| 编辑推荐: |
本文主要介绍进行3D目标检测从使用的数据进行划分以及3D目标检测的方法主要是复用2D检测中的一系列方法
,更多详情请阅读下文。
本文来自于CSDN,由火龙果软件Alice编辑、推荐。
|
|
1 简介
目标检测是计算机视觉领域的传统任务,与图像识别不同,目标检测不仅需要识别出图像上存在的物体,给出对应的类别,还需要将该物体的位置通过最小包围框(Bounding
box)的方式给出。根据目标检测需要输出结果的不同,一般将使用RGB图像进行目标检测,输出物体类别和在图像上的最小包围框的方式称为2D目标检测,而将使用RGB图像、RGB-D深度图像和激光点云,输出物体类别及在三维空间中的长宽高、旋转角等信息的检测称为3D目标检测。
随着Faster-RCNN的出现,2D目标检测达到了空前的繁荣,各种新的方法不断涌现,百家争鸣,但是在无人驾驶、机器人、增强现实的应用场景下,普通2D检测并不能提供感知环境所需要的全部信息,2D检测仅能提供目标物体在二维图片中的位置和对应类别的置信度,但是在真实的三维世界中,物体都是有三维形状的,大部分应用都需要有目标物体的长宽高还有偏转角等信息。例如下图Fig.1中,在自动驾驶场景下,需要从图像中提供目标物体三维大小及旋转角度等指标,在鸟瞰投影的信息对于后续自动驾驶场景中的路径规划和控制具有至关重要的作用。


Fig.1 3D object detection in autonomous car, figure
from reference[1]
目前3D目标检测正处于高速发展时期,目前主要是综合利用单目相机、双目相机、多线激光雷达来进行3D目标检测,从目前成本上讲,激光雷达>双目相机>单目相机,从目前的准确率上讲,激光雷达>双目相机>单目相机。但是随着激光雷达的不断产业化发展,成本在不断降低,目前也出现一些使用单目相机加线数较少的激光雷达进行综合使用的技术方案。进行3D目标检测从使用的数据进行划分主要可以分为以下几类:
▍1.1 激光
Voxelnet,Voxelnet把激光点云在空间中均匀划分为不同的voxel,再把不同voxel中的点云通过提出的VFE(Voxel
Feature Encoding)层转换为一个统一的特征表达,最后使用RPN(Region Proposal
Network)对物体进行分类和位置回归,整体流程如图Fig.2所示。


Fig.2 Voxelnet Architecture, figure from reference[2]
▍1.2 单目相机
以开源的Apollo为例,Apollo中使用的YOLO 3D,在Apollo中通过一个多任务网络来进行车道线和场景中目标物体检测。其中的Encoder模块是Yolo的Darknet,在原始Darknet基础上加入了更深的卷积层同时添加反卷积层,捕捉更丰富的图像上下文信息。高分辨多通道特征图,捕捉图像细节,深层低分辨率多通道特征图,编码更多图像上下文信息。和FPN(Feature
Paramid Network)类似的飞线连接,更好的融合了图像的细节和整体信息。Decoder分为两个部分,一部分是语义分割,用于车道线检测,另一部分为物体检测,物体检测部分基于YOLO,同时还会输出物体的方向等3D信息。


Fig.3 Multi-Task YOLO 3D in Apollo,
figure from reference[3]
通过神经网络预测3D障碍物的9维参数难度较大,利用地面平行假设,来降低所需要预测的3D参数。1)假设3D障碍物只沿着垂直地面的坐标轴有旋转,而另外两个方向并未出现旋转,也就是只有yaw偏移角,剩下的Pitch和Roll均为0。障碍物中心高度和相机高度相当,所以可以简化认为障碍物的Z=0;2)可以利用成熟的2D障碍物检测算法,准确预测出图像上2D障碍物框(以像素为单位);3)对3D障碍物里的6维描述,可以选择训练神经网络来预测方差较小的参数。


Fig.4 Predictparameters in Apollo YOLO 3D, figure
from reference[3]
在Apollo中,实现单目摄像头的3D障碍物检测需要两个部分:
1、训练网络,并预测出大部分参数:
图像上2D障碍物框预测
障碍物物理尺寸
不被障碍物在图像上位置所影响,并且通过图像特征可以很好解释的障碍物yaw偏转角
2、通过图像几何学计算出障碍物中心点相对相机坐标系的偏移量X分量和Y分量
▍1.3 激光+单目相机
AVOD,AVOD输入RGB图像及BEV(Bird Eye View),利用FPN网络得到二者全分辨率的特征图,再通过Crop和Resize提取两个特征图对应的区域进行融合,挑选出3D
proposal来进行3D物体检测,整个流程如图Fig.5所示。


Fig.5 AVOD Architecture, figure from reference[4]
在KITTI 3D object Detection的评测结果如下图Fig.6,目前领先的算法主要集中于使用激光数据、或激光和单目融合的方法,纯视觉做3D目标检测的方法目前在准确度上还不能和上述两种方法相提并论,在相关算法上还有很大的成长空间,在工业界有较大的实用性需求,本次分享主要集中在目前比较新的纯视觉单目3D目标检测。
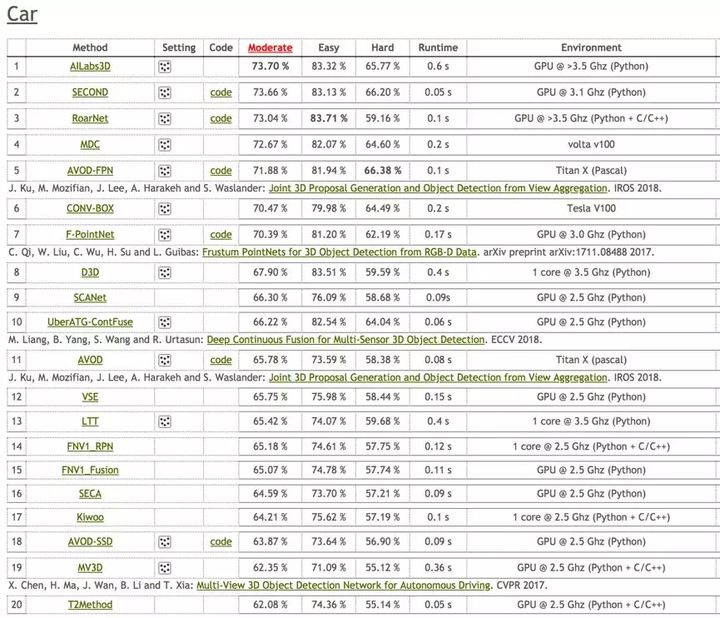

Fig.6 KITTI 3D object detection competition ranking
for car, figure from reference[5]
2 问题和难点
尽管目前对于3D目标检测已经有不少的研究,但是在实际应用中任然有许多的问题,首先,对物体遮挡、截断、周围动态环境的健壮性问题,其次,现有方式大都依赖于物体表面纹理或结构特征,容易造成混淆,最后,在满足准确率要求的条件下,算法效率有很大问题。
3D bounding box是在真实三维世界中包围目标物体的最小长方体,理论上,一个3D
bounding box有9个自由度,3个是位置,3个是旋转,3个是维度大小。对于自动驾驶场景下的物体,绝大多数都是水平放置于地面,所以通过假设物体都放置于水平地面,可以设置滚动和倾斜角度相对于水平面为零,同时底面是水平面的一部分,这样就可以省略掉3个自由度,还有6个自由度,所以3D目标检测也是一个目标物体6D
pose预测问题。
目前,3D目标检测的数据集主要包含Jura、Pascal3D+、LINEMOD、KITTI等,以KITTI数据集为例,如图Fig.7是KITTI数据集中对于一个3D障碍物的标注:


Fig.7 KITTI training data format
3D视觉目标检测的难点主要在于:
1)遮挡,遮挡分为两种情况,目标物体相互遮挡和目标物体被背景遮挡
2)截断,部分物体被图片截断,在图片中只能显示部分物体
3)小目标,相对输入图片大小,目标物体所占像素点极少
4)旋转角度学习,物体的朝向不同,但是对应特征相同,旋转角的有效学习有较大难度,如图Fig.8所示


Fig.8 Rotation angle confusion, figure from reference[4]
5)缺失深度信息,2D图片相对于激光数据存在信息稠密、成本低的优势,但是也存在缺失深度信息的缺点
3 主要方法
目前基于单目相机的3D目标检测的方法主要是复用2D检测中的一系列方法,同时加入多坐标点的回归、旋转角的回归或分类,同时也有采用自编码器的方法来进行姿态学习。
▍3.1 SSD-6D:
Making RGB-Based 3D Detection and 6D Pose Estimation
Great Again


Fig.9 SSD-6D Architecture, figure from reference[6]
SSD-6D的模型结构如上图Fig.9所示,其关键流程介绍如下:
输入为一帧分辨率为299x299的三通道RGB图片
输入数据先经过Inception V4进行特征提取和计算
分别在分辨率为71x71、35x35、17x17、9x9、5x5、3x3的特征图上进行SSD类似的目标值(4+C+V+R)回归,其中目标值包括4(2D包围框)、C(类别分类得分)、V(可能的视点的得分)和R(平面内旋转)
对回归的结果进行非极大抑制(NMS),最终得到结果
关键点:
Viewpoint classification VS pose regression:
作者认为尽管已有论文直接使用角度回归,但是有实验证明对于旋转角的检测,使用分类的方式比直接使用回归更加可靠,特别是使用离散化的viewpoints比网络直接输出精确数值效果更好
Dealing with symmetry and view ambiguity:
给定一个等距采样的球体,对于对称的目标物体,仅沿着一条弧线采样视图,对于半对称物体,则完全省略另一个半球,如图Fig.10所示


Fig.10 discrete viewpoints, figure from reference[6]
效果:


Tab.1 F1-scores for each sequence
of LineMOD, table from reference[6]
▍3.2 3D Bounding Box Estimation Using Deep Learning
and Geometry
作者提出一种从单帧图像中进行3D目标检测和姿态估计的方法,该方法首先使用深度神经网络回归出相对稳定的3D目标的特性,再利用估计出来的3D特征和由2D
bounding box转换为3D bounding box时的几何约束来产生最终的结果。论文中,作者提出了一个严格的假设,即一个3D
bounding box应该严格地被2D bounding box所包围,一个3D bounding
box由中心点的(x, y, z)坐标、和三维尺度(w, h, l)和三个旋转角所表示。要估计全局的物体姿态仅仅通过检测到的2D
bounding box是不可能的,如下图Fig.11所示,尽管汽车的全局姿态一直没有变,但是在2D
bounding box中的姿态一直在变。因此,作者选用回归2D bounding box中的姿态再加上在相机坐标系中汽车角度的变化的综合来进行汽车全局姿态的估计。


Fig.11 Left: Cropped image of car,
Right: Image of whole scene, figure from reference[7]
同时,作者还提出了MultiBin的结构来进行姿态的估计,首先离散化旋转角到N个重叠的Bin,对个每一个Bin,CNN网络估计出姿态角度在当前Bin的概率,同时估计出角度值的Cos和Sin值。网络整体结构如下图Fig.12所示,在公共的特征图后网络有三个分支,分别估计3D物体的长宽高、每个Bin的置信度和每个Bin的角度估计。


Fig.12 MultiBin estimation for orientation and dimension
estimation, figure from reference[7]
效果:


Tab.2.Comparison of the average orientation estimation,
average precision andorientation score for KITTI car,
table from reference[7]


Tab.3. Comparisonof the average
orientation estimation, average precision and orientation
scorefor KITTI cyclist,, table from reference[7]
▍3.3 Implicit 3D Orientation Learning for 6D Object
Detection from RGB Images


Fig.13 Top:codebook from encodings
of discrete object views; Bottom: object detection
and3D orientation estimation with codebook, figure
from reference[8]
作者主要是提出了一种新型的基于去噪自编码器DA(Denoising
Autoencoder)的3D目标朝向估计方法,使用了域随机化(Domain Randomization)在3D模型的模拟视图上进行训练。在进行检测时,首先使用SSD(Single
Shot Multibox Detector)来进行2D物体边界框的回归和分类,然后使用预先训练的深度网络3D目标朝向估计算法对物体的朝向进行估计。在模型的训练期间,没有显示地从3D姿态标注数据中学习物体的6D
pose,而是通过使用域随机化训练一个AAE(Augmented Autoencoder)从生成的3D模型视图中学习物体6D
pose的特征表示。
这种处理方式有以下几个优势:
1.可以有效处理有歧义的物体姿态,尤其是在物体姿态对称时
2.有效学习在不同环境背景、遮挡条件下的物体3D姿态表示
3.AAE不需要真实的姿态标注训练数据


Fig.14 Training process for AAE, figure from reference[8]
效果:


Tab.4 LineMOD object recall with different training
and testing data, table from reference[8]
4 思考
如前所述,纯视觉单目3D目标检测在准确率上离预期还有较大差距,可以考虑引入采用深度神经网络结合稀疏激光点云生成稠密点云对检测结果进行修正
目前大多是采用One-Stage的方法进行3D目标的姿态回归,可以考虑使用Two-Stage的方法来,并利用分割的Mask信息
目前3D目标检测的标注数据较少,可以考虑引入非监督学习
使用更多的几何约束 |








