| 编辑推荐: |
本文主要介绍了如何使用Web浏览器查看实时流媒体以及相关的操作步骤。
本文来自于简书,由火龙果软件Linda编辑、推荐。 |
|
经过最近一段时间的调研学习,我对人工智能计算平台有了新的认识,它的本质就是要通过数据+建模算法训练出一个可以预知未来的模型,那么一个好的计算平台需要为用户在数据以及建模算法这两个核心要素上提供极大的便利。
那么我们如何才能做到这一点呢?
1. 完整的建模流程
下图是我猜想的一个完整的建模流程: 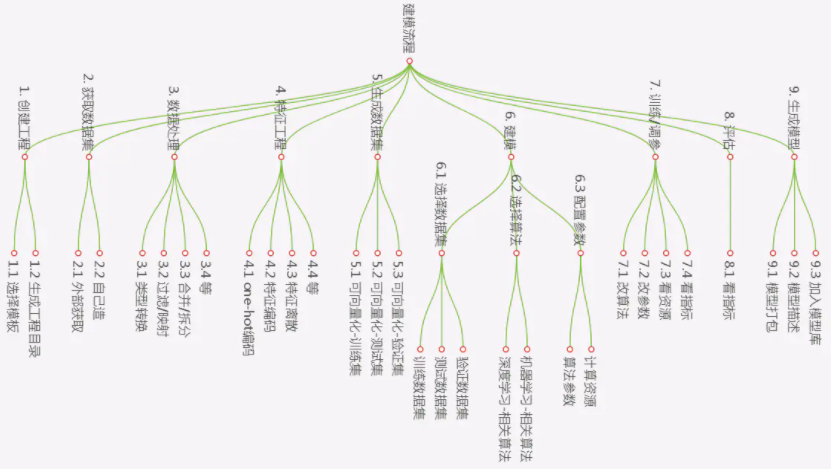
下面做一个描述:
创建工程:即为了某一个业务方向而创建的一个工程,工程内部系统会规划出不同的目录结构。
获取数据集:这个数据集有可能是网上现成的,也有可能是自己造的,也有可能是自己通过网络爬虫自己爬的,总之什么都有可能
数据处理和特征工程:要将现实中采集到的数据进行数据加工、清洗、特征提取、向量化、变成数据公式能识别的数字特征
正式数据集:即可以向量化的数据集,这些数据可以保存在文件中,也可以保存在数据库中。(像mnist,cifar10这种数据集,都是别人处理好的数据集,现实中一个数据集的生成是需要经过大量的加工处理的)
建模:理论上,我可以对一个数据集,采用多种建模算法,这个算法可以是机器学习中的各种算法,也可以是深度学习中的各种算法。即我可以建多个算法模型,最后通过实际训练及评估来确定哪个算法产生的模型是最好的。
训练、调参、评估:与上面是配套的
生产模型:将最后评估出来最好的模型,保存到模型库中。
所以我们以前的系统是很狭隘的:
不能对数据集做任何处理
只能做深度学习
2. 平台设计思路
2.1 功能角度
前面提到我们要在数据与建模算法两方面为用户提供便利,那么首先我们系统必须要包含这两个功能:
数据:获取数据集、数据加工、特征提取等
建模算法:系统要能支持多种建模算法,深度学习只是其中的一部分
2.2 用户角度
再从用户角度看看,我们系统核心用户是数据科学家,这些号称科学家的科学家们,又可能要分为两类人:一类是会敲代码的;一类是不会敲代码的。结合这段时间研究h2o以及kaggle,我决定让系统提供两条建模途径:编码式建模和可视化建模。
2.3 架构角度
如果提供了两条路,这两条路是相互隔离的,还是有交叉的,还是完全互通的呢?理想情况下,肯定是两条路完全互通是最好的。
再回到问题的源头,一个完整的建模流程中,涉及到哪些实实在在的东西?
数据是实实在在的
模型算法是实实在在的
保存的模型文件是实实在在的
如果要两条路基本互通,我们需要让上面提到的三点实实在在的东西,相互都能认识。即数据、模型算法、模型文件必须在两条路中是兼容的。在来分别看看这三者:
数据:这个没有任何问题,就是文件或者是数据库表,只要保存下来,大家都能认识
模型算法:这个就有问题了,外部世界中有无数的机器学习框架,也有无数的深度学习框架,不同的框架,写出的算法模型都不相同;而我们通过可视化界面所支持的模型算法肯定是有限的(悲观估计,以我们的能力,顶多能支持一两个框架就了不得了)
模型文件:同上面的问题一样,不同的计算框架,貌似生成的模型文件格式都不一样,比如tensorflow生成的是什么pb格式的serving模型,而像h2o平台生成的模型,其实是一个jar包,还有像spark
ml生成的模型,也是其特有的格式
我总结出的结论是,我们在数据上是可以完全互通的,在模型算法以及模型文件上能做到相对互通。即以可视化平台所支持的计算框架为基准,提供对这些模型算法以及模型文件的共享和互通!
2.4 结论
升级后的系统,我想达到以下几点效果:
系统业务功能,能按照上面梳理的建模流程来
全面调整之前的深度学习结构,将其定位为系统中一个普通的算法
提供建模的两条路,可视化建模和编码式建模
提供数据层面的完全共享,提供模型算法及模型文件层面上的部分共享
以下是平台建设示意图: 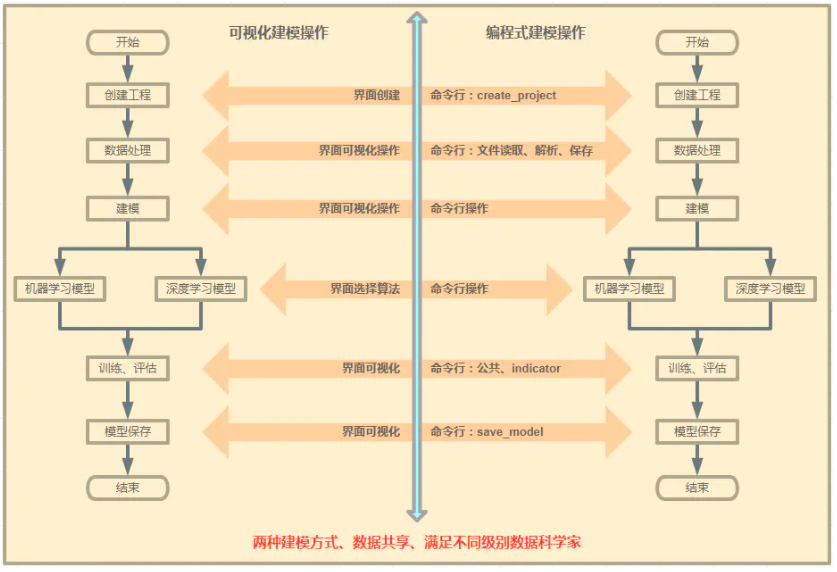
这张图是本次系统升级的核心!
因为我们要做到数据共享,所以两条路的各种结果文件必须是底层统一处理的,这就要求我们在编码式建模方向上,为用户提供一些系统内置函数支持。
需要底层提供哪些函数支持呢?我对代码实现不是很了解,初步猜测需要这些:
创建工程的函数
保存数据集的函数:保存到文件中,保存到数据库中
训练过程中,监控指标的函数
保存模型的函数
3. 原型设计结果
3.1 模型工程修改
这更多是底层实现的修改,之前一个工程是关联了计算框架的,现在需要把这个关联拿掉,计算框架只体现在具体的建模及训练环节,而不是整个工程级的。
3.2 数据处理
在交互界面中,增加数据处理可视化操作功能,它包含的功能有:
上传数据集
解析数据集
特征列数据转换
特征列数据补全
特征列数据分布图表展示
特征列关联性总览图表(热力图、矩阵图)
自定义特征列统计图表
保存数据集
3.3 jupyter notebook
原先做的jupyter太简单了,基本不能用。现在要正式将jupyter notebook提高到一个核心级的功能。我们需要在最大程度上做到对jupyter
notebook的定制化,以达到以下要求:
用户可以选择自己不同容器中的jupyter服务
用户可以通过我们系统界面来创建可执行脚本
我们为用户提供的镜像中,需要默认安装大部分主流计算框架,这其中需要包含深度学习框架,也需要包含机器学习框架
最后再明确一下,我们的jupyter是运行在用户容器中的,不是运行中计算环境中的
3.4 训练界面调整
这个功能调整非常大,以前创建的一个训练,只能做来做深度学习,现在要做到既能做深度学习,也能做机器学习。所以在创建任务界面和任务执行结果界面,都需要做比较大的调整,界面需要根据不同的算法,渲染出不同的界面要素及图表。
首页是创建任务界面,我规划为四栏:
第一栏(算法选择):任务名称自动生成、选择计算框架、算法、训练集、测试集、验证集
第二栏(基本参数栏):根据不同的算法,展示不同的参数;如执行轮次、比大小、脚本、优化器等不作为超参的参数
第三栏(超参数栏):根据不同的算法,展示不同的超参数
第四栏(自定义参数):通用参数栏
其次是任务执行结果页面,需要根据不同的算法,展示不同的结果页面,这个暂时还没有想清楚。
4. 系统改动量
4.1 现有功能调整
模型工程
这个上面提到了,需要把工程与计算框架的关联关系去掉
模型训练
这是现有功能最大的调整,创建任务的界面,以及任务执行界面,需要根据不同的算法,完全做到自定义配置及展示。不同的算法会涉及到不同的前端界面展示,以及后台与微服务的调用等等。
模型评估
这次我们需要做一个完整的模型评估功能,因为现实情况下,针对不同的问题,我们需要选择不同的评估算法,远不是之前做的那一种topk。
模型格式
这个主要是算法架构考虑,但后台系统也需要做调整,因为我们要支持不同的模型格式,去部署。
支持数据库数据集
我希望能在我们的界面上选择一个数据库数据集
4.2 新增的功能
数据处理
这是一个比较独立的功能,具体需要做哪些事,上面已经提到了。
jupyter
之所以把它也当成一个新的功能,是因为之前做的太简单了,这次要完全重新做。
4.3 算法架构的调整
算法架构这块其实是最大的变化:
算法架构需要提供所有主流算法(机器学习、深度学习)的支持
算法架构需要明确底层实现框架,明确系统支持哪几种计算框架及组件
需要明确统一的建模算法,做一定的抽象
需要提供保存数据集、读取数据集(有可能是数据库)、保存模型、记录指标等等通用的内置函数支持
需要统一模型文件格式
最重要的,需要考虑两条路线下,会有哪些坑是我没有考虑到的
最后提一点大家可能没有注意到的,就是现在将数据处理单独剥离出来,就将数据与建模过程解耦了,这是很好的。以前的mnist示例中,其实是将数据处理也一并写在训练的脚本中,这个并不合理,也不利于脚本抽象!
|








