| 编辑推荐: |
本文主要介绍了计算平台的底座 - AI容器平台(VContainer)的在线业务容器化落地过程中所遇到的问题及解决的思路,希望对你有帮助。
本文来自于腾讯云,由火龙果软件Linda编辑、推荐。 |
|
一、背景
vivo人工智能计算平台小组从2018年底开始建设 AI 计算平台至今,已经在k8s集群、以及离线的深度学习模型训练等方面,积累了众多宝贵的开发、运维经验,并逐步打造出稳定的基础容器平台
- AI容器平台(VContainer)。为了支撑公司AI在线业务的发展,满足公司对算力资源的高效调度管控需求,需要将在线业务,主要包括C端、推理等业务,由原来的虚拟机或物理机迁移至AI容器平台。于是小组从2020年初开始,基于在线业务的需求对AI容器平台进行进一步建设,并将平台与公司的CMDB、CICD等基础模块进行打通,使在线业务能够顺利从虚拟机、物理机迁移至AI
容器平台。
目前AI容器平台已迁移了4成左右的AI在线业务,大大小小100+在线应用,流量峰值超过22w qps,数百台服务器支撑着在线业务容器的运行。
本文是 vivo AI 计算平台技术演进系列文章之一,着重分享了计算平台的底座 - AI容器平台(VContainer)的在线业务容器化落地过程中所遇到的问题及解决的思路,vivo
AI 计算平台相关的技术实践可参考此前发布的《vivo AI 计算平台的K8s填坑指南》。
二、容器化部署的优点 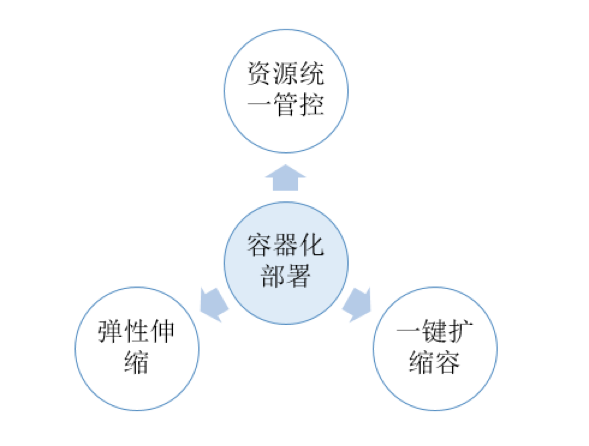
与虚拟机或物理机的部署相比,将业务部署到AI容器平台有很多优点:
容器平台可以统一对算力资源进行管控、调度,解决了机器资源分散、闲置、难以维护等问题
容器平台可以做到一键扩缩容,解决了业务扩缩容时资源申请、操作效率低问题
容器平台支持弹性伸缩,可以根据监控指标或定时做动态伸缩,很适合应用于具有高低峰特性的业务,保障业务稳定的同时,提升资源的利用率
总的来说,容器化部署可以提升资源利用率和运维效率,达到节约机器、运维成本的目的。
三、功能模块概览
在线业务容器化落地所涉及到的功能模块分两部分:公司云平台 和 AI 容器平台。云平台是用户入口,AI
容器平台则是容器化部署的基础环境:
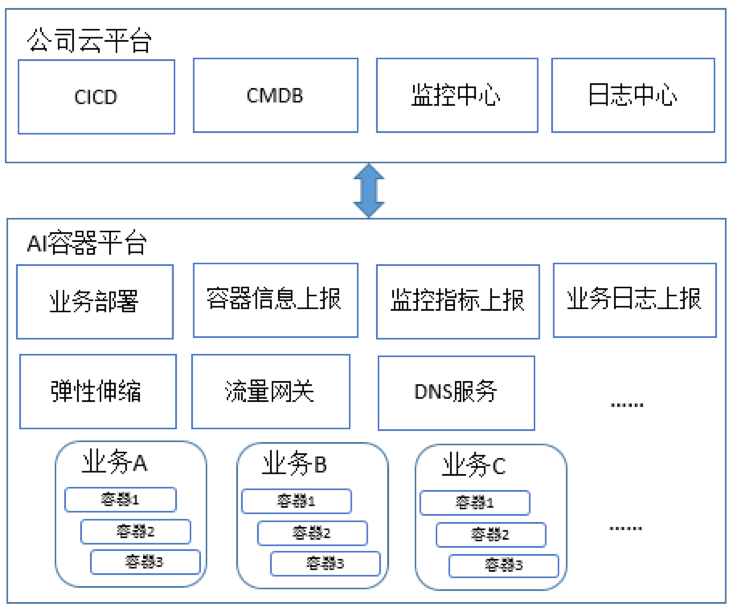
云平台模块介绍
如上图,AI 容器平台打通了公司云平台,以其作为业务容器化部署的入口,保证用户操作体验与虚拟机、物理机的一致,主要打通以下模块:
CICD:业务容器化部署、管理入口
CMDB:业务容器元数据信息维护入口
监控中心:业务容器监控指标查看入口,例如可以查看容器的运行时指标,如CPU、负载、网络IO
等指标,也可以针对指标配置各种告警规则
日志中心:业务容器日志查看入口
上图只列举了AI 容器平台所打通的主要模块,除这些模块之外,业务还可以继续沿用云平台上的配置中心、调用链、服务治理等众多模块的功能。
AI 容器平台模块介绍
AI 容器平台是容器化部署的基础环境,我们建设、集成了一系列的组件用于支撑业务容器的部署、管理、监控、运维等工作:
业务部署:负责对接公司云平台的 CICD,提供业务的部署及管理等服务
容器信息上报:负责对接公司云平台的 CMDB,进行容器元数据信息的上报
监控指标上报:负责对接公司云平台的监控中心,该服务会从 prometheus
拉取容器监控指标进行上报
? 业务日志上报:负责对接公司云平台的日志中心,容器平台通过 deamonset 的形式在每个节点上部署公司的日志采集插件,采集插件会从约定的主机目录下采集业务日志,然后对接日志中心的
kaffka 进行上报
弹性伸缩:提供 hpa 水平扩缩容功能,可基于 cpu、内存、qps
进行动态扩缩容,或者配置定时(Cron 表达式)的扩缩容
流量网关:业务流量入口,基于 nginx ingress controller
DNS 服务:k8s 集群域名解析服务,基于 coredns
四、业务容器化的痛点解决
为了保证在线业务能够平滑、稳定地迁移到容器平台,平台侧需要解决一系列业务容器化的需求与痛点,下面列举了几个比较典型的问题进行说明:
1、网络扁平化
网络扁平化,是指支持平台外的应用通过 pod ip 访问 pod 实例。未经扁平化的 k8s 网络,pod
的 ip 是不能被集群外访问的,例如类似 java dubbo 的应用,集群外的 dobbo comsumer
是无法通过 pod ip 访问 dubbo provider 的。为了满足平台外的应用通过 pod
ip 访问 pod 实例的场景,平台需要将 k8s calico 网络与机房网络打通(扁平化)。
AI 容器平台和网络团队合作,Calico 采用 Route Reflector 模式,在 RR
节点和机房交换机分别新增 BIRD 配置,使 RR 节点将集群内的 calico 路由信息通过 BGP
协议同步给交换机。这样集群外的服务访问 pod IP 时,交换机可以找到对应的路由规则,从而实现了容器网络的扁平化。
2、灰度发布
由于 k8s 原生的 deployment 只支持滚动更新、重建两种更新模式,难以支持灰度、发布暂停等功能,所以平台引入了另一款发布功能比较完善的部署组件
- Argo Rollout 来进行支持,Argo Rollout 除了兼容原生 deployment
的所有特性,还支持灰度发布、蓝绿发布等更加强大的发布特性。
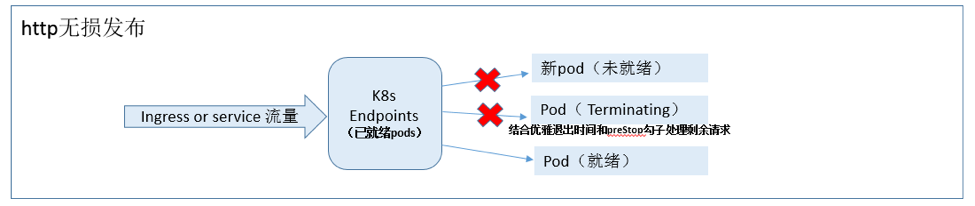
3、无损发布
无损发布,主要是解决发布过程中,旧版本容器实例销毁、新版本容器实例创建过程中的请求流量损失问题,目前主要有两类无损发布场景:
http 无损发布:http 流量通过 ingress 或 service
代理到 pod 实例的场景,这种场景可以通过配置容器的就绪检查、优雅退出时间(terminationGracePeriodSeconds)来实现,就续检查可以保证新的实例变为就绪后才能接受流量,合适的优雅退出时间可以确保旧实例上剩余请求处理完,k8s
才对实例进行销毁,同时业务也可以在容器的 preStop 勾子做些收尾操作。
dubbo 无损发布:由于 java dubbo 有自身的一套服务注册和消费机制,容器的就绪检查无法控制
dubbo 客户端对 dubbo 服务端的调用,所以需要额外的机制去实现无损。
目前的方案是结合 dubbo 注册中心开发的禁用 / 启用接口 和 k8s 的初始化容器 initContainer
来实现,核心过程如下:
(1)对于旧版本 pod 实例:在业务容器的 preStop 环节调用 dubbo 注册中心禁用接口,禁止流量请求到当前实例(根据
pod ip 禁用),同时需要合理配置优雅退出时间(terminationGracePeriodSeconds),以确保旧实例上剩余请求处理完,k8s
才对实例进行销毁
。
(2)对于新版本 pod 实例:在 初始化容器 initContainer 环节调用 dubbo
注册中心禁用接口,禁止流量请求到当前实例(根据 pod ip 禁用),当业务容器的 dubbo 服务启动后,会自动注册到注册中心,但此时注册中心是禁用此
pod ip 的,流量还不会进来。最后在 postStart 环节,判断服务已经启动完毕后(比如调用服务的
check 接口),再调用 dubbo 注册中心的启用接口,让当前的 pod 开始接受流量
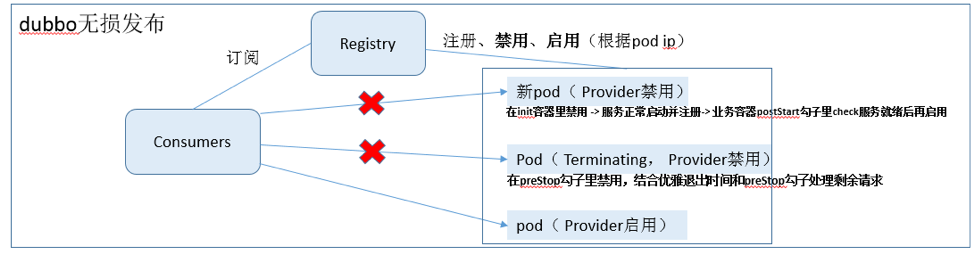
总结一下,其实两类发布场景的无损解决思路是一样的:
对于老版本的容器实例,先把流量断掉,等上面的剩余请求处理完毕后进行回收;
对于新版本的容器实例,确保服务能够正常处理请求后再把流量接进来。
通过对 http 无损发布和 dubbo 无损发布的支持,使业务的流量能够平滑地从旧版本切换到新版本,保障了业务的稳定。
4、调度部署策略配置
在线业务的核心诉求是稳定,平台侧应该尽量减少单节点、单实例故障对业务的影响,让业务能够无感知地容忍部分异常和失败,同时需要减少不同业务之间的相互影响,所以对调度部署策略来说,也是一个需要着重考虑的点,目前主要从以下方面进行控制:
减少单点故障对业务的影响:将应用进行多副本部署的同时,让各实例优先打散在不同的节点上,技术上可以通过
k8s pod 的反亲和策略来实现;
减少同个节点不同业务的 IO 影响:由于目前 IO 无法做到像 CPU、内存的隔离程度,IO
负载高 (网络或磁盘 IO) 的业务尽量不要部署在同个节点上,可以给业务进行分类, 比如 计算密集型
、 IO 密集型 等类型,通过反亲和优先将不同类型的应用调度到一起,同类型的应用分散;
支持需要独占节点的业务:有些业务的资源诉求大,负载高,无法与别的业务共存,这种情况可以通过节点的
label 和 taint 机制,给业务划分单独的一批节点进行隔离部署,保障业务稳定。
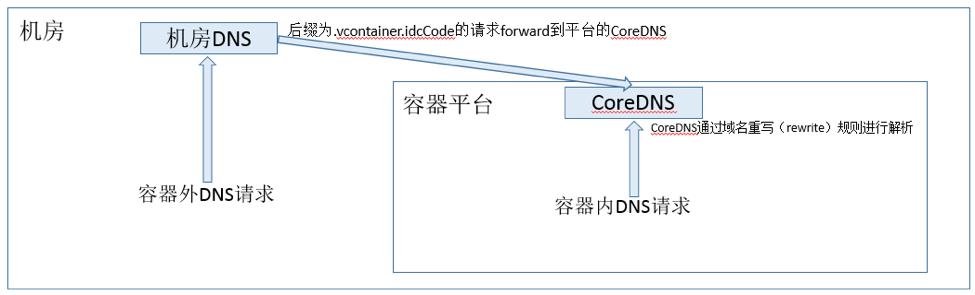
5、机房 dns 打通
有些部署在容器平台的业务,需要有一个在平台内外都能访问的通用域名,方便调试或与其他业务对接,而 k8s
的 service 的域名(格式形如 serviceName.namespace.svc.cluster.local),并不能在
k8s 集群外进行访问,使用起来不方便,所以平台在 coredns 层面配置了域名重写(rewrite)规则,并与公司机房的
dns 进行打通,机房 dns 服务器会将约定后缀(.vcontainer.idcCode)的域名解析请求
forward 到平台的 coredns 进行处理 ,使得采用约定后缀 (格式形如 serviceName.namespace.svc.vcontainer.idcCode
,将原生的后缀 .cluster.local 替换为 .vcontainer.idcCode)格式的域名在
k8s 集群内和集群外都可以访问。
6、资源弹性伸缩
业务对资源的使用有动态伸缩的需求,比如负载高峰时段希望能自动扩容,保障业务稳定,负载低峰时段希望能自动缩容,提高资源利用率,避免资源浪费。
资源的伸缩主要分为两类,水平伸缩(hpa) 和 垂直伸缩(vpa),水平伸缩主要是通过调整部署的副本数来实现,垂直伸缩则是基于容器的申请资源的
request 和 limit 来控制,由于考虑到线上业务的稳定性,业务申请资源时尽量需要保证 request
和 limit 一致,避免同一节点的容器在资源不足时互相挤占资源,造成机器故障(比如内存不足时导致节点
System OOM),所以在弹性伸缩方面,平台重点建设了 hpa 功能。 目前平台已经支持基于 CPU、内存、定时(Cron
表达式)、QPS 等指标对业务实例数的资源进行水平伸缩的功能,并逐步在业务中进行推广。
五、业务容器化的规范
为了保证业务能够平滑顺利地从虚拟机或物理机迁移到容器平台,需要对业务做一些规范约束,防止出现不稳定因素,方便管理维护。

1、统一基础镜像
要求业务使用公司统一的基础镜像,保证业务运行环境的稳定(如 CentOS、JDK、tomcat 版本统一等)。
2、Java 业务的 JDK 版本要求
对于 java 业务,统一使用 jdk1.8.0.192 版本(jdk1.8.0.191 及以上版本),经验证此版本对
docker 容器的支持比较友好,能够正确从系统 cgroup 识别到容器申请的 CPU、内存等信息。某些旧版本的
jdk 欠缺对容器的支持,运行时容易造成问题。
举例子说明,在 jdk7 上跑应用时,业务方根据 Runtime.getRuntime().availableProcessors()
来设置线程池的线程数时,availableProcessors 获取到的是主机的 CPU 核数,而不是容器实际申请的
cpu 核数,会导致业务并发量过大,容器负载过高而出问题。另外 JVM 也会启动过多的 GC 线程,导致
JVM 进程出问题。
3、业务日志规范化
业务日志需要写入到约定的目录,日志内容也需要遵守日志中心规定的 json 格式,保证日志能被正常采集和处理。
4、实例无状态化
部署的实例要求是无状态的,如果有对本地存储依赖,则需要改造为访问分布式存储,才能保证资源调度的安全和灵活,也方便后续弹性伸缩的落地。
5、通过域名访问容器服务
要求通过域名方式访问容器服务,而不能写死 IP 来访问,因为 pod 的 ip 不是固定的。
六、业务落地过程所踩过的坑
在线业务的容器化推进得益于平台和运维同学们的持续投入、专业和严谨,进展比预想顺利,目前依然在稳步推进中。当然,由于容器化部署所涉及的组件、链路环境还是相对复杂,自然也会踩到一些坑,下面例举了部分比较典型的问题:
1、容器的资源 request 和 limit 不一致导致节点 System OOM
容器的资源 request 和 limit 不一致可能会导致一些不稳定因素,比如导致节点 System
OOM,因为当不同业务的 pod 调度到同一个节点上,如果 request 和 limit 不一致,容器在资源不足时会互相挤占资源,造成机器故障(比如所有容器实际使用的内存总和超过机器内存时,会造成
System OOM),所以应该尽量保证线上业务容器的资源 request 和 limit 一致。
2、跨机房延迟
在落地过程中,某些在线业务所依赖的组件(如数据库,缓存等)与容器部署在不同机房,会导致业务请求响应比在原来虚拟机上部署时慢,所以应该尽量将容器业务部署在跟其所依赖的中间件环境的同一个机房内。
3、机器 CPU 性能问题
线上机器型号尽量保持一致,当同个应用的不同实例部署在 CPU 性能差别很大的节点上时,容易导致同个应用的不同实例负载不均衡,影响业务的稳定性。
4、kmem accounting 导致的 memory cgroup 泄漏
kmem accounting 导致的 memory cgroup 泄漏(创建容器时申请,但之后无法释放回收)的问题也是
AI 容器平台的节点经常遇到的问题,网上也有很多分析解决方案,问题的起因跟 kubelet、runc、linux
都有关联,在此不作详述,问题的影响是,会导致容器创建失败,只能通过重启机器解决。AI 容器平台的解决方案是关闭
kubelet、runc 等组件的 kmem accounting 特性,目前从节点灰度的情况来看是有效的。
5、僵尸进程问题
由于 docker 容器中的 1 号进程(如 entrypoint 进程)并不具备管理多进程(子进程)的能力,容器实际上比较适合单进程模式运行,但某些场景下我们又需要将其当成虚拟机来使用,在容器里启多个进程做各种操作,那么就容易造成子进程资源无法回收而形成僵尸进程风险,僵尸进程持续占用着系统资源而无法进行释放,也会造成机器卡死,影响业务调度和运行的稳定性。好在
k8s 为此给 pod 提供了一个 shareProcessNamespace 特性,可以在 pod
内开启共享 PID 名称空间,将 pod 中的 1 号进程变成了 /pause,并在 /pause
进程中实现了对容器内其他进程的管理,从而避免出现僵尸进程。
七、总结展望
由于容器化部署的众多优点,越来越多的公司选择将业务迁移到容器平台之上,vivo AI 容器平台也开始了在线业务容器化落地的实践,相对于离线业务,在线业务对平台的稳定性和资源调度管理有更严格的要求,本文总结了在线业务容器化落地过程中所遇到的问题及解决的思路,后续也将持续进行功能迭代优化,以支持更复杂的业务场景(比如支持有状态的应用的发布,IP
固定的原地发布等),并对离在线混部的技术和策略进行探索,以适应大规模算力资源的调度管控需求。 |








