШЁаХЯЂ
ЪгОѕЮЪД№
веЪѕ
ЙизЂЕФШЫЃК
живЊЕФЩюЖШбЇЯАДДЪМШЫЃКandrew ngЃЌyann lecunЃЌbengio yoshuaЃЌhinton joffrey
adam geitgey жївГ гаКмЖрМЦЫуЛњЪгОѕЗНУцЕФгаШЄЮФеТЃЌБШШч СДНг гаЭъећЕФШЫСГМьВт/ЖдЦы/ЪЖБ№СїГЬ
ПЮГЬЃК
coursera ЭјеОРяЕФ deep learning ПЮГЬ
coursera ЭјеОРяЕФ machine learning ПЮГЬ
ЯрЙиСьгђЃК
ЩюЖШЧПЛЏбЇЯАЃКАбАќКЌCNNЕФPPOКЭDPNПДзїЪфШыВу
гыздШЛгябдДІРэЕФНЛЛЅЃКlstm 2 cnn
ШЫСГМьВт

ШЫСГМьВтЪЧдкСГВПжмЮЇБъМЧЗНПђ
ШЫСГМьВтЪЧМьВтСГВПЕФШЮЮёЁЃгаКУМИжжЫуЗЈПЩвдзіЕНетвЛЕуЁЃ
HaarЗжРрЦї
HOGЃКЗНЯђЬнЖШжБЗНЭМ

HOGЪЧвЛжжгУгкФПБъМьВтЕФЬсШЁЬиеїЕФаТЗНЗЈЃКЫќзд2005ФъПЊЪМЪЙгУЁЃИУЗНЗЈЛљгкМЦЫуЭМЯёЯёЫиЕФЬнЖШЁЃШЛКѓНЋетаЉЬиеїРЁЫЭЕНЛњЦїбЇЯАЫуЗЈЃЌР§ШчSVMЁЃетжжЗНЗЈОпгаБШHaarЗжРрЦїИќКУЕФОЋЖШЁЃ
етжжЗНЗЈЕФЪЕЯждкdlibжаЃЌОЭЪЧдкface_recognition
MTCNN
вЛжжЪЙгУCNNsЕФБфСПРДМьВтЭМЯёЕФаТЗНЗЈЁЃОЋЖШИќИпЕЋЫйЖШЩдТ§ЁЃ
MobileNet
ФПЧАгУгкШЫСГМьВтЕФзюКУКЭзюПьЕФЗНЗЈЃЌЛљгкЭЈгУЕФmobile netМмЙЙЁЃ
ФПБъМьВт

ФПБъМьВтПЩвдЪЙгУгыШЫСГМьВтРрЫЦЕФЗНЗЈРДЪЕЯж
ОэЛ§ЩёОЭјТч
зюНќЩюЖШбЇЯАЕФбИЫйЗЂеЙЃЌПЩвдПДЕНаэЖраТМмЙЙШЁЕУСЫКмДѓГЩЙІЁЃ
ЪЙгУаэЖрОэЛ§ВуЕФЩёОЭјТчОЭЪЧЦфжажЎвЛЁЃвЛИіОэЛ§ВуРћгУЭМЯёЕФ2DНсЙЙдкЩёОЭјТчЕФЯТвЛВужаЩњГЩгагУаХЯЂЁЃ
ФПБъЪЖБ№
ФПБъЪЖБ№ЪЧНЋЮяЬхЗжРрЮЊЬиЖЈРрБ№ЃЈШчУЈЃЌЙЗЃЌ......ЃЉЕФвЛАуадЮЪЬтЁЃ
ЛљгкОэЛ§ЕФЩюЖШЩёОЭјТчдкФПБъЪЖБ№ШЮЮёЩЯШЁЕУСЫКмКУЕФаЇЙћЁЃ
ILSVRЛсвщвЛжБдкImageNet(вЛИігааэЖрЭМЦЌЕФЪ§ОнМЏЃЌАќРЈУЈЃЌЙЗЕШЮяЦЗБъЧЉЃЉЩЯОйАьОКШќЁЃ
дНГЩЙІЕФЩёОЭјТчЪЙгУЕФВуЪ§ЛсдНРДдНЖрЁЃ
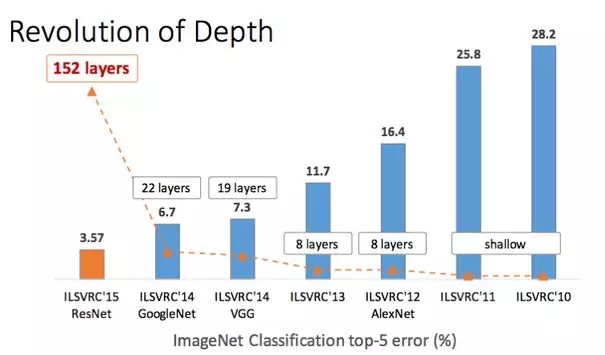
ResNetМмЙЙЪЧЦљНёЮЊжЙЖдФПБъНјааЗжРрЕФзюКУЭјТчМмЙЙЁЃ
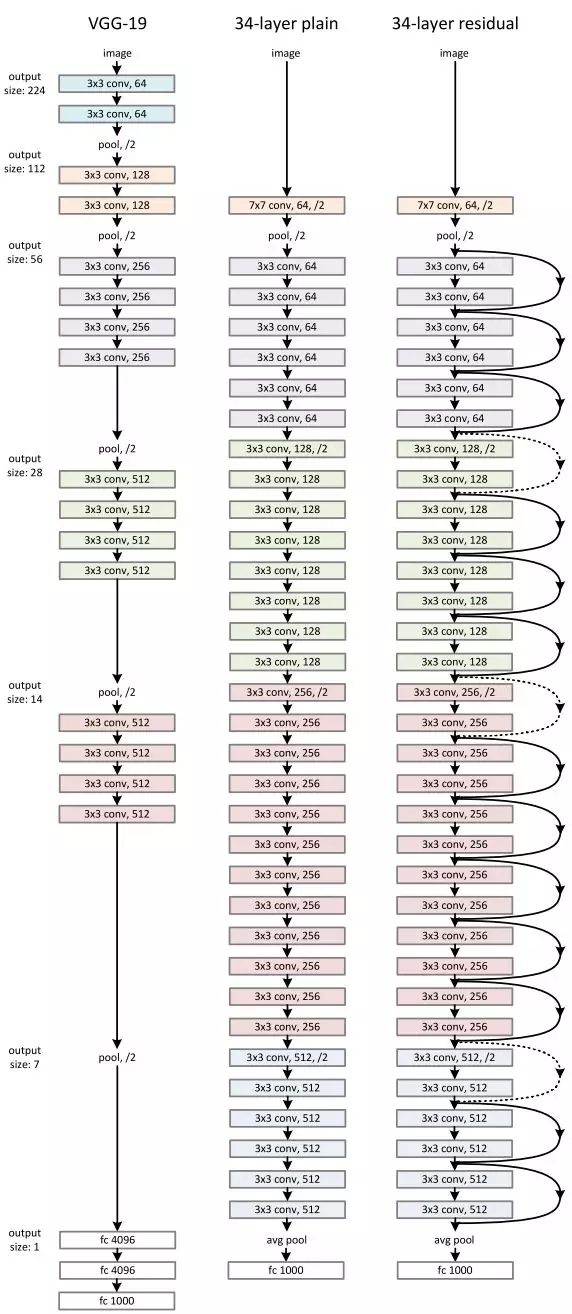
вЊе§ШЗЕибЕСЗResNetЃЌашвЊЪЙгУЪ§АйЭђеХЭМЯёЃЌВЂЧвМДЪЙЪЙгУЪ§ЪЎИіАКЙѓЕФGPUЃЌвВашвЊЛЈЗбДѓСПЪБМфЁЃ
ЮЊСЫБмУтУПДЮЖМвЊдкетаЉДѓЪ§ОнМЏЩЯНјаажиаТбЕСЗЃЌевЕНвЛаЉЦфЫћДњЬцЗНЗЈЪЧЪЎЗжживЊЕФЃЌЖјЧЈвЦбЇЯАКЭЧЖШыembeddingsОЭЪЧетбљЕФЗНЗЈЁЃ
гаЙиresnetЕФдЄбЕСЗФЃаЭ
ШЫСГЪЖБ№
ШЫСГЪЖБ№ОЭЪЧвЊХЊЧхГўЫЪЧвЛеХСГЁЃ
РњЪЗЗНЗЈ
НтОіИУШЮЮёЕФРњЪЗЗНЗЈЪЧНЋЬиеїЙЄГЬгІгУгкБъзМЛњЦїбЇЯАЃЈР§ШчsvmЃЉЃЌЛђАбЩюЖШбЇЯАЗНЗЈгІгУгкФПБъЪЖБ№ЁЃ
етаЉЗНЗЈЕФЮЪЬтЪЧЫќУЧашвЊУПИіШЫЕФДѓСПЪ§ОнЁЃЪЕМЪЩЯЃЌЪ§ОнВЂВЛзмЪЧПЩвдЕУЕНЕФЁЃ
Facenet
ЙШИшбаОПШЫдБдк2015ФъЭЦГіСЫFacenetЫќЬсГіСЫвЛжжЪЖБ№ШЫСГЕФЗНЗЈЃЌЖјВЛашвЊЮЊУПИіШЫЬсЙЉДѓСПЕФШЫСГбљБОЁЃ
етжжЗНЗЈЪЧЭЈЙ§ХФЩуДѓСПСГВПЕФЭМЦЌЪ§ОнМЏРДгааЇЙЄзїЕФЁЃ
ШЛКѓВЩгУЯжгаЕФМЦЫуЛњЪгОѕМмЙЙЃЌР§ШчinceptionЃЈЛђresnetЃЉЃЌдйгУМЦЫуСГВПЕФЧЖШыВуЬцЛЛФПБъЪЖБ№ЩёОЭјТчЕФзюКѓвЛВуЁЃ
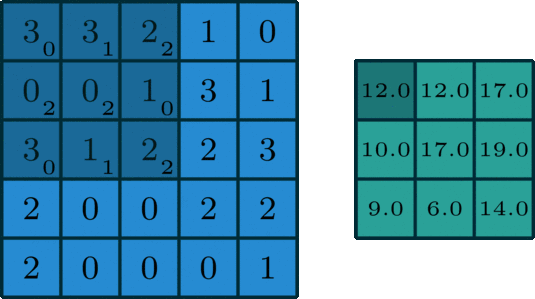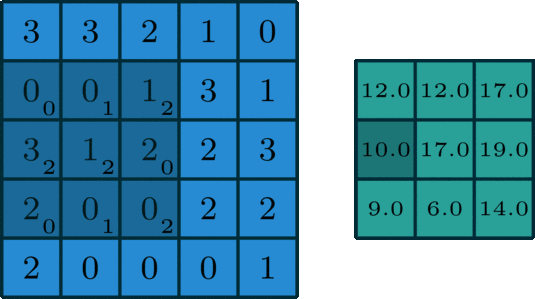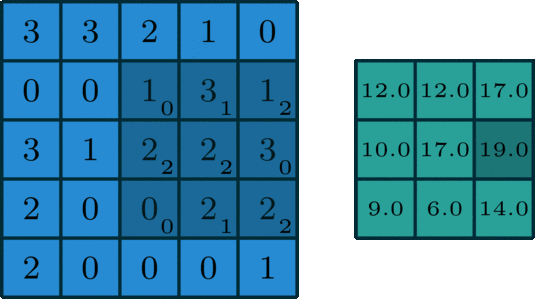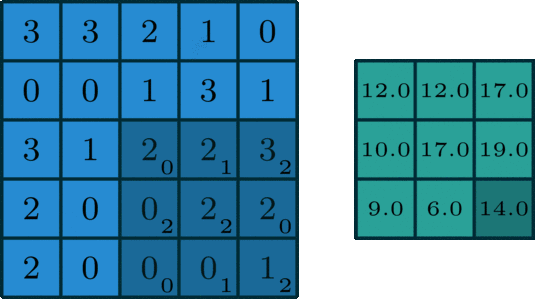
ЖдгкЪ§ОнМЏжаЕФУПИіШЫЃЌЃЈЪЙгУЦєЗЂЪНЗНЗЈЃЉбЁдёШ§еХСГЃЈИКбљБОЃЌе§бљБОЃЌЕкЖўе§бљБОЃЉВЂНЋЦфРЁЫЭЕНЩёОЭјТчЁЃетВњЩњСЫ3ИіЧЖШыembeddingsЁЃРћгУет3ИіЧЖШыЃЌМЦЫуtriplet lossЃЌетЪЙЕУе§бљБОгыШЮКЮЦфЫће§бљБОжЎМфЕФОрРызюаЁЛЏЃЌВЂЧвзюДѓЛЏЮЛжУбљБОгыШЮКЮЦфЫћИКбљБОжЎМфЕФОрРыЁЃ
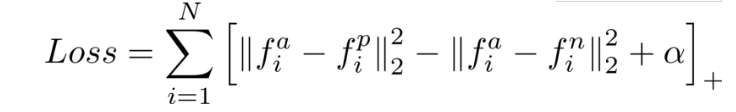

зюжеНсЙћЪЧУПеХСГЃЈМДЪЙдкдЪМбЕСЗМЏжаВЛДцдкЕФСГЃЉЯждквВПЩвдБэЪОЮЊвЛИіЧЖШыembeddingЃЈ128ЮЌЕФЯђСПЃЉЃЌИУЧЖШыгыЦфЫћШЫЕФСГВПЧЖШыгаКмДѓОрРыЁЃ
ШЛКѓЃЌетаЉЧЖШыПЩвдгыШЮКЮЛњЦїбЇЯАФЃаЭЃЈЩѕжСМђЕЅЕФжюШчknnЃЉвЛЦ№ЪЙгУРДЪЖБ№ШЫЁЃ
ЙигкfacenetКЭface embeddingsЗЧГЃгаШЄЕФЪТЧщОЭЪЧЪЙгУЫќФуПЩвдЪЖБ№жЛгаМИеХееЦЌЛђепжЛгавЛеХееЦЌЕФШЫЁЃ
ЧЈвЦбЇЯА
дкздЖЈвхЪ§ОнМЏЩЯПьЫйжиаТбЕСЗзМШЗЕФЩёОЭјТч
бЕСЗЗЧГЃЩюЕФЩёОЭјТчЃЈШчresnetЃЉЪЧЗЧГЃКФЗбзЪдДЕФЃЌВЂЧвЛЙашвЊДѓСПЕФЪ§ОнЁЃ
МЦЫуЛњЪгОѕЪЧИпЖШМЦЫуУмМЏаЭЕФЃЈдкЖрИіgpuЩЯНјааЪ§жмЕФбЕСЗЃЉВЂЧвашвЊДѓСПЪ§ОнЁЃЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧвбОЬжТлЙ§ЮЊШЫСГМЦЫуГіЭЈгУЕФЧЖШыembeddingsЁЃСэвЛжжЗНЗЈЪЧВЩгУЯжгаЭјТчВЂдкЦфЫћЪ§ОнМЏЩЯжиаТбЕСЗЃЌбЕСЗЪБНіНібЕСЗЦфжаЕФМИВуЁЃ
етЪЧвЛИіНЬГЬЃК codelab tutorial ЁЃЫќНЈвщФужиаТбЕСЗвЛИіГѕЪМФЃаЭЃЌДгЖјШЅбЕСЗЮДжЊЕФЛЈРрЁЃ
ЭМЯёЗжИю

гУгкздЖЏМнЪЛЕФЭМЯёЗжИю
НќФъРДЃЌЭМЯёЗжИюПЩФмЪЧвЛЯюСюШЫгЁЯѓЩюПЬЕФаТШЮЮёЁЃЫќАќРЈЪЖБ№ЭМЯёЕФУПИіЯёЫиЁЃ
ИУШЮЮёгыФПБъМьВтгаЙиЁЃЪЕЯжЫќЕФЦфжавЛжжЫуЗЈЪЧmask r-cnn
GAN

ЩњГЩЪНЖдПЙЭјТчЃЌЪЧгЩian goodfellowЬсГіЃЌетИіЭјТчМмЙЙЗжЮЊ2ВПЗжЃКХаБ№ЦїКЭЩњГЩЦїЁЃ
ХаБ№ЦїМьВтвЛеХЭМЦЌЪЧЗёЪєгкФГИіРрБ№ЃЌЫќЭЈГЃЪЧдкФПБъЗжРрЪ§ОнМЏЩЯНјаадЄбЕСЗЁЃ
ЩњГЩЦїЮЊИјЖЈЕФРрБ№ЩњГЩвЛеХЭМЯёЁЃ
дкбЇЯАЦкМфЕїећЩњГЩЦїЕФШЈжиЃЌФПБъЪЧЪЙЩњГЩЕФЭМЯёгыИУРрЕФецЪЕЭМЯёОЁПЩФмЯрЫЦЃЌвджСгкХаБ№ЦїЮоЗЈЧјЗжГіРДЁЃ
МЦЫуЛњЪгОѕЫљашгВМў

вЊбЕСЗДѓаЭФЃаЭЃЌашвЊгУЕНДѓСПзЪдДЁЃЪЕЯжетвЛФПБъгаСНжжЗНЗЈЁЃЪзЯШЪЧЪЙгУдЦЗўЮёЃЌБШШчgoogle cloudЛђепawsЁЃЕкЖўжжЗНЗЈЪЧздМКзщзАвЛЬЈДјгаGPUЕФМЦЫуЛњЁЃ
жЛаш1000УРдЊЃЌОЭПЩвдзщзАвЛЬЈЯрЕБКУЕФЛњЦїРДбЕСЗЩюЖШбЇЯАФЃаЭЁЃ
МЦЫуЛњЪгОѕЕФгУЛЇНчУц
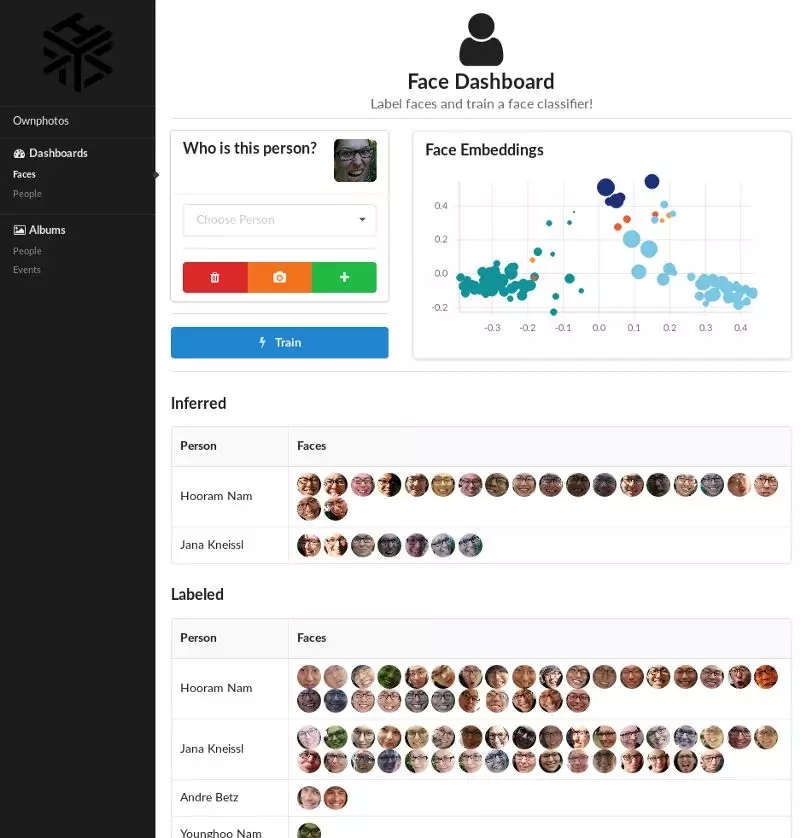
ownphotosЕФfaceвЧБэХЬ
Ownphotos ЪЧвЛИіСюШЫОЊЬОЕФгУЛЇНчУцЃЌдЪаэФњЕМШыееЦЌВЂздЖЏМЦЫуСГВПЧЖШыЃЌНјааФПБъЪЖБ№КЭШЫСГЪЖБ№ЁЃ
ЫќгУЕНЕФЫуЗЈЃК
ШЫСГЪЖБ№ЃКface_recognition
ФПБъМьВтЃКdensecap, places365
гІгУ

МЦЫуЛњЪгОѕгаКмЖргІгУЃК
ИіШЫЭМЦЌећРэ
здЖЏМнЪЛЦћГЕ
здЖЏЮоШЫЛњ
бщжЄТыЪЖБ№/OCR
Й§ТЫЭјеО/гІгУГЬађЩЯЕФЭМЦЌ
здЖЏБъМЧгІгУГЬађЕФЭМЦЌ
ДгЪгЦЕЃЈЕчЪгНкФПЃЌЕчгАЃЉжаЬсШЁаХЯЂ
ЪгОѕЮЪД№ЃКНсКЯздШЛгябдДІРэКЭМЦЫуЛњЪгОѕ
веЪѕЃКЩњГЩЪНЖдПЙЭјТч
НсТл
е§ШчЮвУЧетРяЫљМћЃЌЩЯЪіЪгОѕСьгђИїЗНУцЕФЪЕЯжжаЕЎЩњСЫаэЖраТЕФгаШЄЕФЗНЗЈКЭгІгУЁЃ
ЮвШЯЮЊШЫЙЄжЧФмзюгаШЄЕФЃЌдкИїСьгђгШЦфдкЪгОѕСьгђжаЃЌЪЧбЇЯАПЩдйЪЙгУЕФЫуЗЈЁЃШУетаЉЗНЗЈЪЪгУгкДІРэдНРДдНЖрЕФШЮЮёЖјВЛашвЊИќЖрЫуСІзЪдДКЭЪ§Он :
ЧЈвЦбЇЯА : ЪЙПьЫйжиаТбЕСЗдЄДІРэСЫЕФДѓаЭЩёОЭјТчГЩЮЊПЩФм
ЧЖШы (Р§Шчfacenet) : ЪЙЪЖБ№аэЖрРрЖјЮоашЖдетаЉРрНјаабЕСЗГЩЮЊПЩФм
|






