| БрМЭЦМі: |
БОЮФжївЊЬИвЛЯТЪ§ОнБеЛЗЫљВЩгУЕФЛњЦїбЇЯАММЪѕЃЌЦфЪЕОЭЪЧбЁдёЪВУДбЕСЗЪ§ОнКЭШчКЮЕќДњИќаТФЃаЭЕФВпТдЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкЦћГЕЕчзггыШэМў
ЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
БОЮФЮЊЯЕСаЮФеТЃЌЯЕСаФПТМЃК
ШчКЮДђдьздЖЏМнЪЛЕФЪ§ОнБеЛЗЃПЃЈЩЯЃЉ
ШчКЮДђдьздЖЏМнЪЛЕФЪ§ОнБеЛЗЃПЃЈжаЃЉ
ШчКЮДђдьздЖЏМнЪЛЕФЪ§ОнБеЛЗЃПЃЈЯТЃЉЃЈБОЦЊЮЊЯТЦЊЃЉ
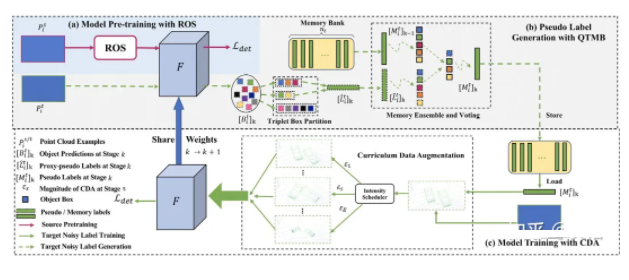
6 ЯрЙиЕФЛњЦїбЇЯАММЪѕ
зюКѓЃЌЬИвЛЯТЪ§ОнБеЛЗЫљВЩгУЕФЛњЦїбЇЯАММЪѕЃЌЦфЪЕОЭЪЧбЁдёЪВУДбЕСЗЪ§ОнКЭШчКЮЕќДњИќаТФЃаЭЕФВпТдЁЃжївЊгавдЯТМИЕуЃК
жїЖЏбЇЯА
OODМьВтКЭCorner CaseМьВт
Ъ§ОндіЧП/ЖдПЙбЇЯА
ЧЈвЦбЇЯА/гђздЪЪгІ
здЖЏЛњЦїбЇЯАЃЈAutoML?ЃЉ/дЊбЇЯАЃЈбЇЯАШчКЮбЇЯАЃЉ
АыМрЖНбЇЯА
здМрЖНбЇЯА
ЩйбљБО/?СубљБОбЇЯА
ГжајбЇЯА/ПЊЗХЪРНч
ЯТУцЗжБ№ЬжТлЃК
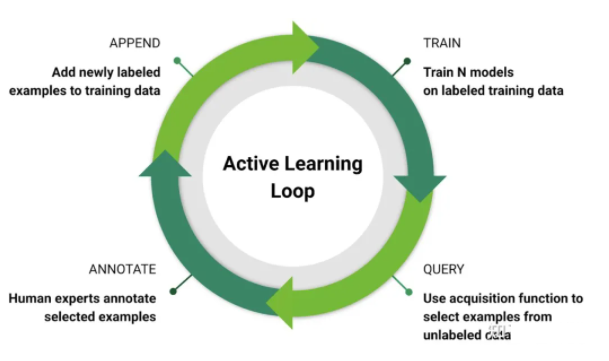
1ЃЉжїЖЏбЇЯА
жїЖЏбЇЯАЃЈ active learning ЃЉЕФФПБъЪЧевЕНгааЇЕФЗНЗЈДгЮоБъМЧЪ§ОнГижабЁдёвЊБъМЧЕФЪ§ОнЃЌзюДѓЯоЖШЕиЬсИпзМШЗадЁЃжїЖЏбЇЯАЭЈГЃЪЧвЛИі ЕќДњ Й§ГЬЃЌдкУПДЮЕќДњжабЇЯАФЃаЭЃЌЪЙгУвЛаЉЦєЗЂЪНЗНЗЈДг ЮДБъМЧ Ъ§ОнГижабЁдёвЛзщЪ§ОнНјааБъМЧЁЃвђДЫЃЌгаБивЊдкУПДЮЕќДњжаЮЊСЫДѓзгМЏВщбЏЫљашБъЧЉЃЌетбљМДЪЙЖдДѓаЁЪЪжаЕФзгМЏЃЌвВЛсВњЩњЯрЙибљБОЁЃ
ШчЭМЪЧвЛИіжїЖЏбЇЯАБеЛЗЪОвтЭМЃКдкЮоБъзЂЪ§ОнжаВщбЏЁЂБъзЂЫљбЁдёЪ§ОнЁЂЬэМгБъзЂЪ§ОнЕНбЕСЗМЏКЭФЃаЭбЕСЗЁЃ
вЛаЉЗНЗЈАбБъзЂКЭЮоБъзЂЪ§ОнЗХдквЛЦ№ЃЌЙЪДЫВЩгУ МрЖНбЇЯА КЭ АыМрЖНбЇЯА НјаабЕСЗЁЃ
БДвЖЫЙжїЖЏбЇЯАЗНЗЈ ЭЈГЃЪЙгУЗЧВЮЪ§ФЃаЭЃЈШчИпЫЙЙ§ГЬЃЉРДЙРМЦУПИіВщбЏЕФдЄЦкНјВНЛђвЛзщВщбЏКѓЕФдЄЦкДэЮѓЁЃ
ЛљгкВЛШЗЖЈаджїЖЏбЇЯАЗНЗЈ ГЂЪдЪЙгУЦєЗЂЪНЗНЗЈЃЌБШШчзюИпьиЃЌКЭОіВпБпНчЕФМИКЮОрРыЕШРДбАевРЇФбР§згЃЈ hard examples ЃЉЁЃ
ШчЭМЪЧгЂЮАДяЛљгкжїЖЏбЇЯАЕФЭкОђЪ§ОнЗНЗЈЃК
ЛЙгаЦфЫћЕФжїЖЏбЇЯАЪЕР§ЗНЗЈЃК
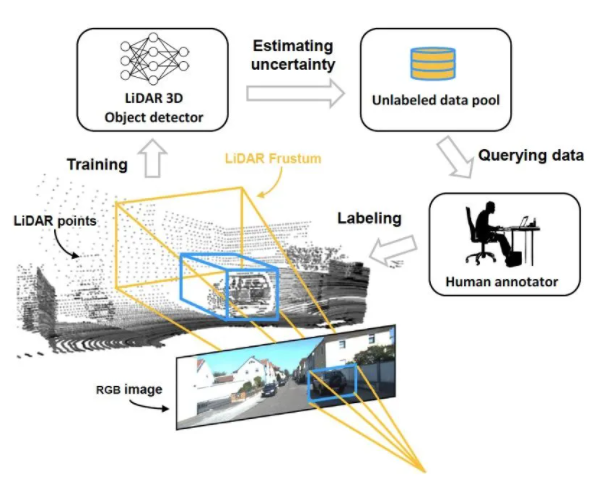
ЁА Deep Active Learning for Efficient Training of a LiDAR 3D Object DetectorЁА
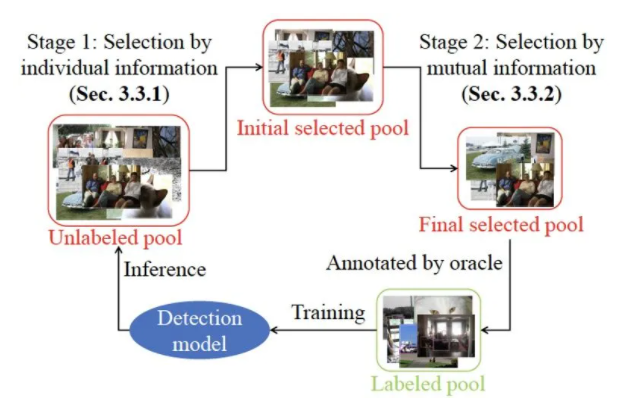
ЁА Consistency-based Active Learning for Object Detection ЁА
2ЃЉOODМьВтКЭCorner CaseМьВт
ЛњЦїбЇЯАФЃаЭЭљЭљЛсдк out-of-distribution ЃЈOOD) Ъ§ОнЩЯЪЇАмЁЃМьВтOODЪЧШЗЖЈВЛШЗЖЈадЃЈ Uncertainty ЃЉЕФЪжЖЮЃЌМШПЩвдАВШЋБЈОЏЃЌвВПЩвдЗЂЯжгаМлжЕЕФЪ§ОнбљБОЁЃ
ВЛШЗЖЈадгаСНжжРДдДЃКШЮвтЃЈ aleatoric ЃЉВЛШЗЖЈадКЭШЯжЊЃЈ epistemic ЃЉВЛШЗЖЈадЁЃ
ЕМжТдЄВтВЛШЗЖЈадЕФЪ§ОнВЛПЩМѕЃЈIrreducibleЃЉВЛШЗЖЈадЃЌЪЧвЛжжШЮвтВЛШЗЖЈадЃЈвВГЦЮЊ Ъ§ОнВЛШЗЖЈад ЃЉЁЃШЮвтВЛШЗЖЈадгаСНжжРраЭЃКЭЌЗНВюЃЈhomo-scedasticЃЉКЭвьЗНВюЃЈhetero-scedasticЃЉЁЃ
СэвЛРрВЛШЗЖЈадЪЧгЩгкжЊЪЖКЭЪ§ОнВЛЪЪЕБдьГЩЕФШЯжЊВЛШЗЖЈадЃЈвВГЦЮЊ жЊЪЖ/ФЃаЭВЛШЗЖЈад ЃЉЁЃ
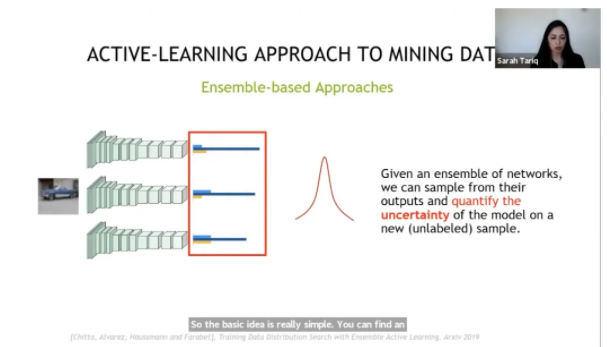
зюГЃгУЕФВЛШЗЖЈадЙРМЦЗНЗЈЪЧБДвЖЫЙНќЫЦЃЈ Bayesian approximation ЃЉЗЈКЭМЏГЩбЇЯАЃЈ ensemble learning ЃЉЗЈЁЃ
вЛРр OOD ЪЖБ№ЗНЗЈЛљгк БДвЖЫЙЩёОЭјТчЭЦРэ ЃЌАќРЈЛљгк dropout ЕФБфЗжЭЦРэЃЈvariational inferenceЃЉЁЂТэЖћПЩЗђСДУЩЬиПЈТо (MCMC) КЭУЩЬиПЈТо dropoutЕШЁЃ
СэвЛРрOODЪЖБ№ЗНЗЈАќРЈ (1) ИЈжњЫ№ЪЇЛђNN МмЙЙаоИФЕШбЕСЗЗНЗЈЃЌвдМА (2) ЪТКѓЭГМЦЃЈpost hoc statisticsЃЉЗНЗЈЁЃ
Ъ§ОнбљБОжагаЦЋРые§ГЃЕФвтЭтЧщПіЃЌМДЫљЮНЕФ corner case ЁЃПЩППЕиМьВтДЫРрcorner caseЃЌдкПЊЗЂЙ§ГЬжаЃЌдкЯпКЭРыЯпгІгУЖМЪЧБивЊЕФЁЃ
дкЯпгІгУПЩвдгУзїАВШЋМрПиКЭОЏИцЯЕЭГЃЌдкcorner caseЧщПіЗЂЩњЪБНјааЪЖБ№ЁЃРыЯпгІгУНЋcorner caseМьВтЦїгІгУгкДѓСПЪеМЏЕФЪ§ОнЃЌбЁдёКЯЪЪЕФбЕСЗКЭЯрЙиВтЪдЪ§ОнЁЃ
зюНќЕФвЛаЉЪЕР§ЙЄзїгаЃК
ЁАTowards Corner Case Detection for Autonomous DrivingЁА
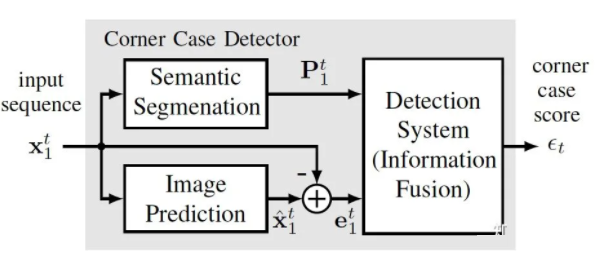
ЁА Out-of-Distribution Detection for Automotive Perception ЁА

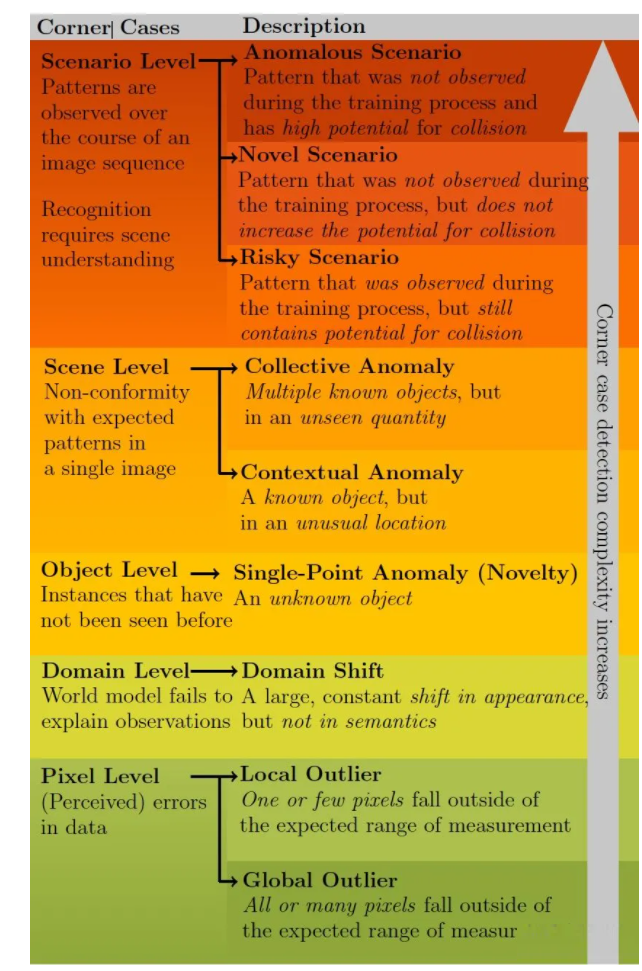
ЁА Corner Cases for Visual Perception in Automated Driving: Some Guidance on Detection Approaches ЁА
3ЃЉЪ§ОндіЧП/ЖдПЙбЇЯА
Й§ФтКЯЃЈ Overfitting ЃЉЪЧжИЕБЛњЦїбЇЯАФЃаЭбЇЯАИпЗНВюЕФКЏЪ§ЭъУРЕиЖдбЕСЗЪ§ОнНЈФЃЪБГіЯжЕФЯжЯѓЁЃЪ§ОндіЧПЃЈ Data Augmentation ЃЉдіЧПбЕСЗЪ§ОнМЏЕФДѓаЁКЭжЪСПЃЌПЫЗўЙ§ФтКЯЃЌДгЖјЙЙНЈИќКУЕФЛњЦїбЇЯАФЃаЭЁЃ
ЭМЯёЪ§ОндіЧПЫуЗЈАќРЈМИКЮБфЛЛЁЂЩЋВЪПеМфдіЧПЁЂФкКЫЙ§ТЫЦїЁЂЛьКЯЭМЯёЁЂЫцЛњВСГ§ЁЂЬиеїПеМфдіЧПЁЂЖдПЙбЕСЗЃЈ adversarial training ЃЉЁЂЩњГЩЖдПЙЭјТчЃЈ generative adversarial networksЃЌGAN ЃЉЁЂЩёОЗчИёЧЈвЦЃЈ neural style transfer ЃЉКЭдЊбЇЯАЃЈ meta-learning ЃЉЁЃ
МЄЙтРзДяЕудЦЪ§ОнЕФдіЧПЗНЗЈЛЙгаЬиБ№ЕФвЛаЉЃКШЋОжБфЛЛЃЈа§зЊЁЂЦНвЦЁЂГпЖШЛЏЃЉЁЂОжВПБфЛЛЃЈа§зЊЁЂЦНвЦЁЂГпЖШЛЏЃЉКЭ3-DТЫВЈЁЃ
ЖдПЙадбЕСЗПЩвдГЩЮЊбАевдіЧПЗНЯђЕФгааЇЗНЗЈЁЃЭЈЙ§ЯожЦЖдПЙЭјТчЃЈ adversarial networkЃЉ ПЩгУЕФдіЧПКЭЛћБфБфЛЛМЏЃЌЭЈЙ§бЇЯАЕУЕНЕМжТДэЮѓЕФдіЧПЗНЪНЁЃетаЉдіЧПЖдгкМгЧПЛњЦїбЇЯАФЃаЭжаЕФШѕЕуКмгаМлжЕЁЃ
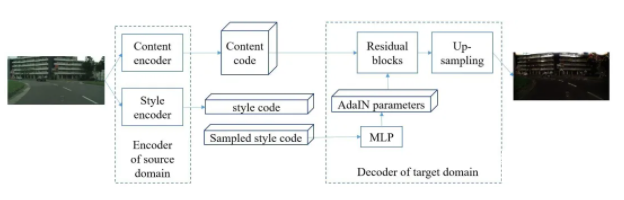
жЕЕУвЛЬсЕФЪЧЃЌ CycleGAN в§ШыСЫвЛИіЖюЭтЕФ Cycle-Consistency Ы№ЪЇКЏЪ§ЃЌЮШЖЈ GAN бЕСЗЃЌгІгУгкЭМЯёЕНЭМЯёзЊЛЛЃЈ image-to-image translation ЃЉЁЃЪЕМЪЩЯCycleGAN бЇЯАДгвЛИіЭМЯёгђзЊЛЛЕНСэвЛИігђЁЃ
ЛњЦїбЇЯАФЃаЭДэЮѓБГКѓЕФвЛИіГЃМћдвђЪЧвЛжжГЦЮЊЪ§ОнМЏЦЋВюЛђгђЦЏвЦЃЈ dataset bias / domain shift ЃЉЕФЯжЯѓЁЃгђЪЪгІЗНЗЈЪдЭММѕЧсгђЦЏвЦЕФгаКІзїгУЁЃЖдПЙбЕСЗЗНЗЈв§ШыЕНгђЪЪгІЃЌБШШчЖдПЙМјБ№гђЪЪгІЗНЗЈ( Adversarial Discriminative Domain Adaptation ЃЌADDA)ЁЃ
зюНќГіЯжЕФвЛаЉаТЪЕР§ЗНЗЈЃК
ЁА AutoAugment: Learning Augmentation Strategies from Data ЁА
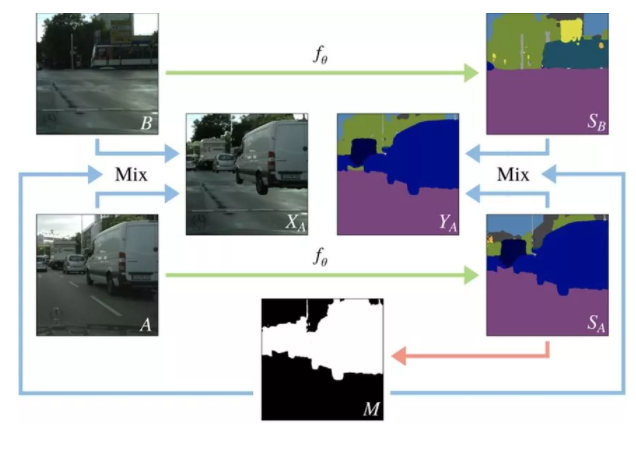
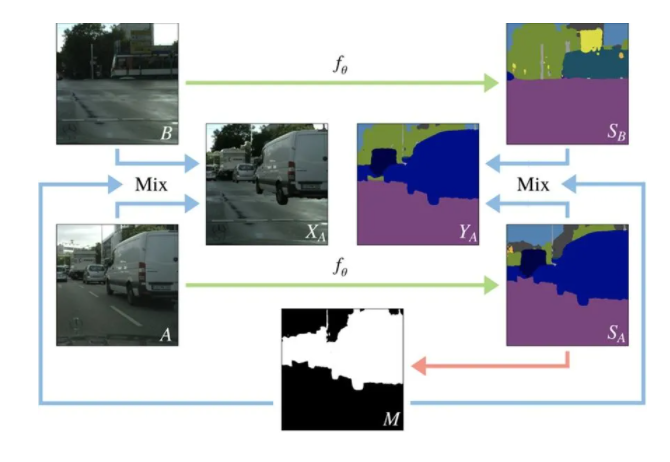
ЁА Classmix: Segmentation-based Data Augmentation For Semi-supervised Learning ЁА
ЁА Data Augmentation for Object Detection via Differentiable Neural Rendering ЁА
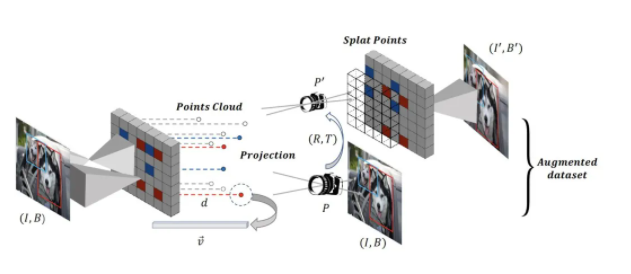
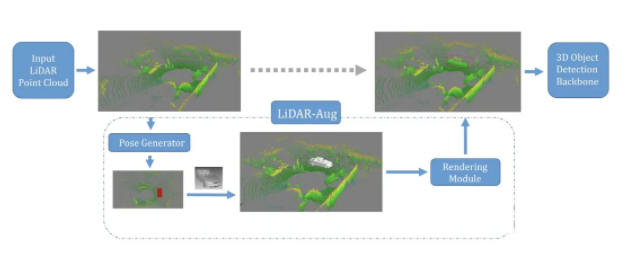
ЁА LiDAR-Aug: A General Rendering-based Augmentation Framework for 3D Object Detection ЁА
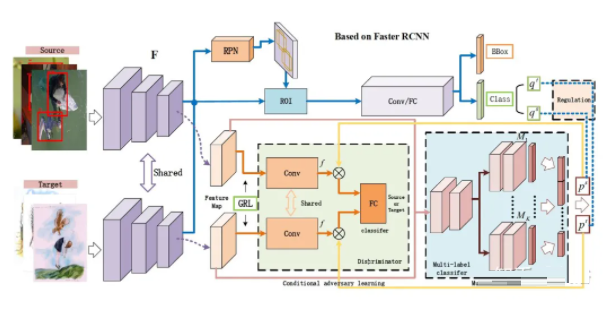
ЁАAdaptive Object Detection with Dual Multi-Label PredictionЁА
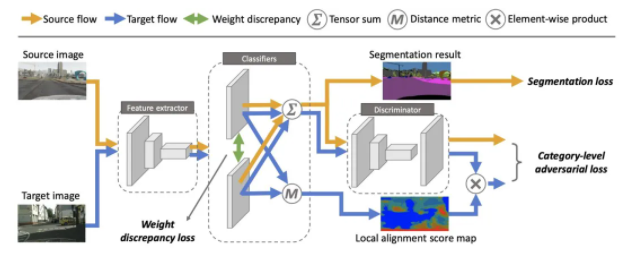
ЁА Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation ЁА
4ЃЉЧЈвЦбЇЯА/гђЪЪгІ
ЧЈвЦбЇЯА( transfer learningЃЌTL )ВЛашвЊбЕСЗЪ§ОнКЭВтЪдЪ§ОнЪЧЖРСЂЭЌЗжВМ( independent and identically distributed ЃЌi.i.d)ЃЌФПБъгђЕФФЃаЭВЛашвЊДгЭЗПЊЪМбЕСЗЃЌПЩвдМѕЩйФПБъгђбЕСЗЪ§ОнКЭЪБМфЕФашЧѓЁЃ
ЩюЖШбЇЯАЕФЧЈвЦММЪѕЛљБОЗжЮЊСНжжРраЭЃЌМДЗЧЖдПЙадЕФЃЈДЋЭГЃЉКЭЖдПЙадЕФЁЃ
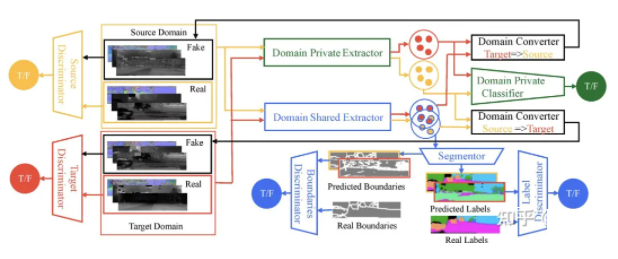
гђЪЪгІ ( domain adaptation ЃЌDA) ЪЧTLЕФвЛжжЬиЪтЧщПіЃЌРћгУвЛИіЛђЖрИіЯрЙидДгђЃЈsource domainsЃЉЕФБъМЧЪ§ОндкФПБъгђЃЈtarget domainЃЉжДаааТШЮЮёЁЃ
DAЗНЗЈЗжЮЊСНРрЃКЛљгкЪЕР§ЕФКЭЛљгкЬиеїЕФЁЃ
зюНќГіЯжЕФвЛаЉаТЪЕР§ЗНЗЈЃК
ЁА Multi-Target Domain Adaptation via Unsupervised Domain Classification for Weather Invariant Object Detection ЁА
ЁА Uncertainty-Aware Consistency Regularization for Cross-Domain Semantic Segmentation ЁА

ЁАSF-UDA3D: Source-Free Unsupervised Domain Adaptation for LiDAR-Based 3D Object Detection ЁА
ЁАLiDARNet: A Boundary-Aware Domain Adaptation Model for Point Cloud Semantic SegmentationЁА
5ЃЉздЖЏЛњЦїбЇЯАЃЈAutoMLЃЉ/дЊбЇЯАЃЈбЇЯАШчКЮбЇЯАЃЉ
вЛИіЛњЦїбЇЯАНЈФЃЕФЙЄГЬЛЙгаМИИіЗНУцашвЊШЫЙЄИЩдЄКЭПЩНтЪЭадЃЌМДЛњЦїбЇЯАТфЕиСїЫЎЯпЕФСНИіжївЊзщМўЃКдЄ-НЈФЃКЭКѓ-НЈФЃЃЈШчЭМЃЉЁЃ
дЄ-НЈФЃ гАЯьЫуЗЈбЁдёКЭГЌВЮЪ§гХЛЏЙ§ГЬЕФНсЙћЁЃдЄ-НЈФЃВНжшАќРЈЖрИіВНжшЃЌАќРЈЪ§ОнРэНтЁЂЪ§ОнзМБИКЭЪ§ОнбщжЄЁЃ
Кѓ-НЈФЃ ФЃПщКИЧСЫЦфЫћживЊЗНУцЃЌАќРЈЛњЦїбЇЯАФЃаЭЕФЙмРэКЭВПЪ№ЁЃ
ЮЊСЫНЕЕЭетаЉЗБжиЕФПЊЗЂГЩБОЃЌГіЯжСЫздЖЏЛЏећИіЛњЦїбЇЯАСїЫЎЯпЕФаТИХФюЃЌМДПЊЗЂздЖЏЛњЦїбЇЯАЃЈ automated machine learning ЃЌ AutoML ) ЗНЗЈЁЃAutoML жМдкМѕЩйЖдЪ§ОнПЦбЇМвЕФашЧѓЃЌВЂЪЙСьгђзЈМвФмЙЛздЖЏЙЙНЈЛњЦїбЇЯАгІгУГЬађЃЌЖјЮоашЬЋЖрЭГМЦКЭЛњЦїбЇЯАжЊЪЖЁЃ
жЕЕУЬиБ№вЛЬсЕФЪЧЙШИшЗНЗЈЁАЩёОМмЙЙЫбЫїЁБЃЈ Neural Architecture Search ЃЌ NAS ЃЉЃЌЦфФПБъЪЧЭЈЙ§дкдЄЖЈвхЫбЫїПеМфжабЁдёКЭзщКЯВЛЭЌЕФЛљБОзщМўРДЩњГЩЮШНЁЧвадФмСМКУЕФЩёОЭјТчМмЙЙЁЃ
NASЕФзмНсДгСНИіНЧЖШСЫНтЃКФЃаЭНсЙЙРраЭКЭВЩгУГЌВЮЪ§гХЛЏЃЈ hyperparameter optimizationЃЌHPO ЃЉЕФФЃаЭНсЙЙЩшМЦЁЃзюЙуЗКЪЙгУЕФ HPO ЗНЗЈРћгУЧПЛЏбЇЯА (RL)ЁЂЛљгкНјЛЏЕФЫуЗЈ (EA)ЁЂЬнЖШЯТНЕ (GD) КЭБДвЖЫЙгХЛЏ (BO)ЗНЗЈЁЃ
ШчЭМЪЧAutoMLдкЛњЦїбЇЯАЦНЬЈЕФгІгУЪЕР§ЃК
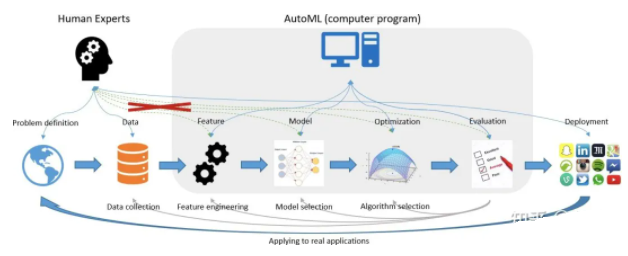
зЂЃКдкЙШИшдЦЁЂЮЂШэдЦAzureКЭбЧТэбЗдЦAWSЖМжЇГжAutoMLЁЃ
ЩюЖШбЇЯАЃЈDLЃЉзЈзЂгкбљБОФкдЄВтЃЌдЊбЇЯАЃЈ meta learning ЃЉЙизЂбљБОЭтдЄВтЕФФЃаЭЪЪгІЮЪЬтЁЃдЊбЇЯАзїЮЊИНМгдкдЪМ DL ФЃаЭЕФЗКЛЏВПЗжЁЃ
дЊбЇЯАбАЧѓФЃаЭЪЪгІгыбЕСЗШЮЮёДѓВЛЯрЭЌЕФЮДМћЙ§ЕФШЮЮёЃЈunseen tasksЃЉЁЃдЊЧПЛЏбЇЯА (meta-RL) ПМТЧДњРэгыВЛЖЯБфЛЏЕФЛЗОГжЎМфЕФНЛЛЅЙ§ГЬЁЃдЊФЃЗТбЇЯА (Meta-IL) НЋЙ§ШЅРрЫЦЕФОбщгІгУгкжЛгаЯЁЪшНБРјЕФаТШЮЮёЁЃ
дЊбЇЯАгы AutoML УмЧаЯрЙиЃЌЖўепгаЯрЭЌЕФбаОПФПБъЃЌМДбЇЯАЙЄОпКЭбЇЯАЮЪЬтЁЃЯжгаЕФдЊбЇЯАММЪѕИљОндк AutoML ЕФгІгУПЩЗжЮЊШ§РрЃК
1ЃЉгУгкХфжУЦРЙРЃЈЖдгкЦРЙРепЃЉЃЛ
2ЃЉгУгкХфжУЩњГЩЃЈгУгкгХЛЏЦїЃЉЃЛ
3) гУгкЖЏЬЌХфжУЕФздЪЪгІЁЃ
дЊбЇЯАДйНјХфжУЩњГЩЃЌР§ШчЃЌеыЖдЬиЖЈбЇЯАЮЪЬтЕФХфжУЁЂЩњГЩЛђбЁдёХфжУВпТдЛђЯИЛЏЫбЫїПеМфЁЃдЊбЇЯАМьВтИХФюЦЏвЦЃЈconcept driftЃЉВЂЖЏЬЌЕїећбЇЯАЙЄОпЪЕЯжздЖЏЛЏЛњЦїбЇЯАЃЈAutoMLЃЉЙ§ГЬЁЃ
6ЃЉАыМрЖНбЇЯА
АыМрЖНбЇЯАЃЈ semi-supervised learning ЃЉЪЧРћгУ ЮДБъМЧЪ§Он ЩњГЩОпгаПЩбЕСЗФЃаЭВЮЪ§ЕФдЄВтКЏЪ§ЃЌФПБъЪЧБШгУБъМЧЪ§ОнЛёЕУЕФдЄВтКЏЪ§ИќзМШЗЁЃгЩгкЛьКЯМрЖНКЭЮоМрЖНЗНЗЈЃЌАыМрЖНбЇЯАЕФЫ№ЪЇКЏЪ§ПЩвдОпгаЖржжаЮзДЁЃвЛжжГЃМћЕФЗНЗЈЪЧЬэМгвЛИіМрЖНбЇЯАЕФЫ№ЪЇЯюКЭвЛИіЮоМрЖНбЇЯАЕФЫ№ЪЇЯюЁЃ
вбОгавЛаЉОЕфЕФАыМрЖНбЇЯАЗНЗЈЃК
ЁАPseudo-label: The simple and efficient semi-supervised learning method for deep neural networksЁБ
ЁАMean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning resultsЁА
ЁАSelf-training with Noisy Student improves ImageNet classificationЁА
зюНќГіЯжвЛаЉаТЪЕР§ЗНЗЈЃК
ЁА Unbiased Teacher for Semi-Supervised Object Detection ЁА
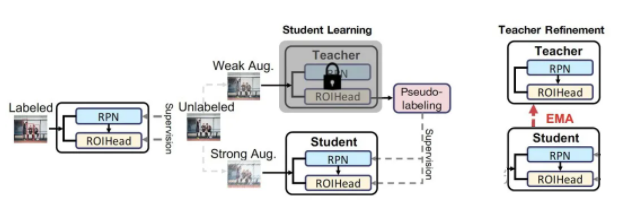
ЁА Pseudoseg: Designing Pseudo Labels For Semantic Segmentation ЁА
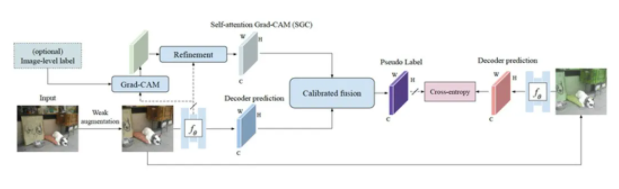
ЁА Semantic Segmentation of 3D LiDAR Data in Dynamic Scene Using Semi-supervised Learning ЁА

ЁАST3D: Self-training for Unsupervised Domain Adaptation on 3D Object DetectionЁА
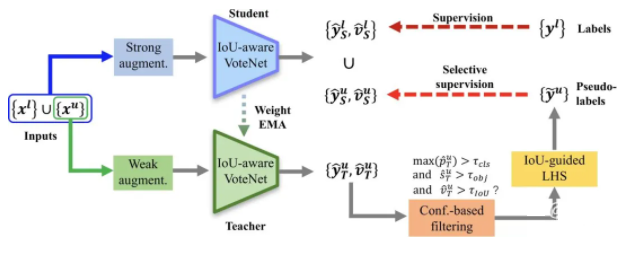
ЁА 3DIoUMatch: Leveraging IoU Prediction for Semi-Supervised 3D Object Detection ЁА
7ЃЉздМрЖНбЇЯА
здМрЖНбЇЯАЃЈ self supervised learning ЃЉЫуЪЧЮоМрЖНбЇЯАЕФвЛИіЗжжЇЃЌЦфФПЕФЪЧЛжИДЃЌЖјВЛЪЧЗЂЯжЁЃздМрЖНбЇЯАЛљБОЗжЮЊЃКЩњГЩЃЈ generative ЃЉРр, ЖдБШЃЈ contrastive ЃЉРрКЭЩњГЩ-ЖдБШЃЈgenerative-contrastiveЃЉЛьКЯРрЃЌМДЖдПЙЃЈ adversarial ЃЉРрЁЃ
здМрЖНЪЙгУНшПкШЮЮёЃЈ pretext task ЃЉРДбЇЯАЮДБъМЧЪ§ОнЕФБэЪОЁЃНшПкШЮЮёЪЧЮоМрЖНЕФЃЌЕЋбЇЯАЕФБэЪОЭЈГЃВЛФмжБНгИјЯТгЮШЮЮёЃЈ downstream task ЃЉЃЌБиаыНјааЮЂЕїЁЃвђДЫЃЌздМрЖНбЇЯАПЩвдБЛНтЪЭЮЊвЛжжЮоМрЖНЁЂАыМрЖНЛђздЖЈвхВпТдЁЃЯТгЮШЮЮёЕФадФмгУгкЦРЙРбЇЯАЬиеїЕФжЪСПЁЃ
вЛаЉжјУћЕФздМрЖНбЇЯАЗНЗЈгаЃК
ЁА SimCLR-A Simple framework for contrastive learning of visual representationsЁА
ЁАMomentum Contrast for Unsupervised Visual Representation LearningЁА
ЁАBootstrap Your Own Latent: A New Approach to Self-Supervised LearningЁА
ЁАDeep Clustering for Unsupervised Learning of Visual FeaturesЁА
ЁАUnsupervised Learning of Visual Features by Contrasting Cluster Assignments ЁА
зЂвтзюНќЕФвЛаЉаТЗНЗЈЃК
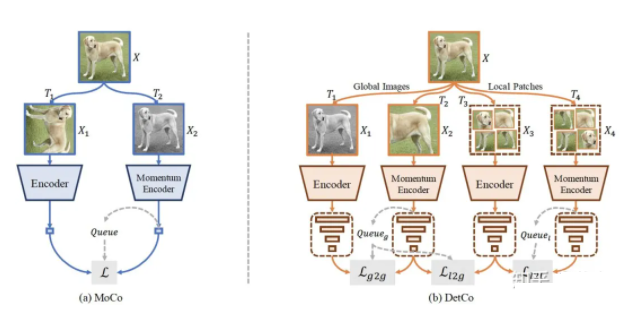
ЁА DetCo: Unsupervised Contrastive Learning for Object Detection ЁА
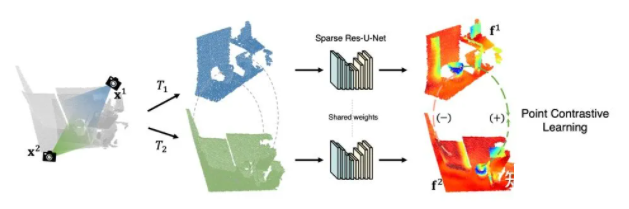
ЁА PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding ЁА
ЁА MonoRUn: Monocular 3D Object Detection by Reconstruction and Uncertainty Propagation ЁА
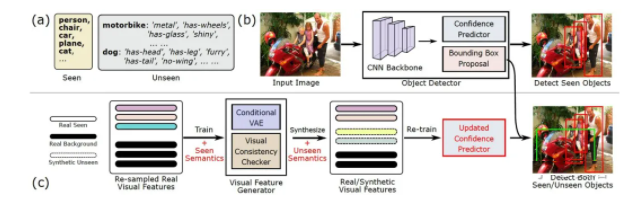
ЁА Weakly Supervised Semantic Point Cloud Segmentation: Towards 10x Fewer Labels ЁА

8ЃЉЩйбљБО/СубљБОбЇЯА
СубљБОбЇЯАЃЈ Zero-shot learning ЃЌZSLЃЉжМдкЪЖБ№дкбЕСЗЦкМфПЩФмЮДМћЙ§ЪЕР§ЕФФПБъЁЃЫфШЛДѓЖрЪ§ZSLЗНЗЈЖМЪЙгУХаБ№адЫ№ЪЇЃЈdiscriminative lossesЃЉНјаабЇЯАЃЌЕЋЩйЪ§ЩњГЩФЃаЭЃЈgenerative modelsЃЉНЋУПИіРрБ№БэЪОЮЊИХТЪЗжВМЁЃ
Ждгк ЮДМћРрЃЈunseen classesЃЉ ЃЌZSLГ§СЫЮоЗЈЗУЮЪЦфЪгОѕЛђИЈжњаХЯЂЕФinductiveЩшжУжЎЭтЃЌtransductiveЗНЗЈЮоашЗУЮЪБъЧЉаХЯЂЃЌжБНггУ вбМћРрЃЈseen classesЃЉ КЭЮДМћРрвЛЦ№ЕФЪгОѕЛђгявхаХЯЂЁЃ
ZSLЪєгк ЧЈвЦбЇЯА ЃЈTLЃЉЃЌдДЬиеїПеМфЮЊбЕСЗЪЕР§ЃЌФПБъЬиеїПеМфЮЊВтЪдЪЕР§ЃЌЖўепЬиеїПеМфвЛбљЁЃЕЋЖдгквбМћРрКЭЮДМћРрЃЌБъЧЉПеМфЪЧВЛЭЌЕФЁЃ
ЮЊСЫДггаЯоЕФМрЖНаХЯЂжабЇЯАЃЌвЛИіаТЕФЛњЦїбЇЯАЗНЯђГЦЮЊЩйбљБОбЇЯА ( Few-Shot Learning ЃЌFSL)ЁЃЛљгкШчКЮЪЙгУЯШбщжЊЪЖЃЌFSLПЩЗжЮЊШ§ИіРрЃК1ЃЉгУЪ§ОнЯШбщжЊЪЖРДдіЧПМрЖНОбщЃЌ2ЃЉЭЈЙ§ФЃаЭЯШбщжЊЪЖдМЪјМйЩшПеМфЃЌКЭ3ЃЉгУЫуЗЈЯШбщжЊЪЖИФБфМйЩшПеМфжазюМбВЮЪ§ЕФЫбЫїЗНЪНЁЃ
FSL ПЩвдЪЧ МрЖНбЇЯА ЁЂ АыМрЖНбЇЯА КЭ ЧПЛЏбЇЯА ЃЈRLЃЉЃЌШЁОігкГ§СЫгаЯоЕФМрЖНаХЯЂжЎЭтЛЙгаФФаЉЪ§ОнПЩгУЁЃаэЖр FSL ЗНЗЈЪЧ дЊбЇЯА ЃЈmeta learningЃЉЗНЗЈЃЌвдДЫзїЮЊЯШбщжЊЪЖЁЃ
зюНќЕФвЛаЉЪЕР§ЗНЗЈЃК
ЁАDon't Even Look Once: Synthesizing Features for Zero-Shot DetectionЁА
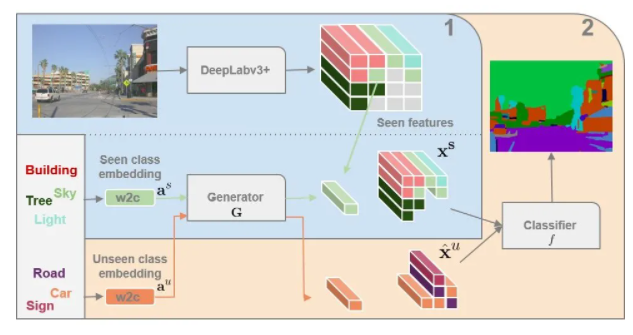
ЁАZero-Shot Semantic SegmentationЁА
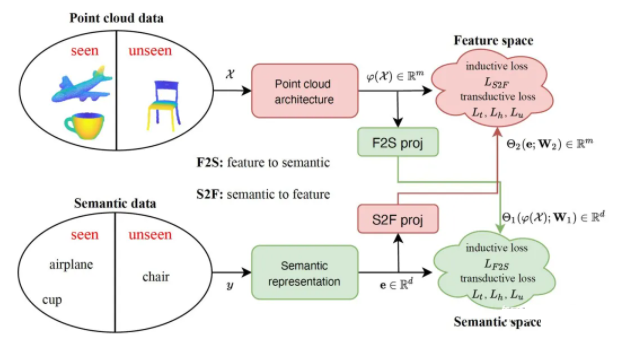
ЁАZero-Shot Learning on 3D Point Cloud Objects and BeyondЁА
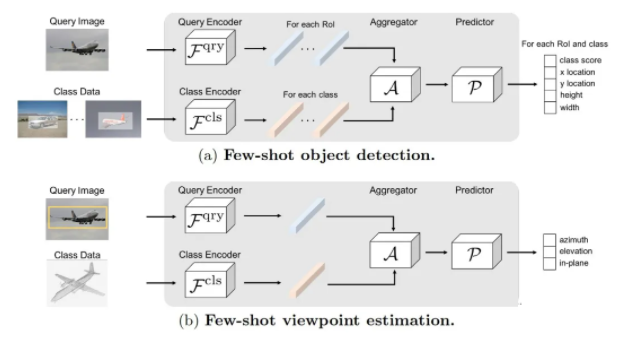
ЁА Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild ЁА
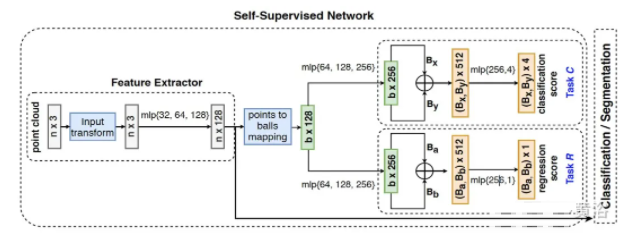
ЁА Self-Supervised Few-Shot Learning on Point Clouds ЁА
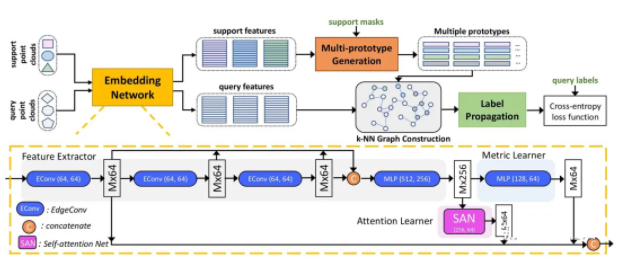
ЁА Few-shot 3D Point Cloud Semantic Segmentation ЁА
9ЃЉГжајбЇЯА/ПЊЗХЪРНч
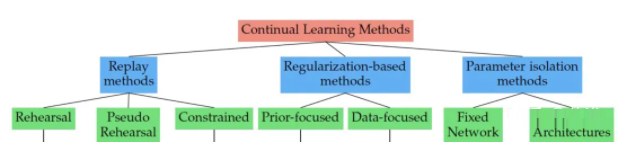
ГжајбЇЯАЃЈ continual learningЃЉПЩвдВЛЖЯЛ§РлВЛЭЌШЮЮёЕУЕНЕФжЊЪЖЃЌЖјЮоашДгЭЗПЊЪМжиаТбЕСЗЁЃЦфРЇФбЪЧШчКЮПЫЗўджФбвХЭќЃЈ catastrophic forgetting ЃЉЁЃ
ШчЭМЪЧГжајбЇЯАЕФЗНЗЈЗжРрЃКОбщжиЗХЃЈERЃЉЁЂе§дђЛЏКЭВЮЪ§ЙТСЂШ§ИіЗНЯђЁЃ
ПЊЗХМЏЪЖБ№ЃЈOpen set recognitionЃЌOSRЃЉЃЌЪЧдкбЕСЗЪБДцдкВЛЭъећЕФЪРНчжЊЪЖЃЌдкВтЪджаПЩвдНЋЮДжЊРрЬсНЛИјЫуЗЈЃЌвЊЧѓЗжРрЦїВЛНівЊзМШЗЕиЖдЫљМћРрНјааЗжРрЃЌЛЙвЊгааЇДІРэЮДМћРрЁЃПЊЗХЪРНчбЇЯАЃЈ Open world learning ЃЉПЩвдПДзїЪЧ ГжајбЇЯА ЕФвЛИізгШЮЮёЁЃ
вдЯТИјГізюНќЕФвЛаЉЪЕР§ЗНЗЈЃК
ЁАLifelong Object DetectionЁА
ЁА Incremental Few-Shot Object Detection ЁА
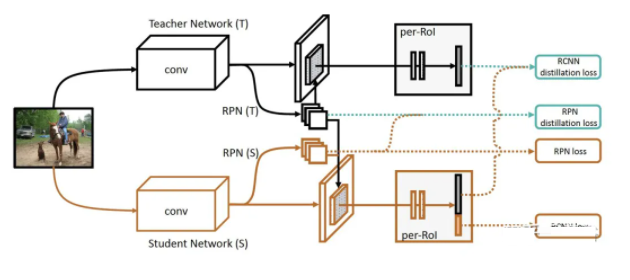
ЁА Towards Open World Object DetectionЁА
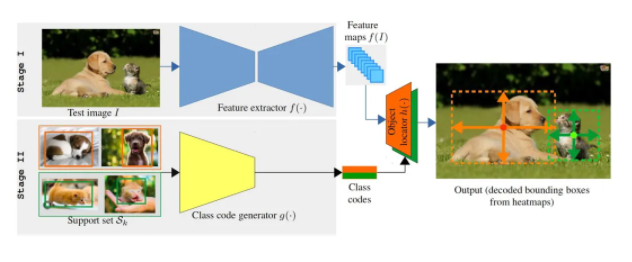
" OpenGAN: Open-Set Recognition via Open Data Generation "
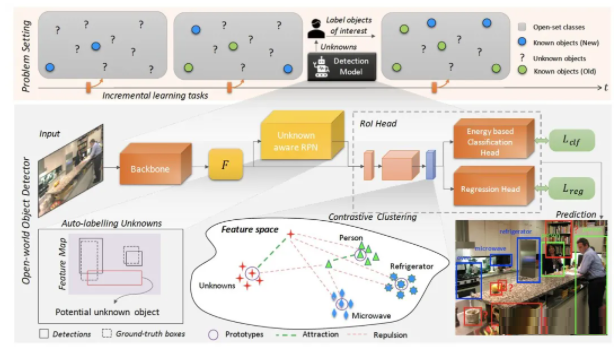
ЁА Large-Scale Long-Tailed Recognition in an Open World ЁА
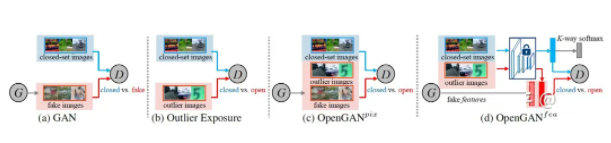
Ъ§ОнБеЛЗЕФЙиМќЪЧЪ§ОнЃЌЭЌЪБВЩгУЪ§ОнЧ§ЖЏЕФбЕСЗФЃаЭЪЧЛљДЁЁЃОіЖЈСЫећИіздЖЏМнЪЛЕќДњЩ§МЖЯЕЭГЕФзпЯђЪЧЃК
Ъ§ОнЕФФЃЪН ЃЈЩуЯёЭЗ/МЄЙтРзДя/РзДяЃЌЮо/ЕМКН/ИпЧхЕиЭМЃЌзЫЬЌЖЈЮЛОЋЖШЃЌЪБМфЭЌВНБъМЧЃЉЃЛ
Ъ§ОнЧ§ЖЏФЃаЭ ЃЈФЃПщ/ЖЫЕНЖЫЃЉЃЛ
ФЃаЭЕФМмЙЙ ЃЈAutoMLЃЉЃЛ
ФЃаЭбЕСЗЕФВпТд ЃЈЪ§ОнбЁдёЃЉЁЃ
|





